







- 服务器启动, 如果没有指定端口则随机选取端口建立套接字监听客户端连接
- accept()会一直阻塞等待客户端连接, 如果客户端连接上, 则创建一个新线程处理该客户端连接.
- 在accetp_request() 主要处理客户端连接, 首先解析HTTP请求报文. 只支持GET/POST请求, 否则返回HTTP501错误. 如果有请求参数的话, 记录在query_string中. 将请求的路径记录在path中, 如果请求的是目录, 则访问该目录下的index.html文件.
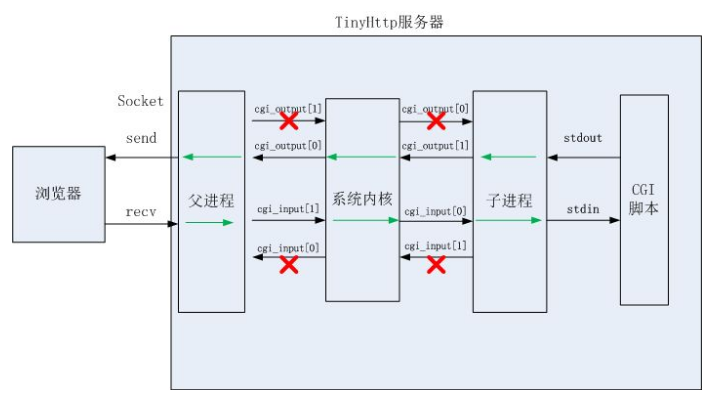
- 最后判断请求类型, 如果是静态请求, 直接读取文件发送给客户端; 如果是动态请求, 则fork()一个子进程, 在子进程中调用exec()函数簇执行cgi脚本. 然后父进程读取子进程执行结果 父子进程之间通过管道通信实现.(针对POST请求,需要fork出一个子进程来处理,然后建立两个管道来与浏览器或者客户端通信,这里需要使用管道而不是子进程直接处理socket的原因是我们的父进程已经读取了一部分内容.)
- 父进程等待子进程结束后, 关闭连接, 完成一次HTTP请求.
源码分析:
main:
程序入口, 这里建立套接字, 然后与sockaddr_in结构体进行绑定, 然后用listen监听该套接字上的连接请求, 这几步都在startup()中实现.
然后服务器在通过accept接受客户端请求, 如没有请求accept()会阻塞, 如果有请求就会创建一个新线程去处理客户端请求.
int main(void)
{
int server_sock = -1;
u_short port = 4000;
int client_sock = -1;
struct sockaddr_in client_name;
socklen_t client_name_len = sizeof(client_name);
pthread_t newthread;
//在对应端口建立httpd服务
server_sock = startup(&port);
printf("httpd running on port %d\n", port);
while (1)
{
//套接字收到客户端连接请求
client_sock = accept(server_sock,
(struct sockaddr *)&client_name,
&client_name_len);
if (client_sock == -1)
error_die("accept");
//派生新线程用accept_request函数处理新请求
accept_request(&client_sock);
//if (pthread_create(&newthread , NULL, (void *)accept_request, (void *)(intptr_t)client_sock) != 0)
//perror("pthread_create");
}
close(server_sock);
return(0);
}
accept_request()
主要处理客户端请求, 做出了基本的错误处理. 主要功能判断是静态请求还是动态请求, 静态请求直接读取文件发送给客户端即可, 动态请求则调用execute_cgi()处理. 解析客户端的请求方式,是GET,还是POST,tinyhttpd只能处理这2种请求,如果都不是,就返回错误。然后解析请求的url,然后对应到服务器中tinyhttpd中htdocs目录下的文件,检查文件状态,如果文件不存在,那么返回错误。如果文件存在,是GET方法时,tinyhttpd直接返回此文件,通常是html。如果是POST,那么会执行对应的.cgi文件,tinyhttpd中的CGI文件,是用PERL脚本实现的。
/**********************************************************************/
/* A request has caused a call to accept() on the server port to
* return. Process the request appropriately.
* Parameters: the socket connected to the client */
/**********************************************************************/
void accept_request(void *arg)
{
int client = (intptr_t)arg;
char buf[1024];
size_t numchars;
char method[255];
char url[255];
char path[512];
size_t i, j;
struct stat st;
int cgi = 0; /* becomes true if server decides this is a CGI
* program */
char *query_string = NULL;
//得到请求的第一行
numchars = get_line(client, buf, sizeof(buf));
i = 0; j = 0;
//把客户端的请求方法保存到method中
while (!ISspace(buf[i]) && (i < sizeof(method) - 1))
{
method[i] = buf[i];
i++;
}
j=i;
method[i] = '\0';
//如果既不是GET又不是POST,则无法处理
if (strcasecmp(method, "GET") && strcasecmp(method, "POST"))
{
unimplemented(client);
return;
}
//POST的时候,开启cgi
if (strcasecmp(method, "POST") == 0)
cgi = 1;
//读取url地址
i = 0;
while (ISspace(buf[j]) && (j < numchars))
j++;
while (!ISspace(buf[j]) && (i < sizeof(url) - 1) && (j < numchars))
{
url[i] = buf[j];
i++; j++;
}
url[i] = '\0';
//处理GET方法
if (strcasecmp(method, "GET") == 0)
{
//待处理请求为url
query_string = url;
while ((*query_string != '?') && (*query_string != '\0'))
query_string++;
//GET方法特点,?后面为参数
if (*query_string == '?')
{
//开启cgi
cgi = 1;
*query_string = '\0';
query_string++;
}
}
//格式化url到path数组,html文件都在htdocs中
sprintf(path, "htdocs%s", url);
//默认情况下为index.html
if (path[strlen(path) - 1] == '/')
strcat(path, "index.html");
//根据路径找到对应的文件
if (stat(path, &st) == -1) {
//丢弃多有的headers信息
while ((numchars > 0) && strcmp("\n", buf)) /* read & discard headers */
numchars = get_line(client, buf, sizeof(buf));
//回应客户端找不到
not_found(client);
}
else
{
//如果是目录,默认使用目录下的index.html文件
if ((st.st_mode & S_IFMT) == S_IFDIR)
strcat(path, "/index.html");
if ((st.st_mode & S_IXUSR) ||
(st.st_mode & S_IXGRP) ||
(st.st_mode & S_IXOTH) )
cgi = 1;
//不是cgi,直接把服务器文件返回,否则执行cgi
if (!cgi)
serve_file(client, path);
else
execute_cgi(client, path, method, query_string);
}
//断开与客户端的链接
close(client);
}
面这个函数的功能就是重点了. 思路是这样的 :
通过fork()一个cgi子进程, 然后在子进程中调用exec函数簇执行该请求, 父进程从子进程读取执行后的结果, 然后发送给客户端.
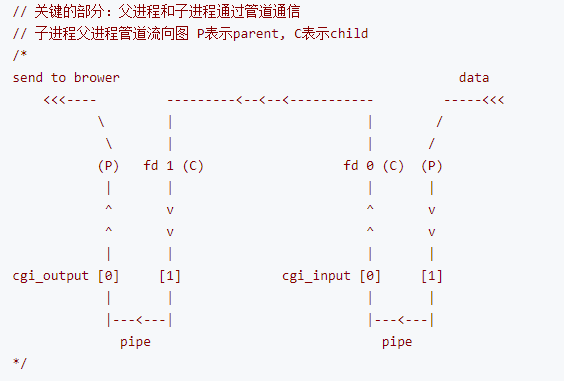
父子进程之间通过无名管道通信, 因为cgi是使用标准输入输出, 要获取标准输入输出, 可以把它们重定向到管道. 把stdin 重定向到 cgi_input管道, stdout重定向到 cgi_outout管道.
在父进程中关闭cgi_input的读端个cgi_output的写端, 在子进程中关闭cgi_input的写端和cgi_output的读端.
数据流向为 : cgi_input[1](父进程) -----> cgi_input[0](子进程)[执行cgi函数] -----> stdin -----> stdout -----> cgi_output[1](子进程) -----> cgi_output[0](父进程)[将结果发送给客户端]
/**********************************************************************/
/* Execute a CGI script. Will need to set environment variables as
* appropriate.
* Parameters: client socket descriptor
* path to the CGI script */
/**********************************************************************/
void execute_cgi(int client, const char *path,
const char *method, const char *query_string)
{
char buf[1024];
int cgi_output[2];
int cgi_input[2];
pid_t pid;
int status;
int i;
char c;
int numchars = 1;
int content_length = -1;
buf[0] = 'A'; buf[1] = '\0';
if (strcasecmp(method, "GET") == 0)
//把所有的HTTP headers读取并丢弃
while ((numchars > 0) && strcmp("\n", buf)) /* read & discard headers */
numchars = get_line(client, buf, sizeof(buf));
else if (strcasecmp(method, "POST") == 0) /*POST*/
{
//对POST的HTTP请求找出conten_length
numchars = get_line(client, buf, sizeof(buf));
while ((numchars > 0) && strcmp("\n", buf))
{
buf[15] = '\0';
if (strcasecmp(buf, "Content-Length:") == 0)
content_length = atoi(&(buf[16]));
numchars = get_line(client, buf, sizeof(buf));
}
//没有找到content_length,错误请求
if (content_length == -1) {
bad_request(client);
return;
}
}
else/*HEAD or other*/
{
}
//建立管道
if (pipe(cgi_output) < 0) {
cannot_execute(client);
return;
}
//建立管道
if (pipe(cgi_input) < 0) {
cannot_execute(client);
return;
}
//fork创建一个进程
if ( (pid = fork()) < 0 ) {
cannot_execute(client);
return;
}
sprintf(buf, "HTTP/1.0 200 OK\r\n");
send(client, buf, strlen(buf), 0);
if (pid == 0) /* child: CGI script */
{
char meth_env[255];
char query_env[255];
char length_env[255];
//把STDOUT重定向到cgi_output的写入端
dup2(cgi_output[1], STDOUT);
//把STDIN重定向到cgi_input的读取端
dup2(cgi_input[0], STDIN);
//关闭cgi_input的写入端,关闭cgi_input的读端
close(cgi_output[0]);
close(cgi_input[1]);
sprintf(meth_env, "REQUEST_METHOD=%s", method);
//请求参数添加到环境变量中,调用execl函数执行path路径下的cgi程序,获得对应的输出
//设置的环境变量对于不同的用户是隔离的
putenv(meth_env);
if (strcasecmp(method, "GET") == 0) {
sprintf(query_env, "QUERY_STRING=%s", query_string);
putenv(query_env);
}
else { /* POST */
sprintf(length_env, "CONTENT_LENGTH=%d", content_length);
putenv(length_env);
}
execl(path, NULL);
exit(0);
} else { /* parent */
close(cgi_output[1]);
close(cgi_input[0]);
if (strcasecmp(method, "POST") == 0)
for (i = 0; i < content_length; i++) {
recv(client, &c, 1, 0);
write(cgi_input[1], &c, 1);
}
while (read(cgi_output[0], &c, 1) > 0)
send(client, &c, 1, 0);
//关闭管道
close(cgi_output[0]);
close(cgi_input[1]);
//等待子进程
waitpid(pid, &status, 0);
}
}程序中使用两个管道的原因:
建立两条管道, 用于父子进程之间通信, cig使用标准输入和输出.
要获取标准输入输出, 可以把stdin重定向到cgi_input管道, 把stdout重定向到cgi_output管道
为什么使用两条管道 ? 一条管道可以看做储存一个信息, 只是一端用来读, 另一端用来写. 我们有标准输入和标准输出两个信息, 所以要两条管道
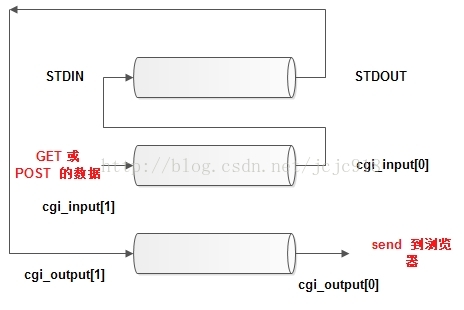
浏览器和服务器交互的整个流程:
管道cgi_input处理标准输入,父进程在该管道的写端写入,子进程在该管道的读端读出;浏览器向服务器输入Post或Get的数据
管道cgi_output处理标准输出,子进程在该管道的写端写入,父进程在该管道的读端读出;服务器向浏览器发送执行CGI文件的运行结果;
参考:
https://zhuanlan.zhihu.com/p/24941375
http://www.chongchonggou.com/g_68516544.html
https://www.cnblogs.com/tanxing/p/6791812.html
https://blog.csdn.net/kristpan/article/details/49449111
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









