







1、ES常用api接口
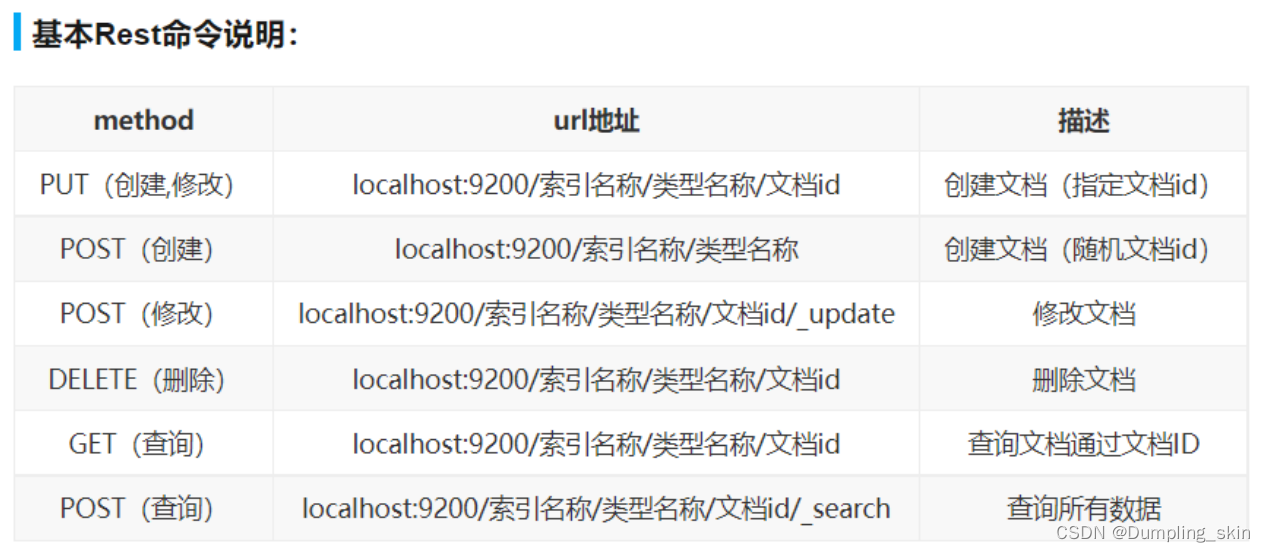
2、ES的基本操作
2.1 创建索引(数据库)
创建索引并往索引中的指定id添加一条文档
PUT /索引名称/类型名称/id
{
数据
}
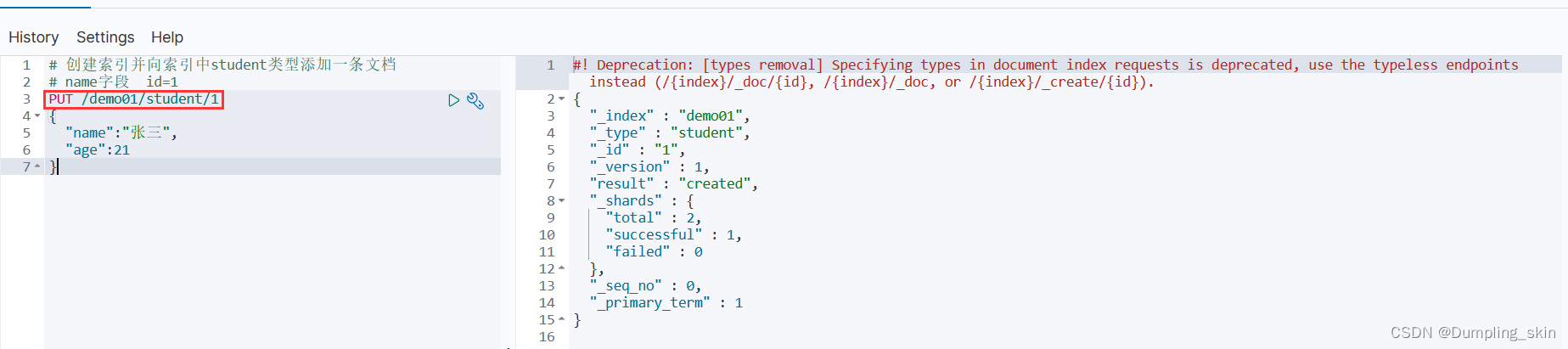
# 创建索引并向索引中student类型添加一条文档
# name字段 id=1
PUT /demo01/student/1
{
"name":"张三",
"age":21
}
创建索引并往索引中添加一条文档,不指定id
POST /索引名称/类型名称/
{
数据
}
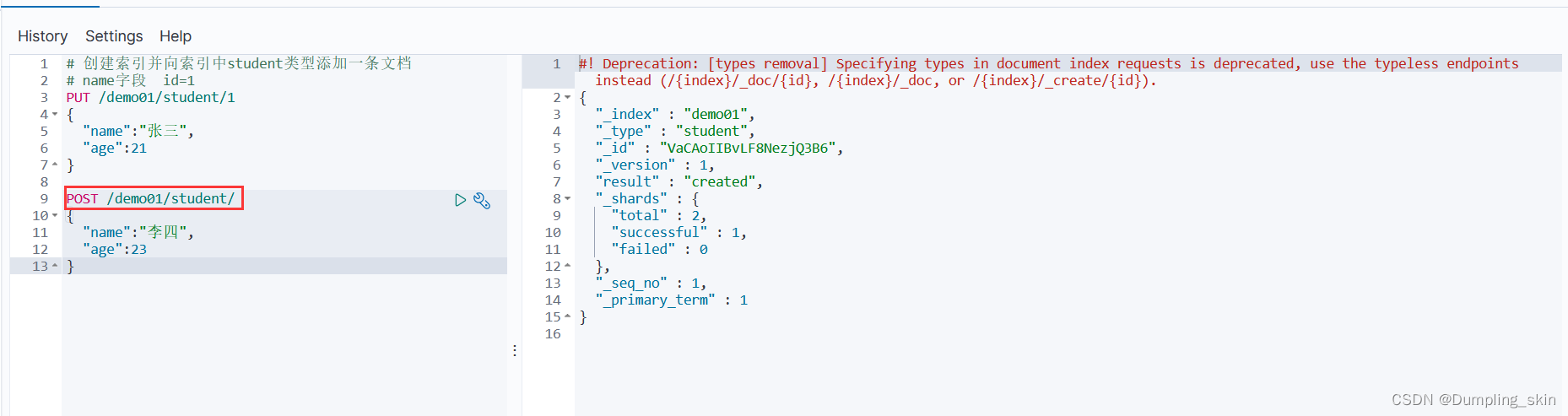
# 创建索引不指定id添加一条文档,请求方式必须为post
POST /demo01/student/
{
"name":"李四",
"age":23
}
创建索引省略类型,向默认类型中添加一条记录
POST /索引名称/_doc/1
{
数据
}
# 创建索引省略类型则默认为_doc类型,
# 从7.xx之后一个索引只用一个类型
PUT /demo02/_doc/1
{
"name":"王五",
"age":22
}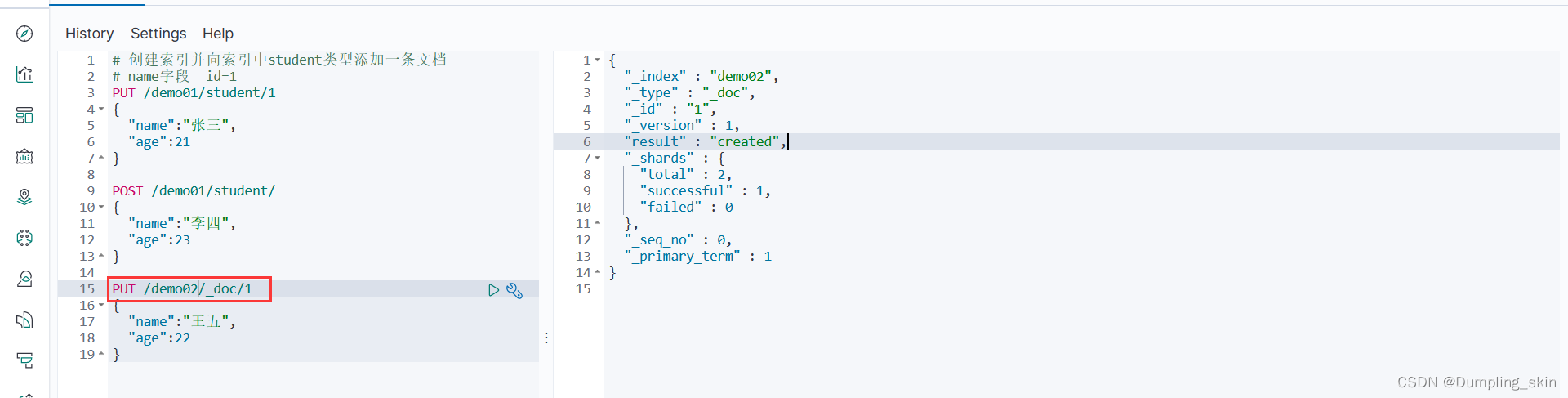
注意:一个索引中只能有一个类型,如果定义了类型在使用默认类型仍然是自己定义的类型。
创建索引,但是不添加数据。
PUT /索引名/类型(类型可省略)
PUT /demo03
{
"mappings": {
"properties": {
"name":{
"type": "text"
},
"age":{
"type": "integer"
}
}
}
}
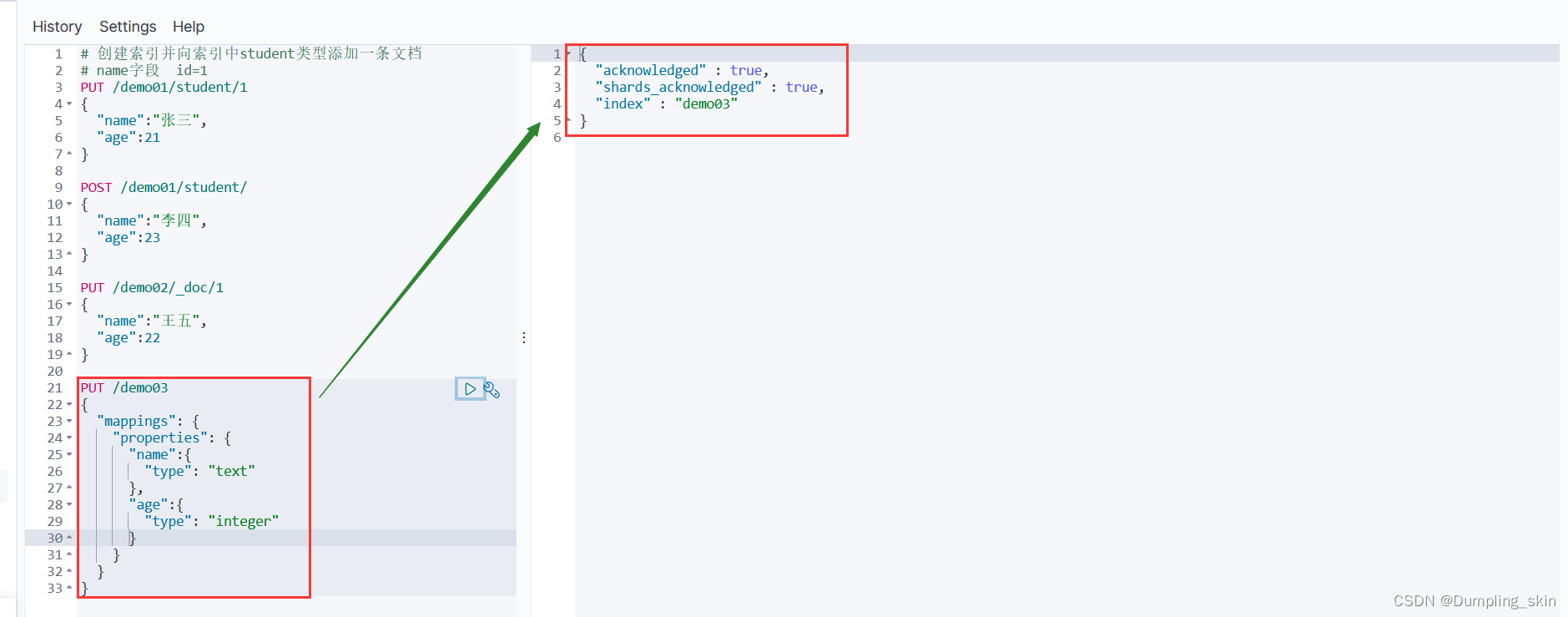
# 创建索引,不添加数据
PUT /demo03
{
"mappings": {
"properties": {
"name":{
"type": "text"
},
"age":{
"type": "integer"
}
}
}
}
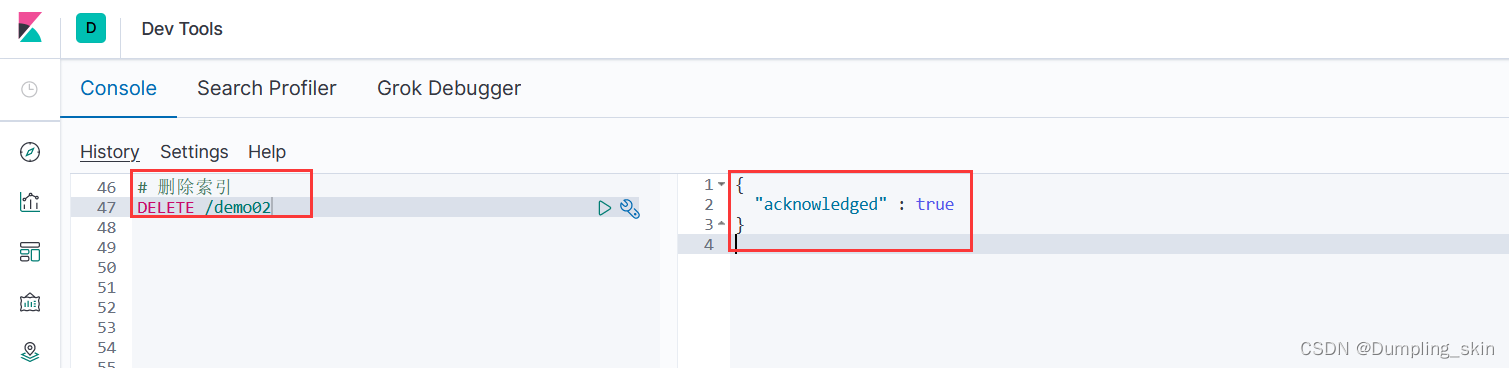
2.2 删除索引(数据库)
DELETE /索引名
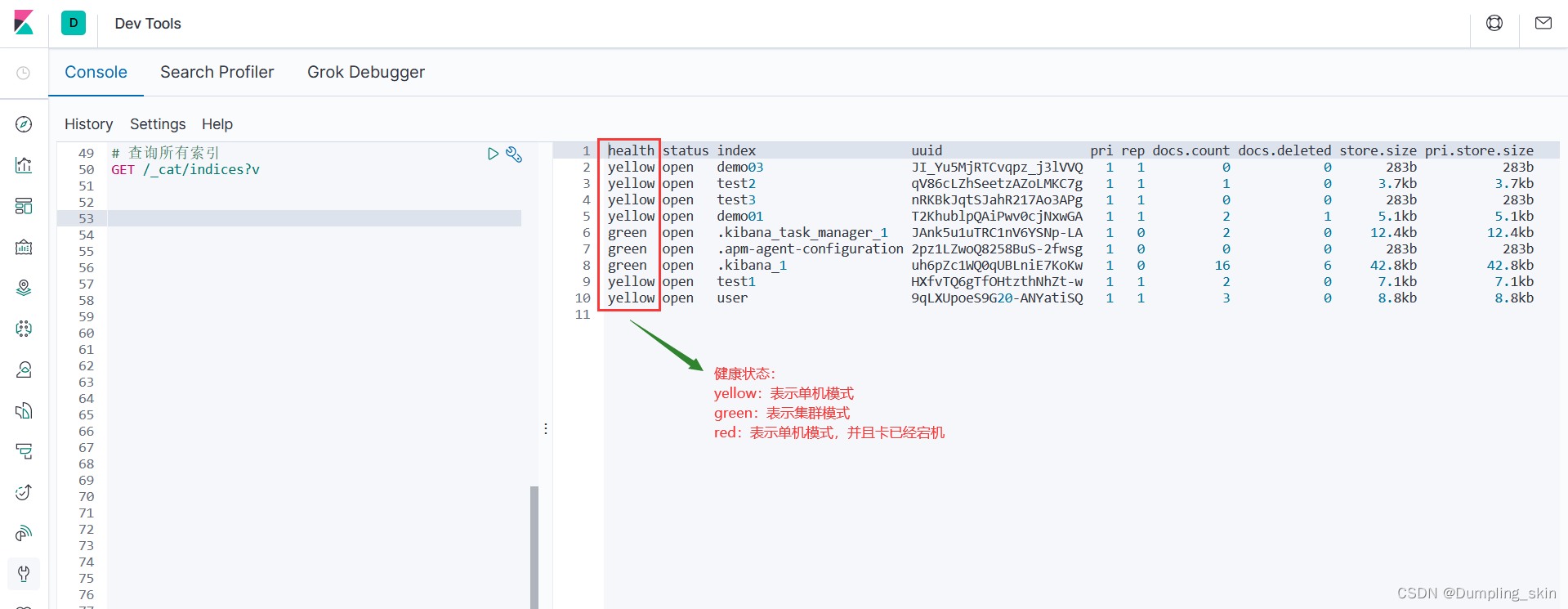
2.3 查询所有索引
GET /_cat/indices?v
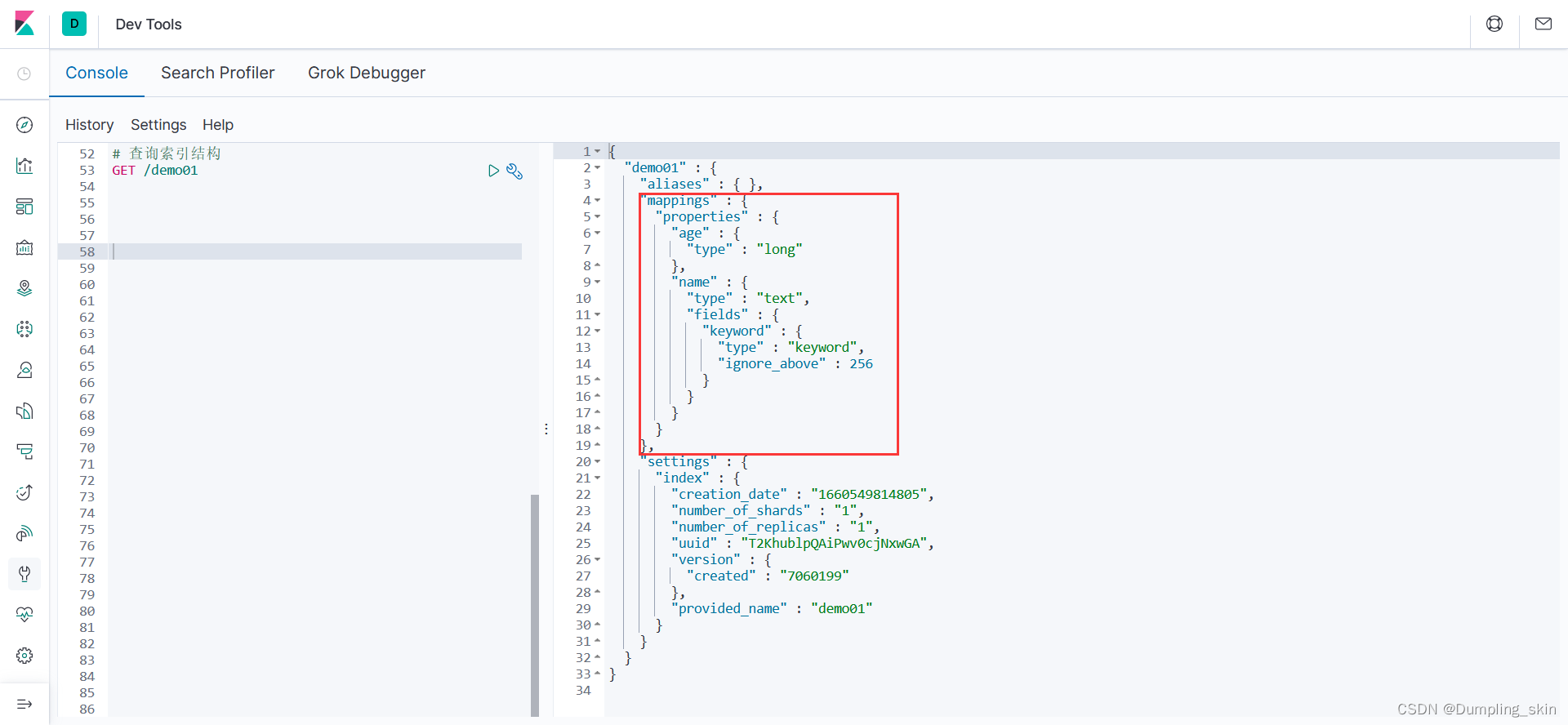
2.4 查询索引结构
GET /索引名称
2.5 添加文档(记录)
2.5.1 必须指定id的值
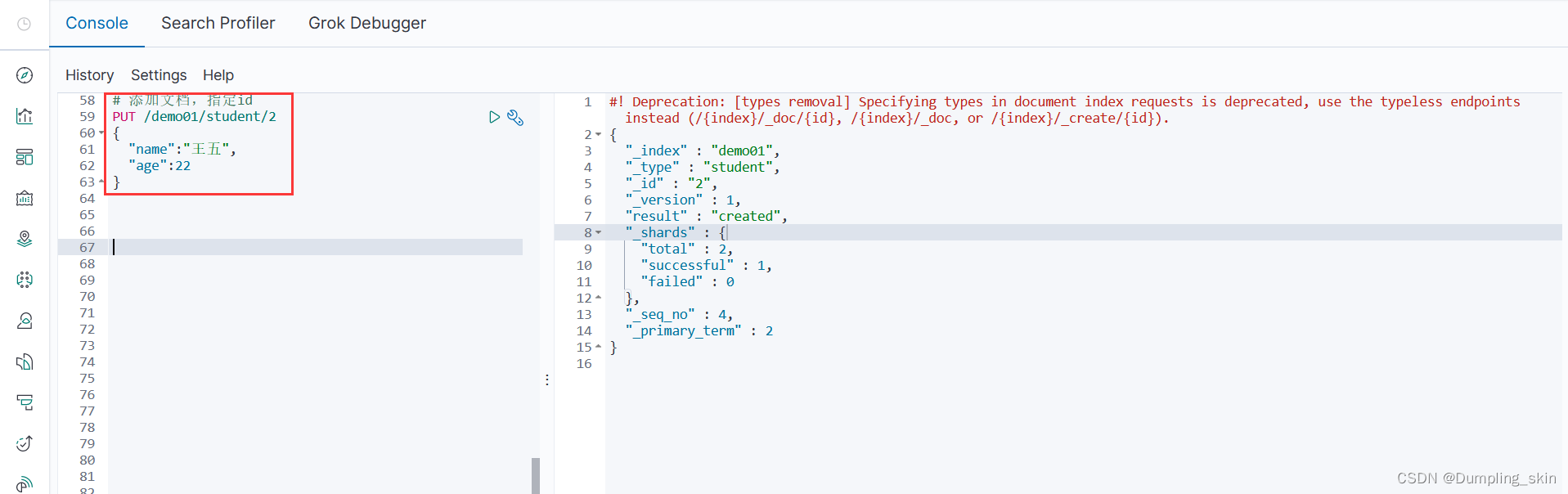
# 添加文档,指定id
PUT /demo01/student/2
{
"name":"王五",
"age":22
}
2.5.2 不指定id
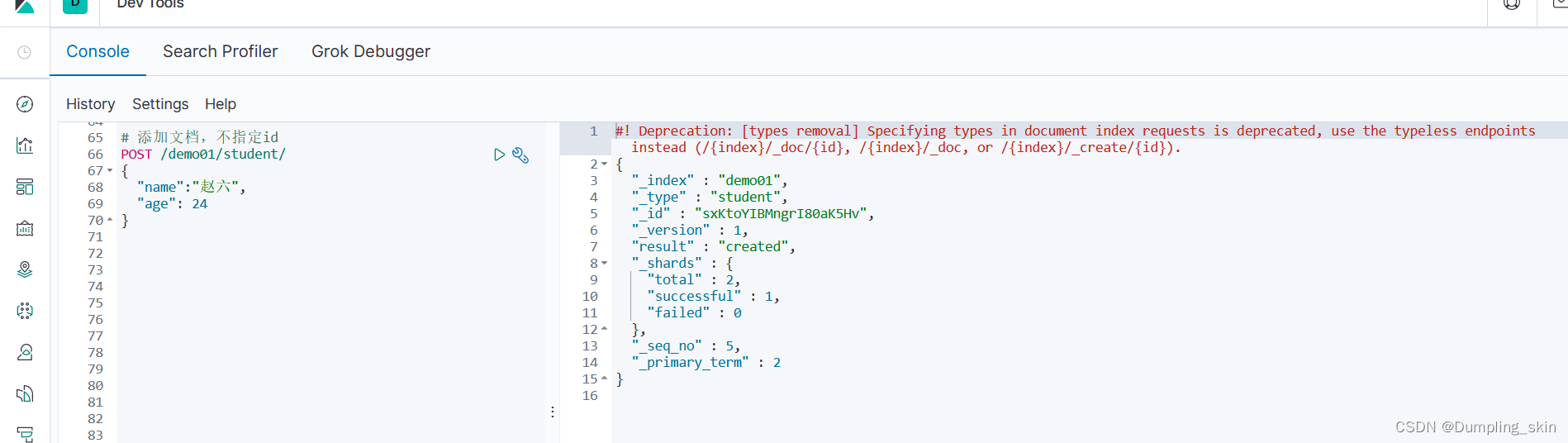
# 添加文档,不指定id
POST /demo01/student/
{
"name":"赵六",
"age": 24
}
2.6 查询文档
查询的提交方式必须为GET
# 查询索引的指定id的文档
GET /demo01/student/1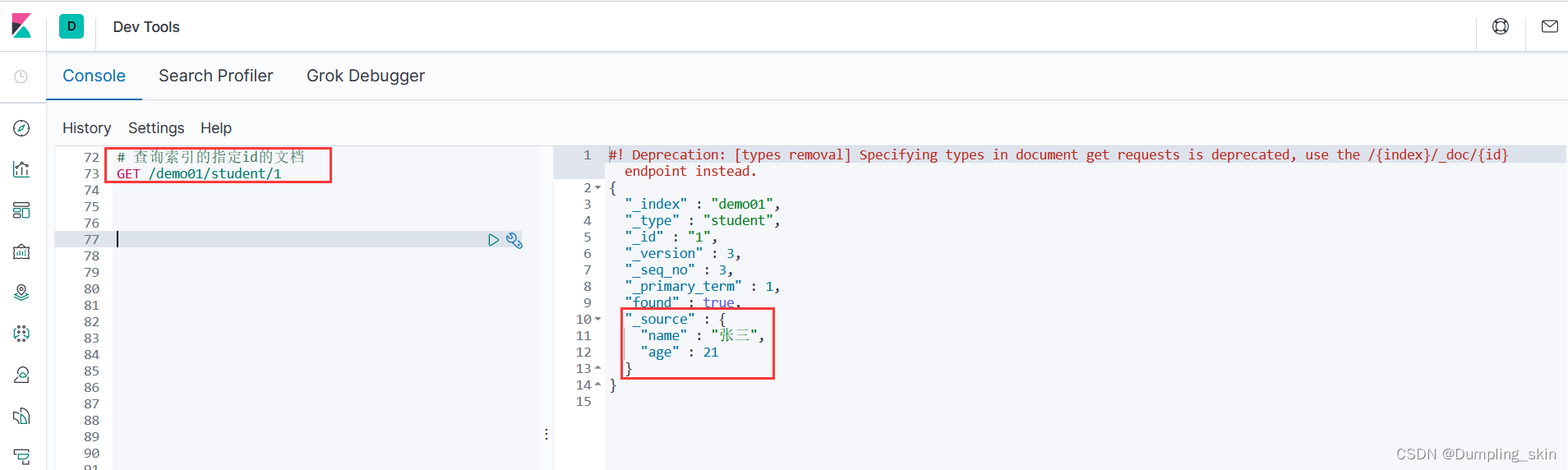
2.7 删除文档
提交方式DELETE提交方式
根据不同的操作具有不同的提交方式restful风格
GET查询, PUT修改, POST添加操作, DELETE删除操作
# 删除索引的指定id的文档
DELETE /demo01/student/VaCAoIIBvLF8NezjQ3B6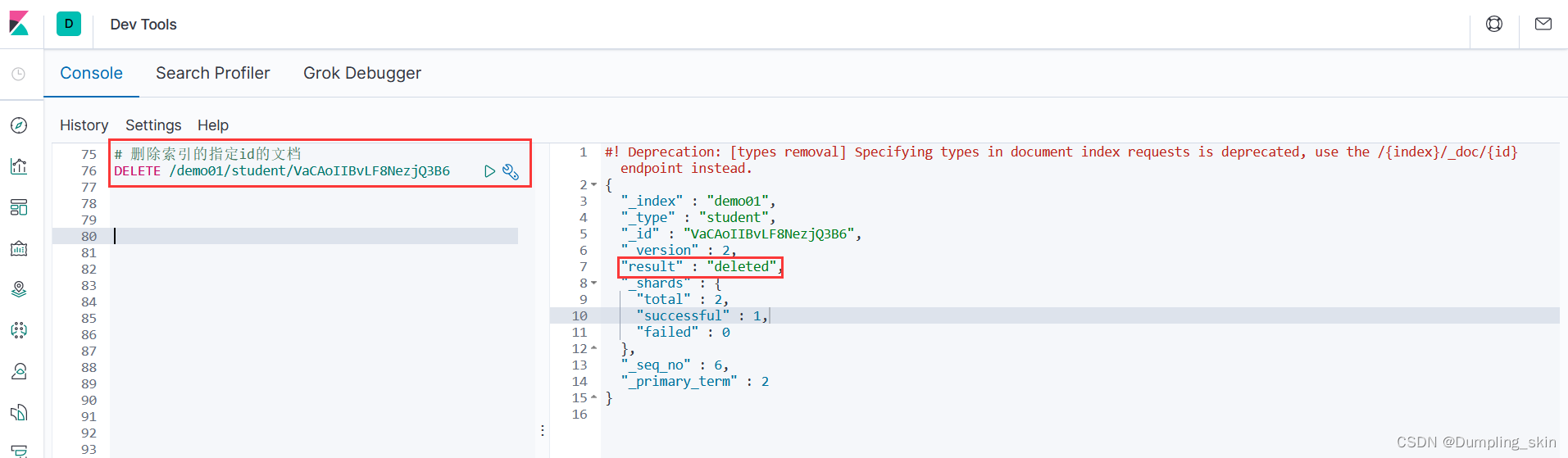
2.8 修改文档
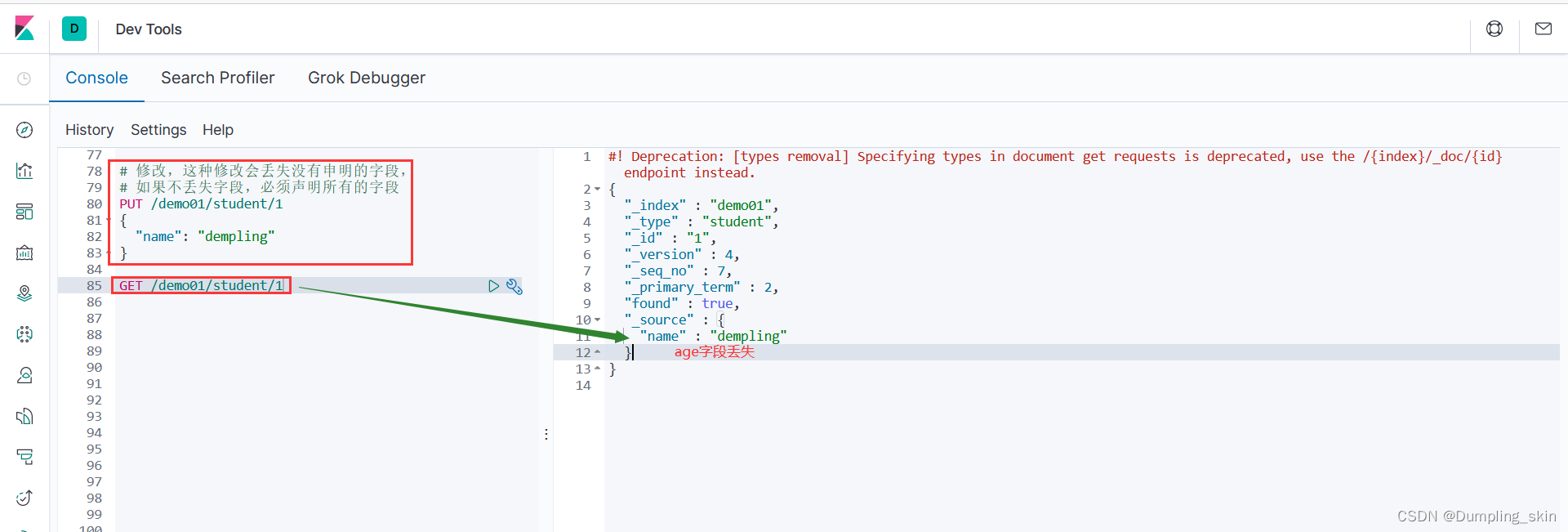
2.8.1 指定所有字段,如果只指定部分字段,其他字段会消失
# 修改,这种修改会丢失没有申明的字段,
# 如果不丢失字段,必须声明所有的字段
PUT /demo01/student/1
{
"name": "dempling"
}
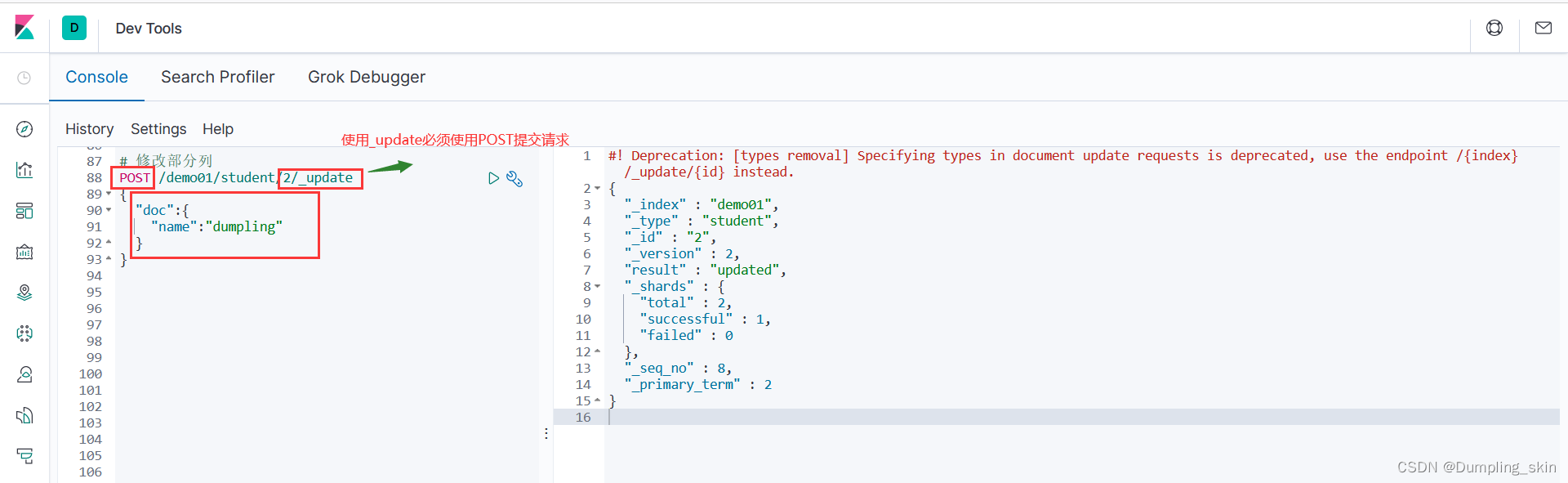
2.8.2 修改部分字段
# 修改部分列
POST /demo01/student/2/_update
{
"doc":{
"name":"dumpling"
}
}
3、根据条件查询
3.1 查询所有文档
# 查询所有文档
GET /demo01/student/_search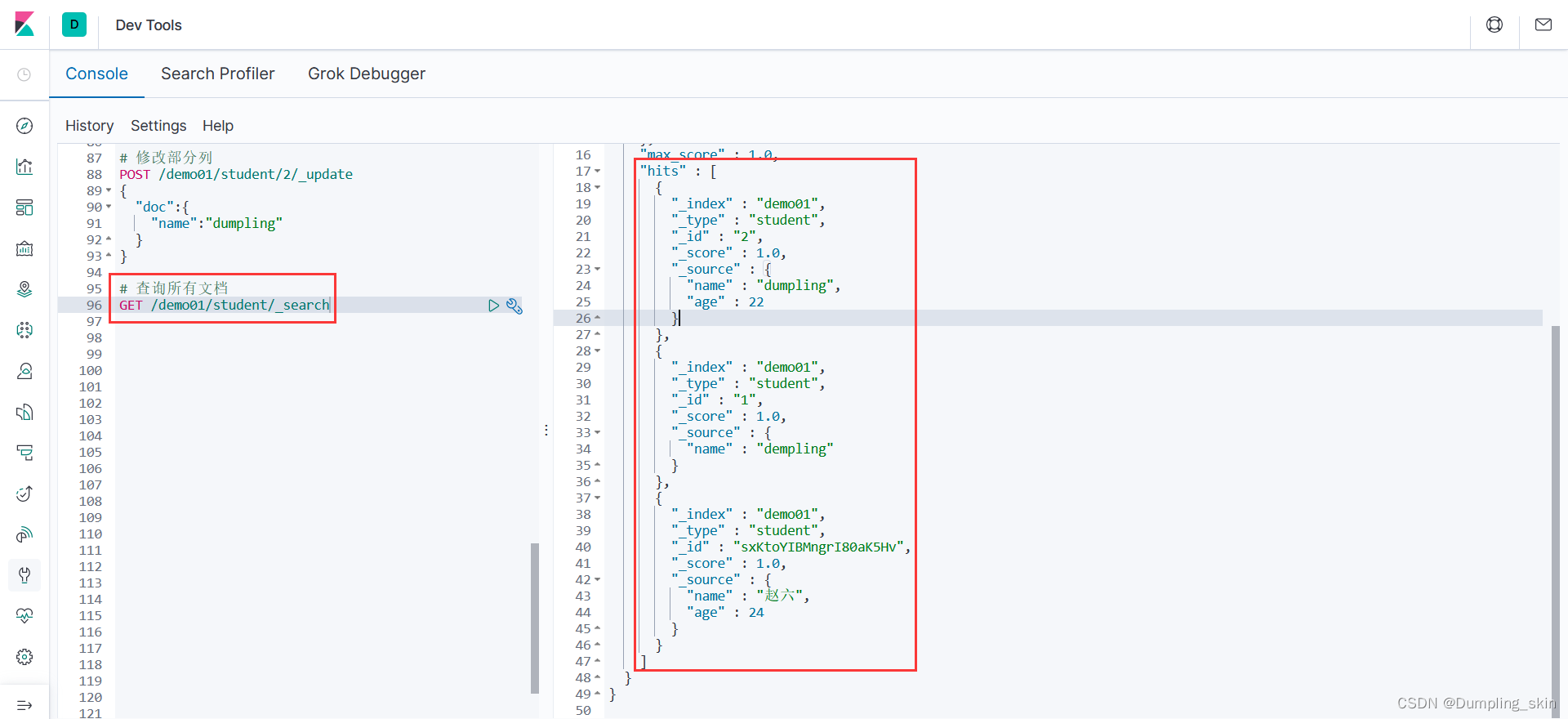
3.2 根据条件搜索
GET /索引名称/类型名称/_search?q=字段名:值
这种方式想当于模糊查询,只要是name属性值中包含这个值就可以查到,不过这里name的属性需要为text类型,text类型会进行分词操作,所以有模糊查询的效果,分词查询在文档末尾会进行介绍。
# 根据条件查询文档
GET /demo01/student/_search?q=name:dumpling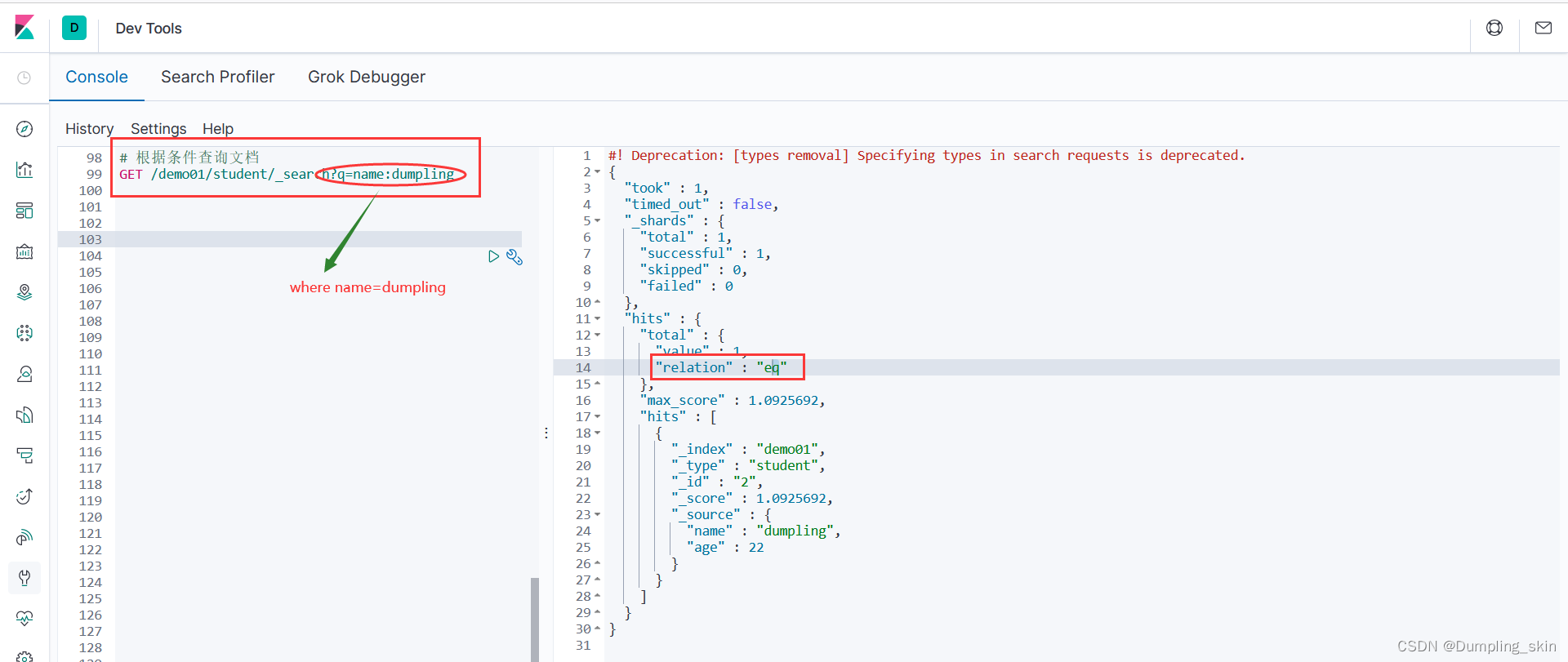
3.3 把查询条件封装成json数据
3.3.1 匹配查询,查询所有字段
match会对查询关键词进行分词操作。
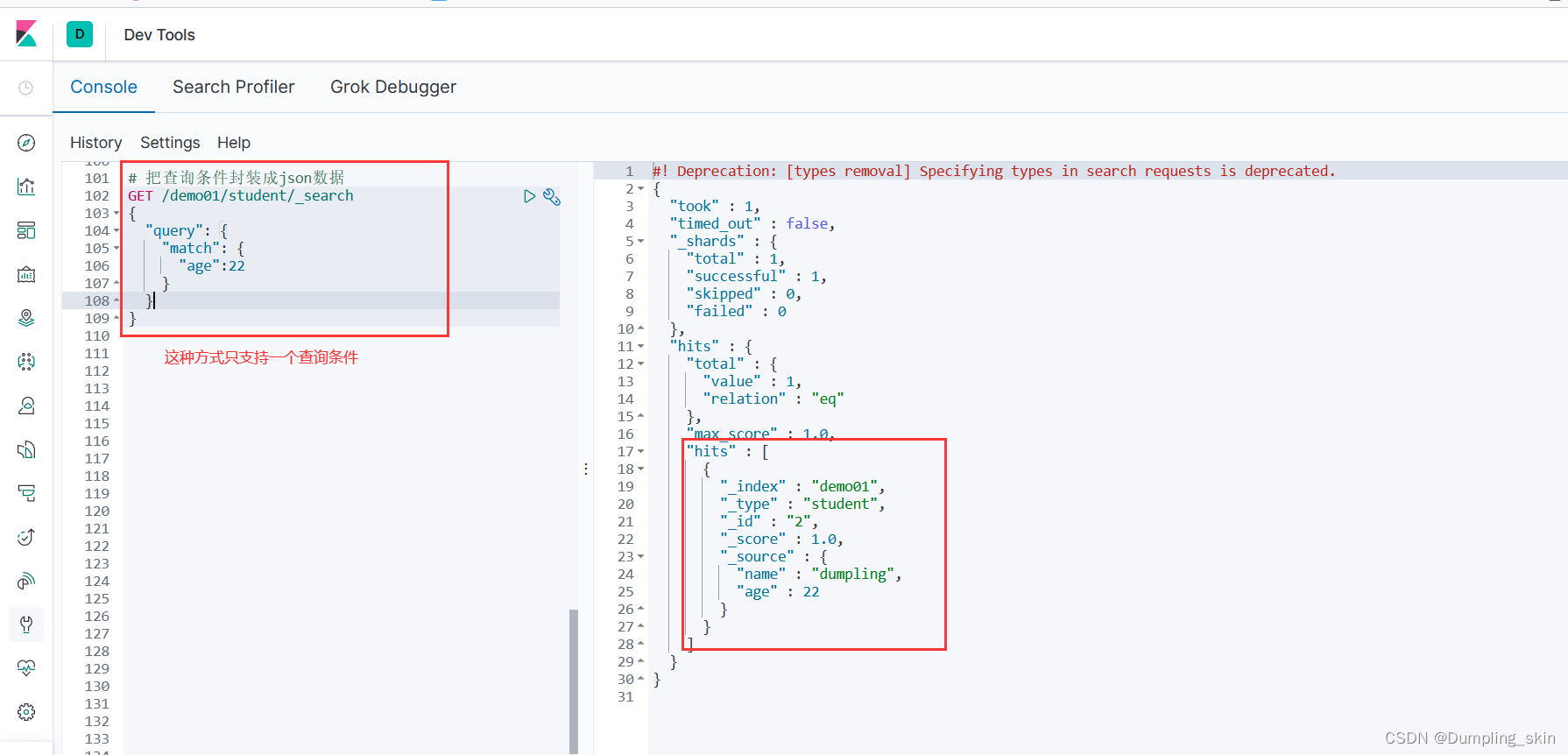
# 把查询条件封装成json数据
GET /demo01/student/_search
{
"query": {
"match": {
"age":22
}
}
}
3.3.2 查询部分字段
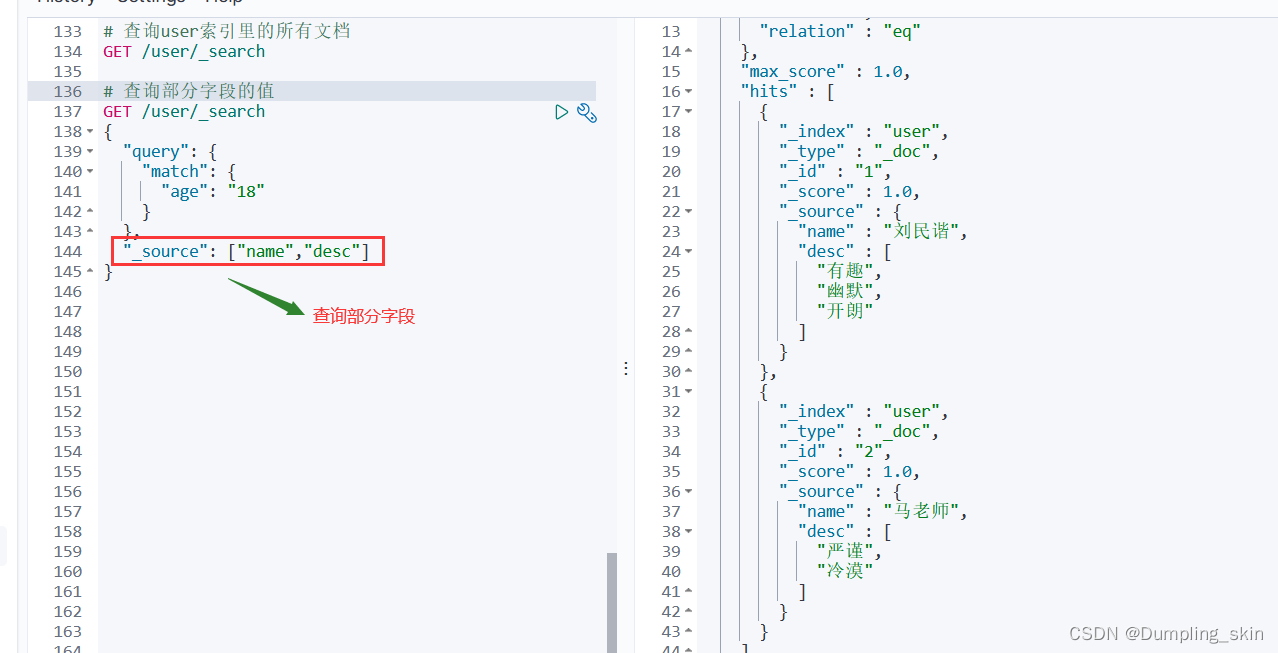
# 查询部分字段的值
GET /user/_search
{
"query": {
"match": {
"age": "18"
}
},
"_source": ["name","desc"]
}
3.3.3 分页查询
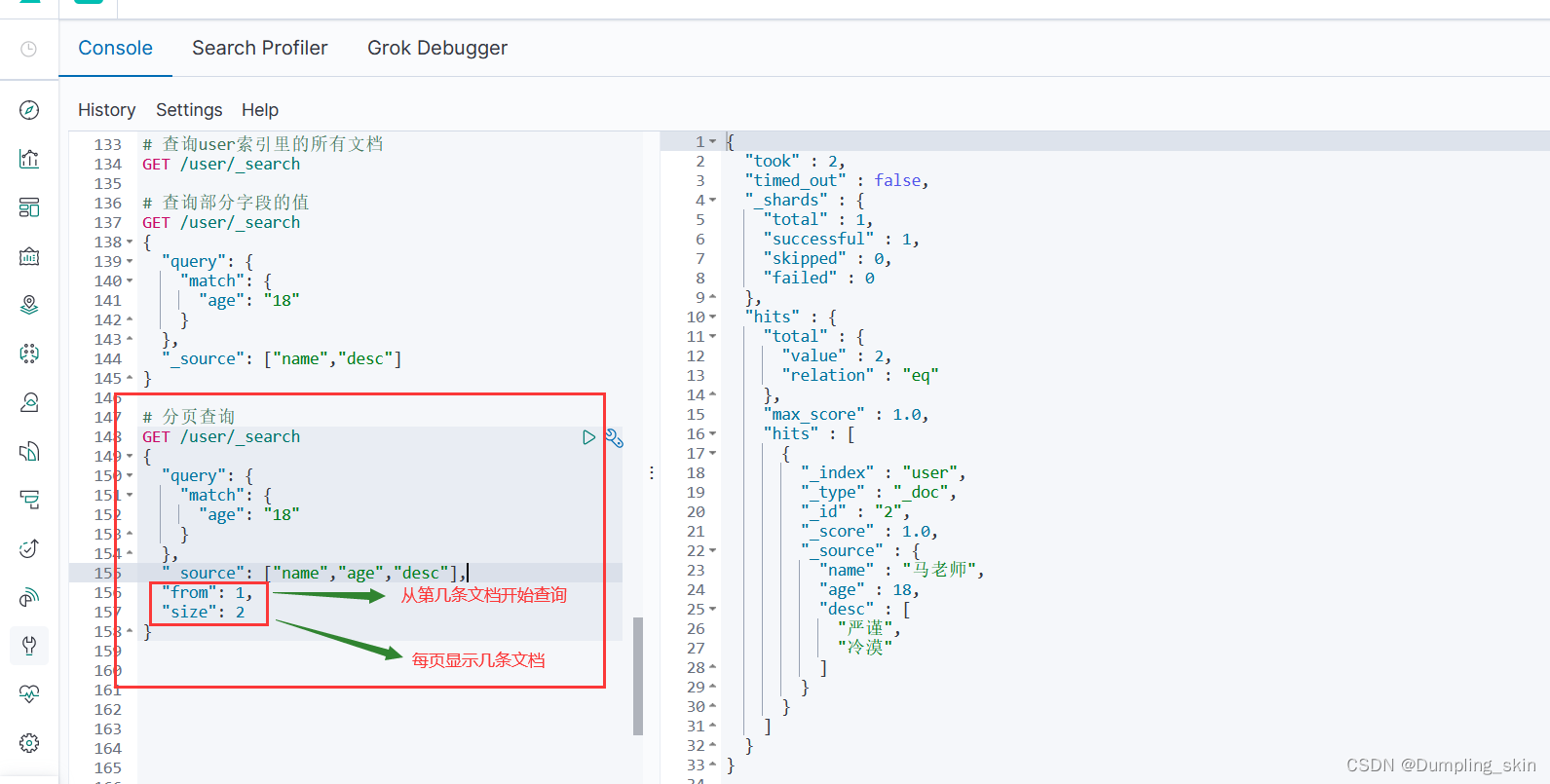
# 分页查询
GET /user/_search
{
"query": {
"match": {
"age": "18"
}
},
"_source": ["name","age","desc"],
"from": 1,
"size": 2
}
3.3.4 范围查询
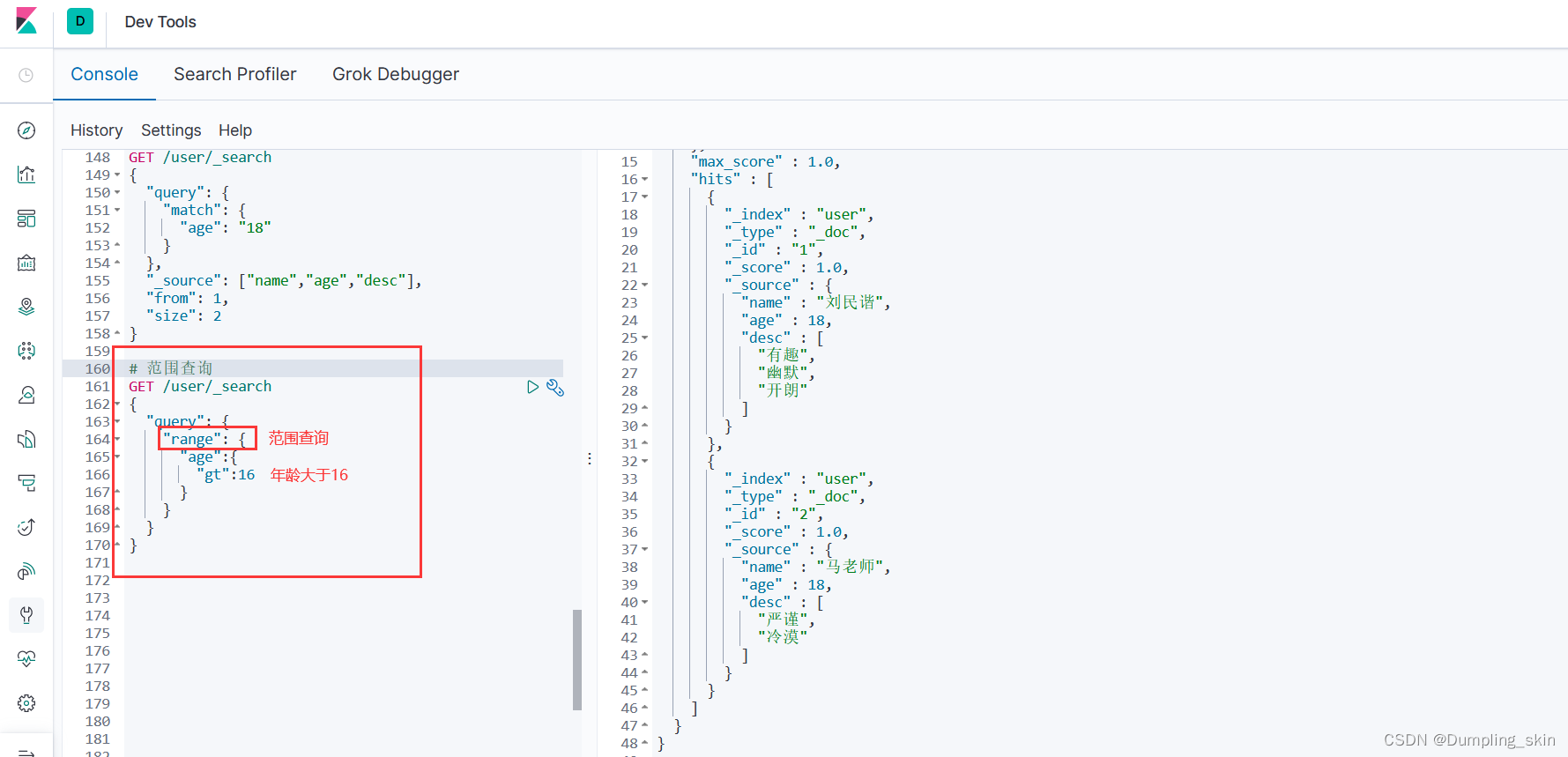
# 范围查询
GET /user/_search
{
"query": {
"range": {
"age":{
"gt":16
}
}
}
}
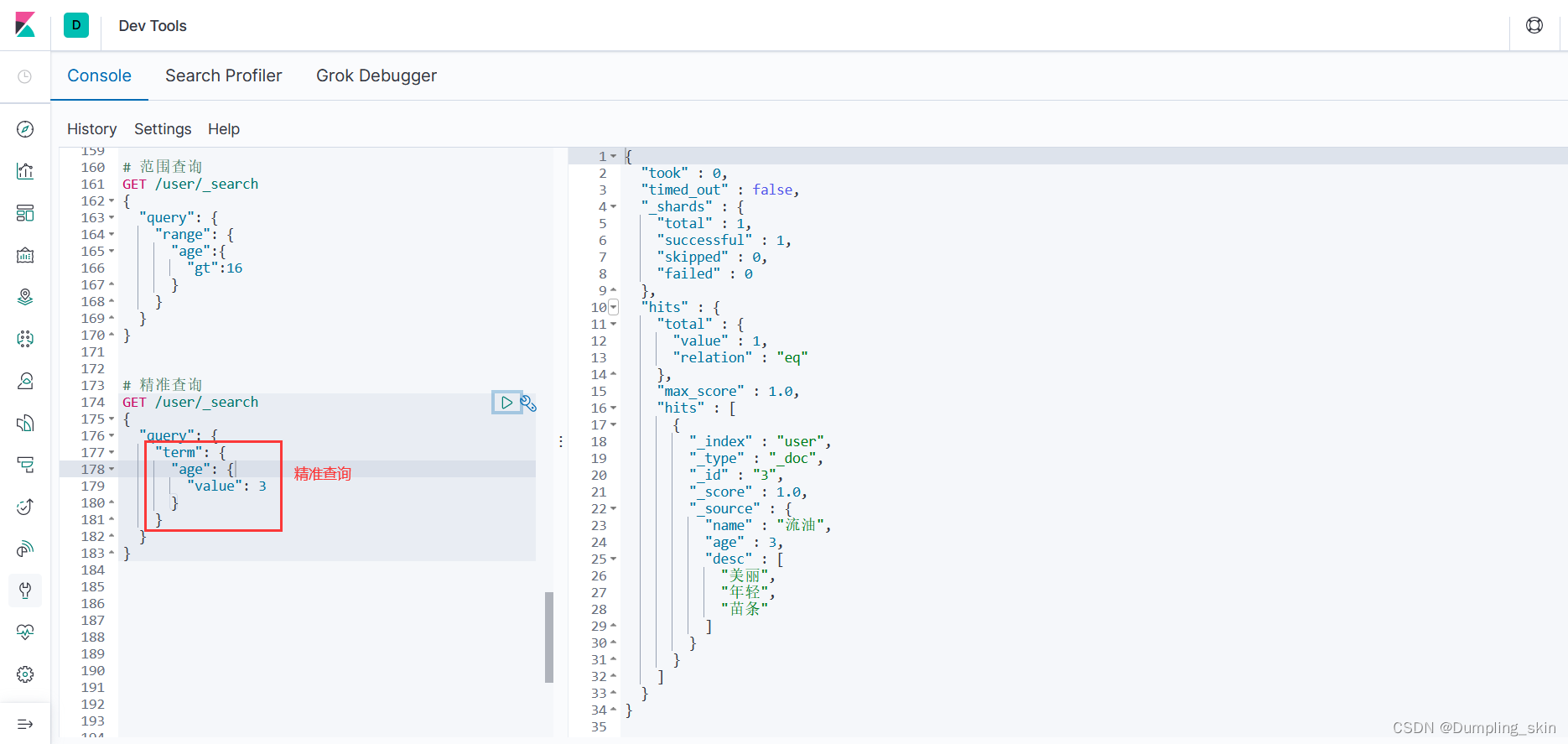
3.3.5 精准查询
term不会对查询关键字进行分词操作。
# 精准查询
GET /user/_search
{
"query": {
"term": {
"age": {
"value": 3
}
}
}
}
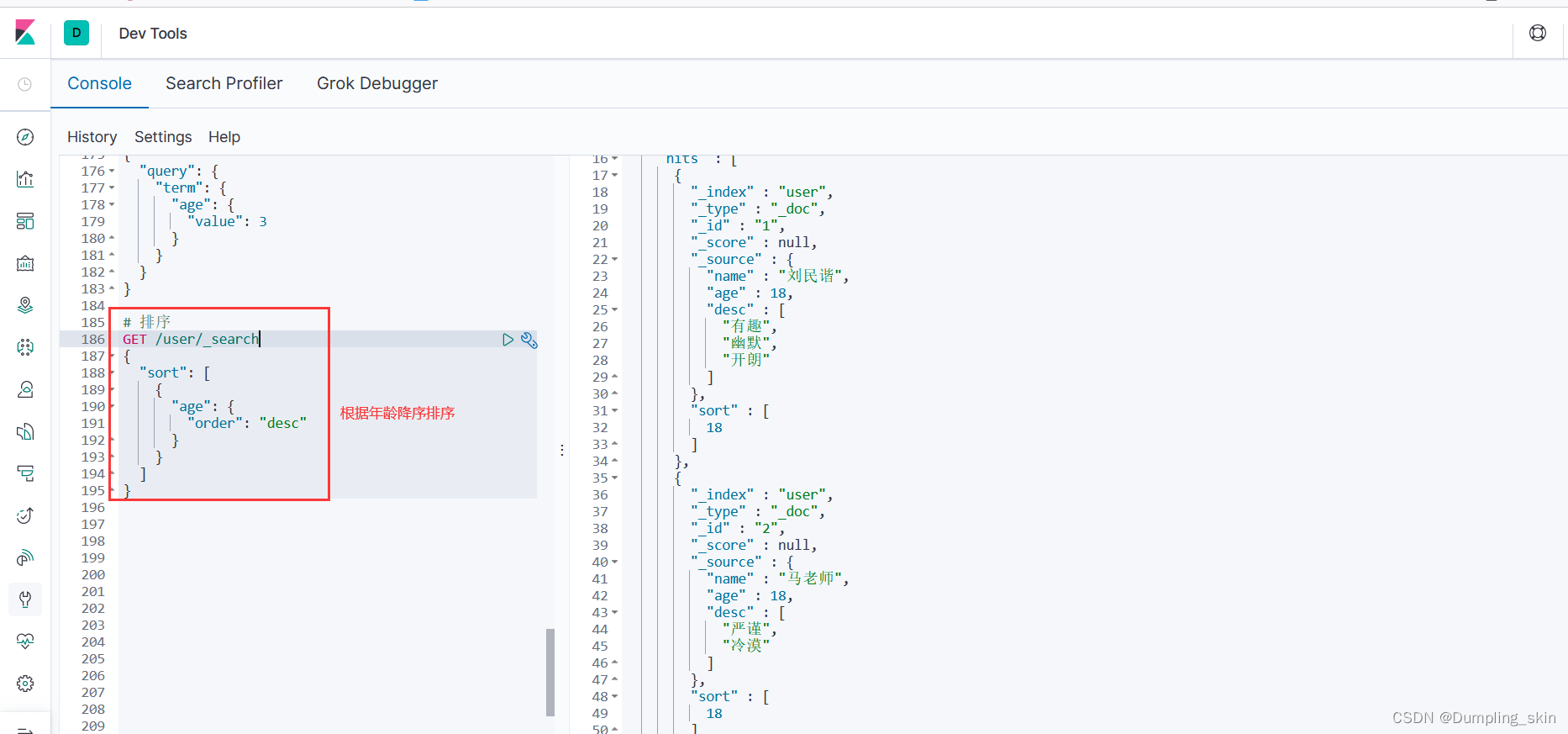
3.3.6 排序
# 排序
GET /user/_search
{
"sort": [
{
"age": {
"order": "desc"
}
}
]
}
3.4 多条件查询
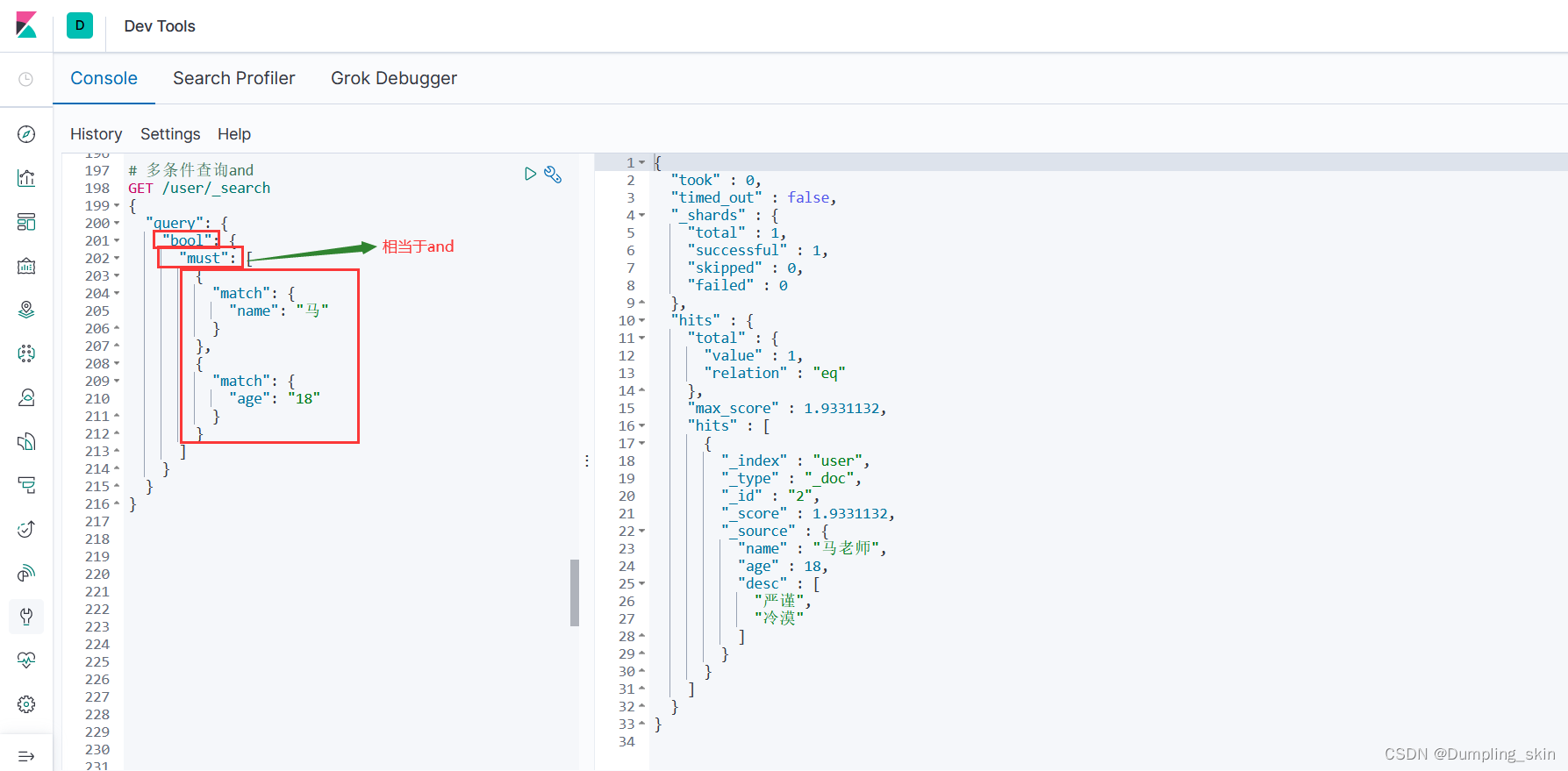
3.4.1 must等价于and
# 多条件查询and
GET /user/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"name": "马"
}
},
{
"match": {
"age": "18"
}
}
]
}
}
}
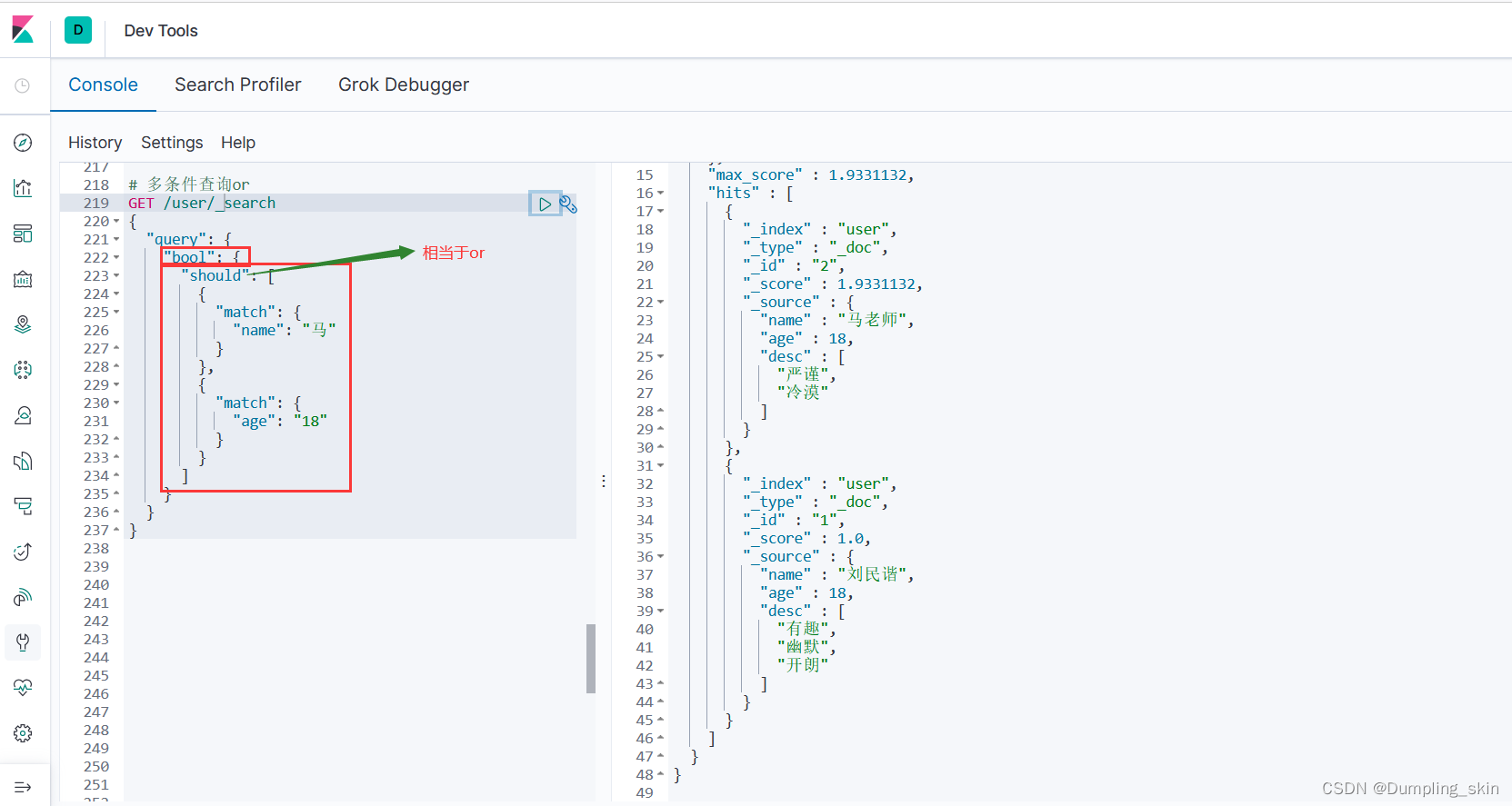
3.4.2 should等价于or
# 多条件查询or
GET /user/_search
{
"query": {
"bool": {
"should": [
{
"match": {
"name": "马"
}
},
{
"match": {
"age": "18"
}
}
]
}
}
}
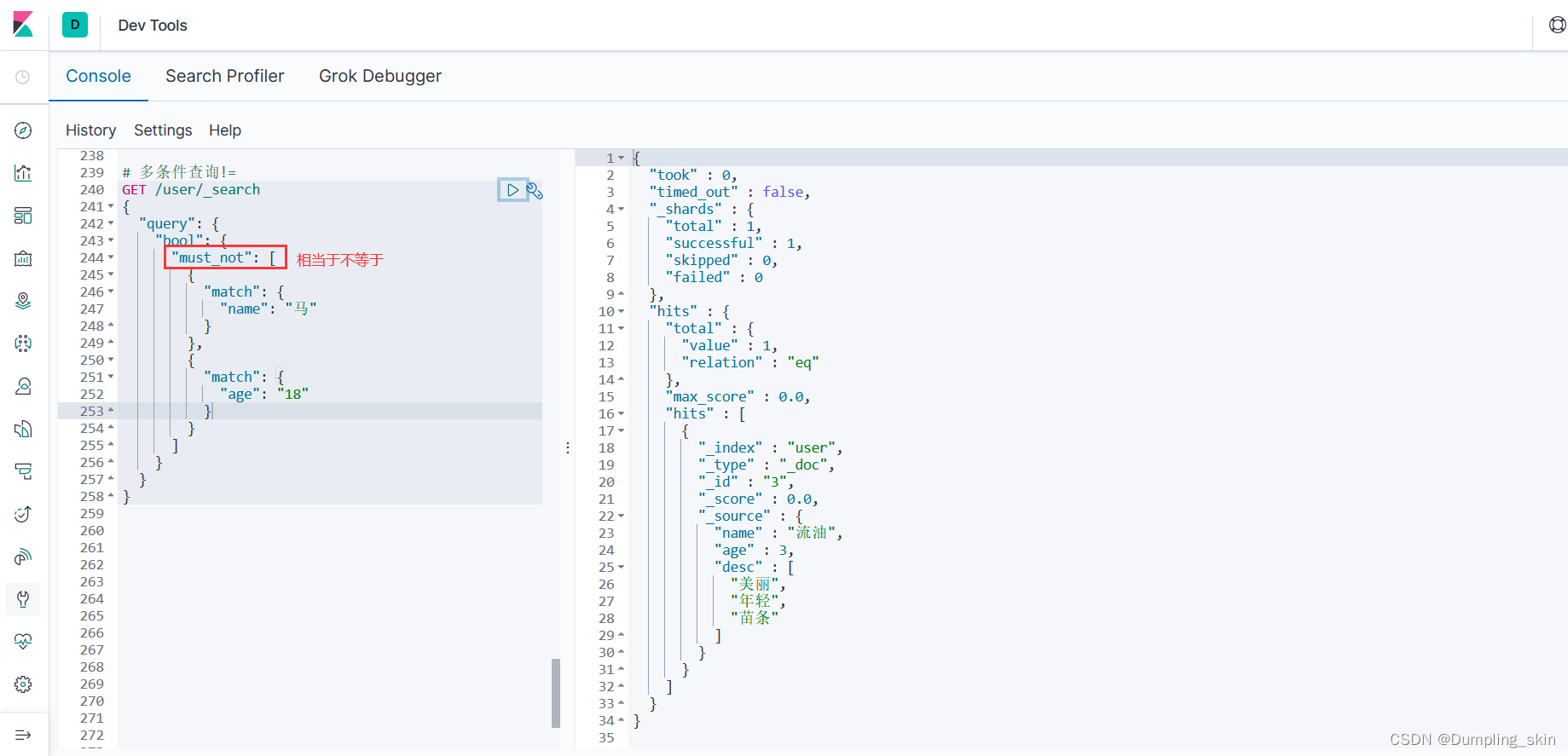
3.4.3 must-not等价于!=
# 多条件查询!=
GET /user/_search
{
"query": {
"bool": {
"must_not": [
{
"match": {
"name": "马"
}
},
{
"match": {
"age": "18"
}
}
]
}
}
}
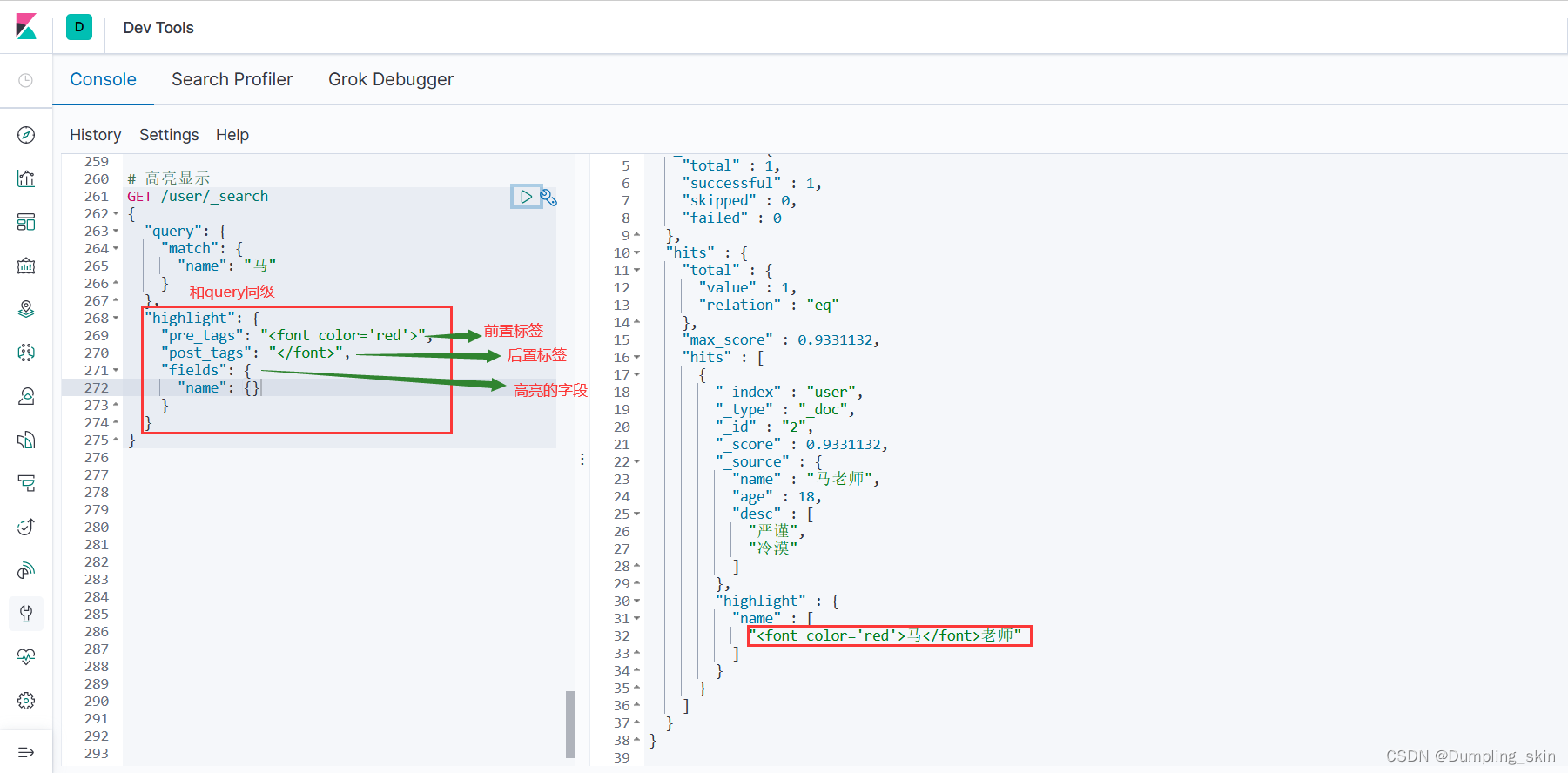
3.5 高亮显示
# 高亮显示
GET /user/_search
{
"query": {
"match": {
"name": "马"
}
},
"highlight": {
"pre_tags": "<font color='red'>",
"post_tags": "</font>",
"fields": {
"name": {}
}
}
}
4、分词搜索
4.1 什么是分词?
IK分词器: 中文分词器
分词:即把一段中文或者别的划分成一个个的关键字, 我们在搜索时候会把自己的信息进行分词,会把数据库中或者索引库中的数据进行分词,然后进行一-个匹配操作, 默认的中文分词是将每个字看成一个词(不使用用IK分词器的情况下),比如“我爱饺子皮”会被分为"我”,”爱", ”饺”, "子”,"皮"这显然是不符合要求的,所以我们需要安装中文分词器ik来解决这个问题。
IK提供了两个分词算法: ik_ smart和i_ max_ word ,其中ik_ smart 为最少切分,ik_ max_ word为最细粒度划分!
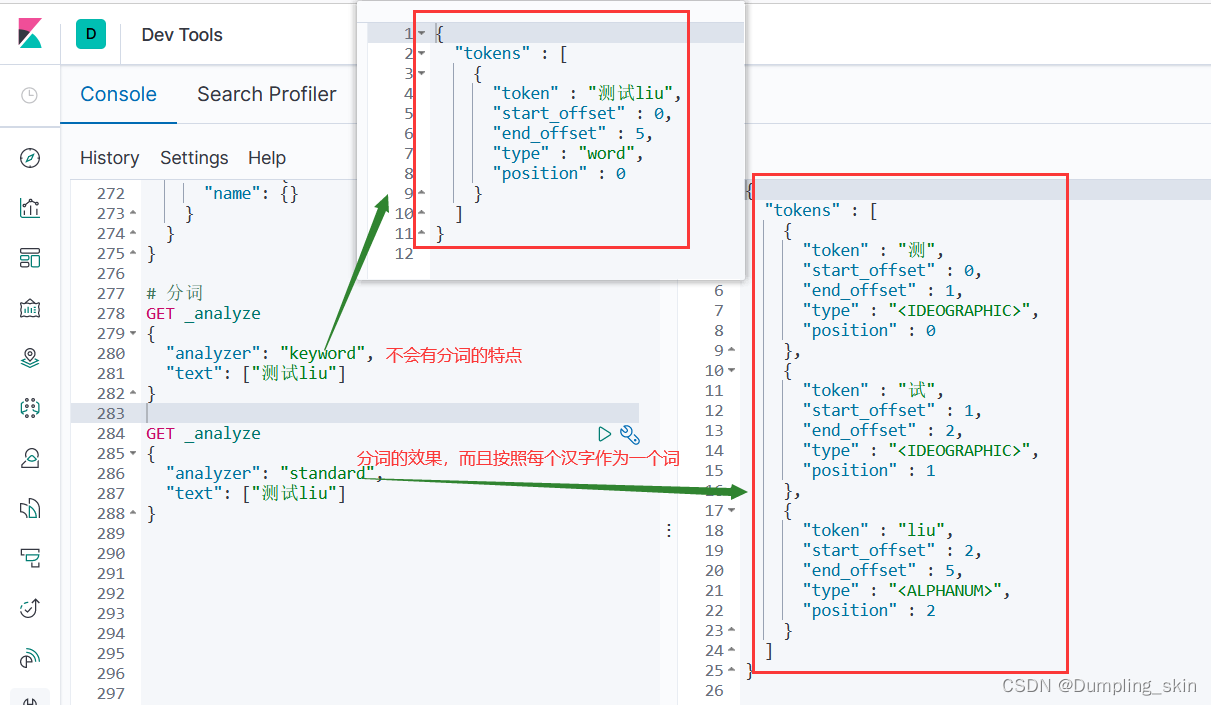
text(standard)和keyword类型的区别:
text类型会为该字段的内容进行拆词操作,并放入倒排索引表中,
keyword类型不会进行拆词操作。
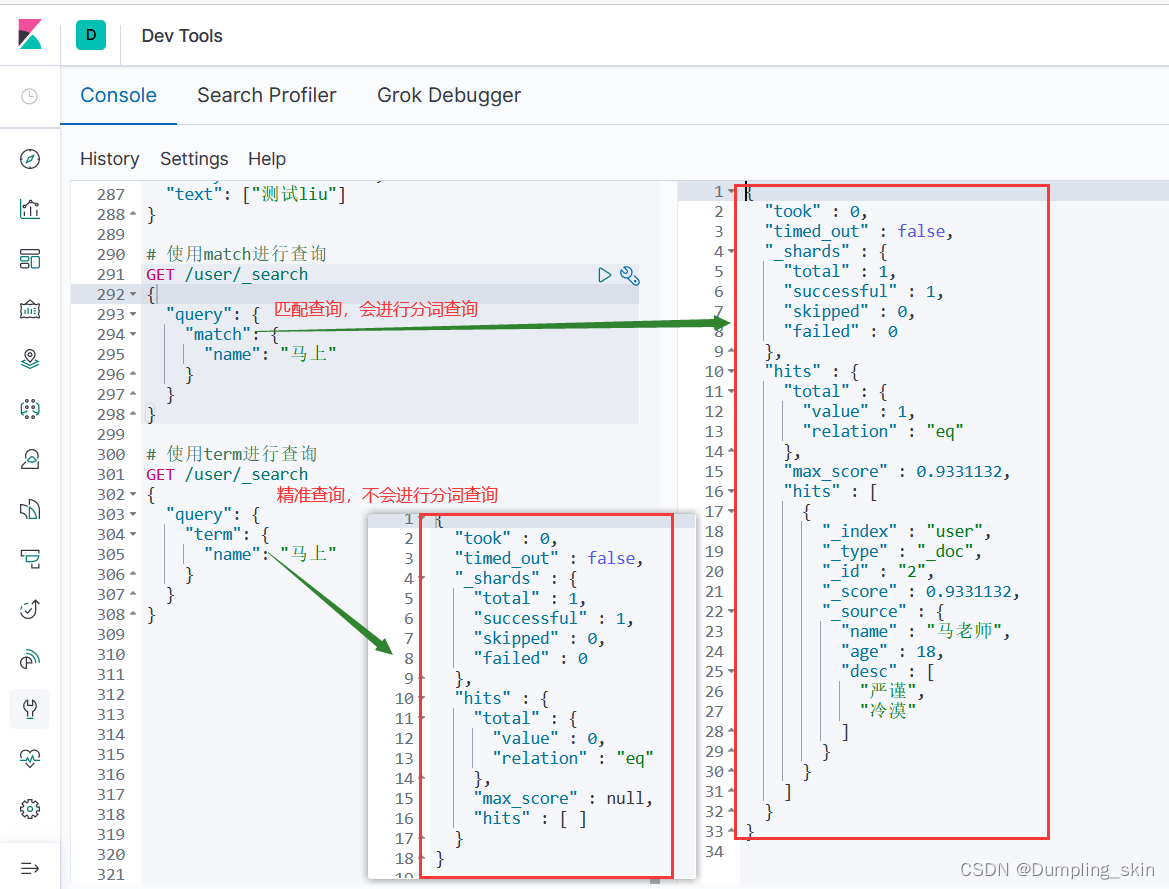
match和term的区别:
使用match匹配查询:对匹配的关键字进行拆字操作,并和倒排索引表中对应。
使用term精准匹配:它不会对关键字进行拆字操作,并且把关键字作为一个整体和倒排索引表进行排序。














 4039
4039











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









