







大数据Spark “蘑菇云”行动第89课:Hive中GroupBy优化、Join的多种类型实战及性能优化、
OrderBy和SortBy、UnionAll等实战和优化
select gender,sum(salary) from employeesforhaving group by gender;
select gender,avg(salary) from employeesforhaving group by gender;
set hive.map.aggr=true; //需要更高的内存,在map端聚合,一般至少64G
select gender,avg(salary) from employeesforhaving group by gender;
select * from employeesforhaving sort by salary;
select * from employeesforhaving sort by salary desc;
//order by和sort by 的区别:全局排序orderby;局部排序 sort by
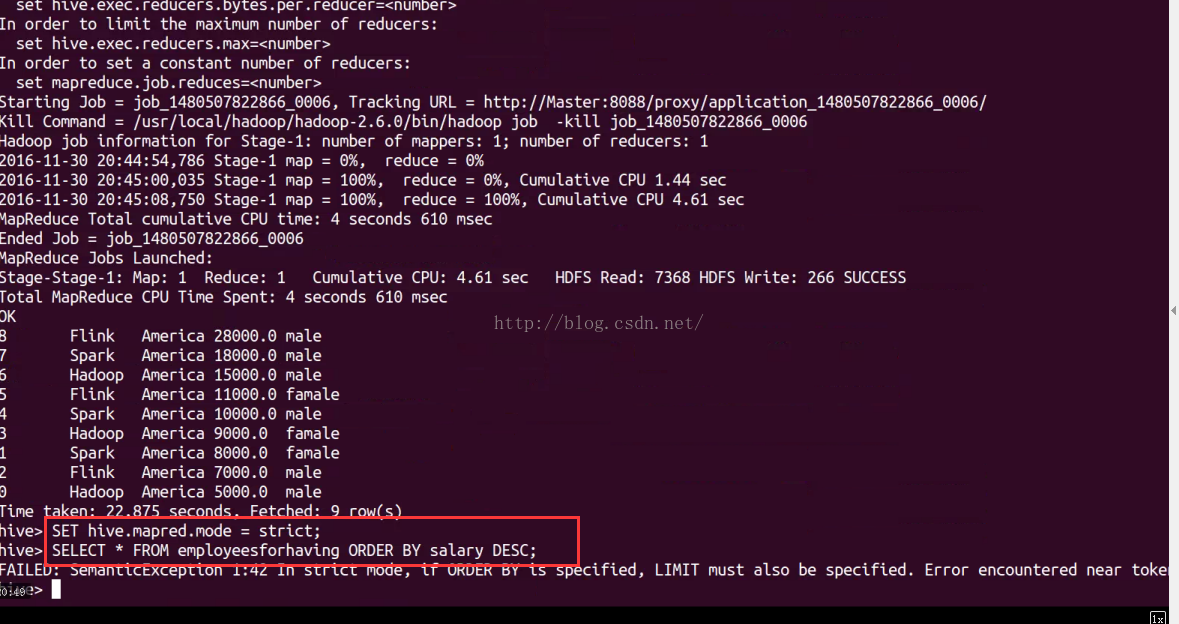
select * from employeesforhaving order by salary;
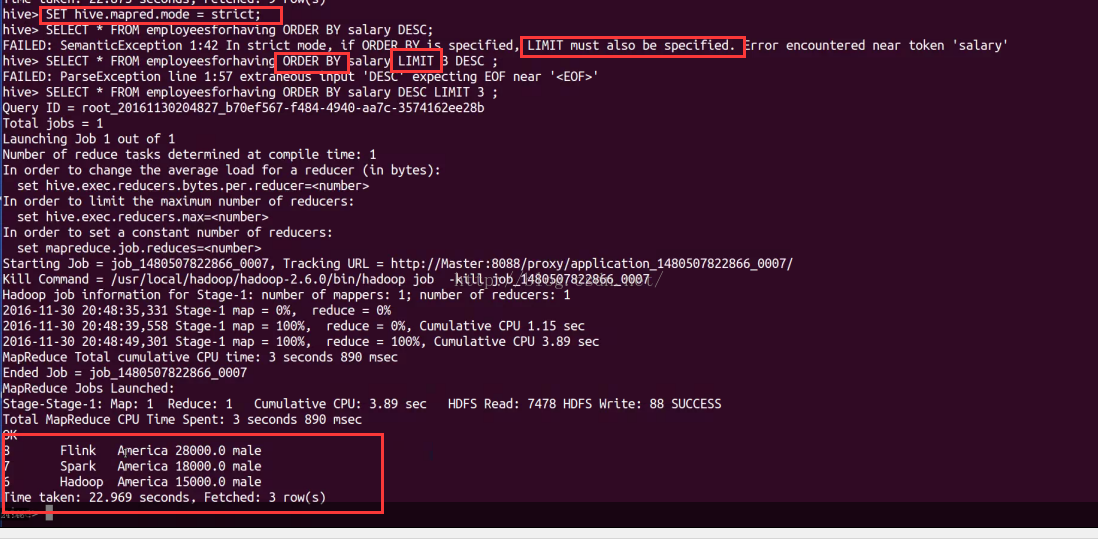
set hive.mapred.mode =strict;
select * from employeesforhaving order by salary; // 全局排序,内存溢出。执行排序过程会
讲所有的结果分发到同一个reducer中
select * from employeesforhaving order by salary limit 3; //ok 只需要增加limit语句就可
以解决这个问题
select count(1) from employeesforhaving
union all
select count(1) from employ; //报错
Hive不支持顶层的Union操作
OrderBy和SortBy、UnionAll等实战和优化
select gender,sum(salary) from employeesforhaving group by gender;
select gender,avg(salary) from employeesforhaving group by gender;
set hive.map.aggr=true; //需要更高的内存,在map端聚合,一般至少64G
select gender,avg(salary) from employeesforhaving group by gender;
select * from employeesforhaving sort by salary;
select * from employeesforhaving sort by salary desc;
//order by和sort by 的区别:全局排序orderby;局部排序 sort by
select * from employeesforhaving order by salary;
set hive.mapred.mode =strict;
select * from employeesforhaving order by salary; // 全局排序,内存溢出。执行排序过程会
讲所有的结果分发到同一个reducer中
select * from employeesforhaving order by salary limit 3; //ok 只需要增加limit语句就可
以解决这个问题
select count(1) from employeesforhaving
union all
select count(1) from employ; //报错
Hive不支持顶层的Union操作
select * from (select count(1) as r1 from employeesforhaving union all select count(1) as r2 from employee where phour='2055') tmp;
SELECT /*+MAP JOIN (a) */ 。。。。。。
今天作业:基于电影评价系统的数据(后面很多案例都直接基于电影评价系统数据),写出正常的Reduce的Join,Map端的Join和Left Semi Join实现




















 3335
3335











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











