







想要读取Hive的数据我们首先要从集群中把需要的xml文件获取下来,分别是core-site.xml、hdfs-site.xml、hive-site.xml,将这三个文件放在项目的resource目录下,spark运行的时候会自动读取
在原本的Spark pom文件中导入spark-hive的包,大家根据自己的scala和spark的版本去选择自己合适的,我用的如下
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.11</artifactId>
<version>2.0.2</version>
</dependency>
这种方法读取时,只是SparkSession的创建有些不一样罢了,其他的操作没什么异样,代码如下
package com.sparksql
import org.apache.spark.sql.SparkSession
object SparkOnHive {
def main(args: Array[String]): Unit = {
//hive的表数据文件在hdfs上的存放地址,如果你的hive-env里面有hive表数据位置就不用配置这一项
val warehouseLocation = "hdfs://hdp2:9000/user/hive/warehouse"
val spark = SparkSession
.builder()
.appName("Spark Hive Example")
.master("local")
.config("spark.sql.warehouse.dir", warehouseLocation)//我的hive配置文件里没写表数据存放地址用的是hive自己默认的路径,所以我要另外修改sparksql-hive的table数据源,指定到hive表数据去
.enableHiveSupport()
.getOrCreate()
import spark.sql
//测试,spark会自动读取配置
sql("CREATE TABLE IF NOT EXISTS src (key INT, value STRING)")
sql("LOAD DATA LOCAL INPATH 'examples/src/main/resources/kv1.txt' INTO TABLE src")
sql("SELECT * FROM src").show()
sql("SELECT avg(age) avgage FROM student").show()
}
}
这里解释一下,Spark操作Hive数据的时候,三个配置文件,如果你没有hive-site.xml,Spark会自动使用内置的hive环境,如果你是在开发工具中直接运行代码,你会发现在项目主路径下会生成hive自带的元数据库,就是那个不支持高并发的基于文件的元数据库。
如果没有另外两个Hadoop的配置文件,而且还没有配置HADOOP_HOME,那么就会报错找不到配置文件之类的,如果此时配置了HADOOP_HOME,则是用你本地的HADOOP测试环境,不过因为本地只是测试跑代码之类的,所以一般也不去本地的HADOOP上配置东西,导致它用的都是默认的配置,
我上面写的代码是Spark融合了Sqlsession和hiveSession产生了SparkSession之后的写法,现在任然有很多人喜欢使用以前的写法,博文开始pom中让大家导入的那个spark-hive的jar中任然支持老旧的写法,我也给大家找了一个旧API的写法
val sparkConf=new SparkConf()
sparkConf.setAppName("SQLContextApp").setMaster("local[2]")
val sc= new SparkContext(sparkConf)
val hiveContext=new HiveContext(sc)
//下面的操作,和SqlSession没差别
hiveContext.table("emp").show
不过这个API,它在2.0.0版本的jar开始就过时了,不建议大家使用
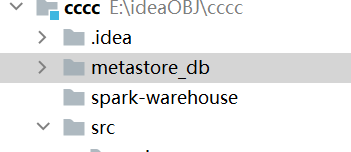
最后给大家看一下,如果你不导入三个配置文件,则会生成如下的路径,一个是hive元数据另一个是spark操作hive时的数据存放路径















 1246
1246











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









