







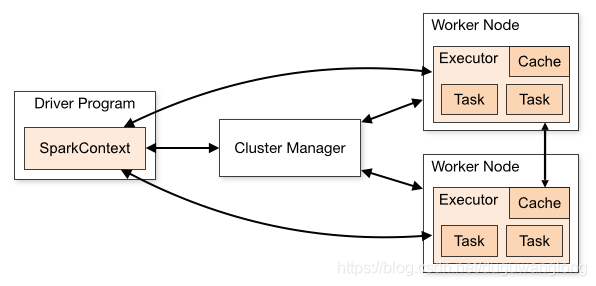
开发人员根据自己的需求,在main函数中调用Spark提供的数据操纵接口,利用集群来对数据执行并操作。Spark为开发人员提供了两类抽象接口。第一类抽象接口是弹性分布式数据集RDD,其是对数据集的抽象封装,开发人员可以通过RDD提供的开发接口来访问和操纵数据集合,而无需了解数据的存储介质(内存或磁盘)、文件系统(本地文件系统、HDFS或Tachyon)、存储结点(本地或远程结点)等诸多实现细节;第二类抽象是共享变量(Shared Variables),通常情况下,一个应用程序在运行的时候会被分成分布在不同执行节点之上的多个任务,从而提供运算的速度,每个任务都会有一份独立的程序变量拷贝,彼此之间互不干扰,然而在某些情况下任务之间需要相互共享变量。Apache Spark提供了两类共享变量,分别是广播变量(Broadcast Variable)和累加器(Accumulators)
2.1 SparkContext的创建
SparkContext的创建过程首先要加载配置文件,然后创建SparkEnv,TaskScheduler,DAGScheduler
2.1.1 加载配置文件SparkConf
SparkConf在初始化时,首先选择相关的配置参数,包含master、appName、sparkHome、jars、environment等信息,然后通过构造方法传递给SparkContext。这里的构造函数有多种表达形式,当SparkContext获取了全部相关的本地信息时开始下一步操作。
2.1.2 创建SparkEnv
创建SparkConf后就需要创建SparkEnv,这里面包括了很多Spark执行时的重要组件,包括MapOutputTracker、ShuffleFetcher、BlockManager等,这里是通过SparkEnv类伴生对象SparkEnv Object内的createDriverEnv方法实现的。
2.1.3 创建TaskScheduler
创建SparkEnv后,就需要创建SparkContext中调度执行方面的变量TaskScheduler。
TaskScheduler是依据Spark的执行模式进行初始化的。
2.1.4 创建DAGScheduler
创建TaskScheduler对象后,再将TaskScheduler对象传至DAGScheduler,进而用来创建DAGScheduler。创建DAGScheduler后再调用其start()方法将其启动。以上4点是整个SparkContext的创建过程,这其中包含了很多重要的步骤,从这个过程中能理解Spark的初始启动情况。














 9820
9820











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









