







 超级会员免费看
超级会员免费看
大模型微调实战之 Transformer 强化学习(TRL Reinforcement Learning)(五)用 ORPO 将 Llama 3 的性能提升到新高度
尽管最近的语言模型偏好对齐算法展示了有希望的结果,但监督式微调(SFT)对于实现成功的收敛仍然至关重要。在本文中,我们研究了SFT在偏好对齐背景下的关键作用,强调对于不受青睐的生成风格只需轻微的惩罚就足以实现偏好对齐的SFT。基于这一基础,我们引入了一个简单且创新的无需参考模型的单一几率比偏好优化算法,即ORPO,消除了额外偏好对齐阶段的必要性。我们从实证和理论上都证明了,在不同大小的模型(从125M到7B)的SFT中,几率比是对比受青睐和不受青睐风格的明智选择。具体来说,仅使用UltraFeedback对Phi-2(2.7B)、Llama-2(7B)和Mistral(7B)进行ORPO微调,就超过了具有超过7B和13B参数的最先进语言模型的性能
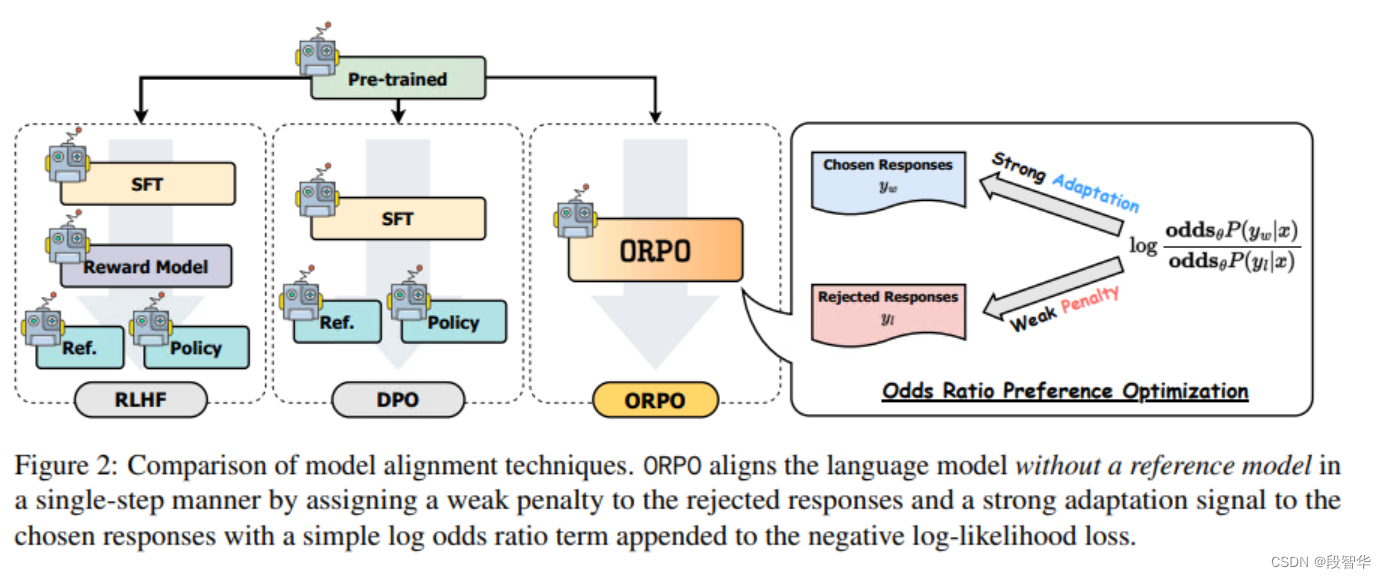
ORPO
论文:ORPO: Monolithic Preference Optimization without Reference Model

https://arxiv.org/p

 订阅专栏 解锁全文
订阅专栏 解锁全文
















 1984
1984











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











