






1.问题阐述
在一个操场的四周摆放着n堆石子。现要将石子有次序地合并成一堆。规定每次至少选2堆,最多选k堆石子合并成新的一堆,合并的费用为新的一堆的石子数。试设计一个算法,计算出将n堆石子合并成一堆的最大总费用和最小总费用。
2. 设计算法
- 数据输入:第1行有2个正整数n和k,表示有n堆石子,每次至少选2堆最多选k堆石子合并。第2行有n个数,分别表示每堆石子的个数。
- 设n mod(k-1)=1,若不满足,可增加若干个0。
- 每次选最小的k个元素进行合并。
- 与二元Huffiman算法类似,可证明其满足贪心选择性质。
3. 实验中出现问题
- 出现了参数超出限制的问题,“IndexError: list index out of range”
4. 解决办法
- 查询资料后参考提示“设n mod(k-1)=1,若不满足,增加若干个0”,使用while语句实现了扩大数组,保证每次都能取K个数据的功能,但是仍有参数超出限制。
- 根据提示发现是“min1+=p[i]”以及“p[n]=min1”两处出现了问题,于是在“for j in range(0,k)”之前加入“p = p + [0]”,删除“while n%(k-1)!=1”语句。
5. 代码
n = int(input("请输入需要合并的石子堆数:"))
k = int(input("请输入每次最多合并的石子堆数:"))
arr=input("请输入每堆石子的个数:")
p =[int(i) for i in arr.split()]
p.sort()
#最大总费用
max = 0;
max1 = p[n-1];
for i in range(n-2,-1,-1):
if p[i] == 0:
break
max1 += p[i]
max += max1
#最小总费用
i=0
min = 0
min1 = 0
while i<n-1:
min1=0;
p = p + [0]
for j in range(0,k):
min1+=p[i]
i+=1
p[n]=min1
n+=1
min+=min1;
#将i-n部分排序
p[i:n] = sorted(p[i:n])
print("最大总费用为:" ,max ,"\n最小总费用为:" , min )测试数据1:
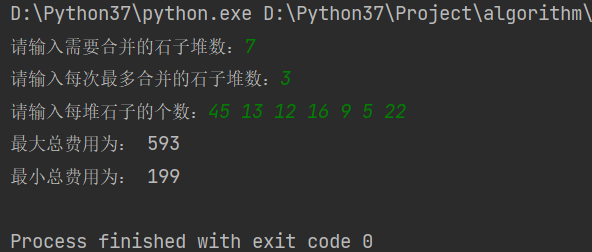
测试数据2:
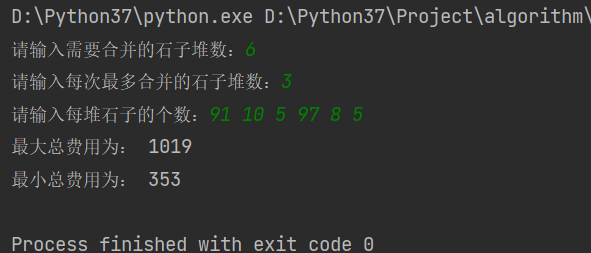















 4757
4757











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









