











摘要
谱聚类因其良好的聚类效果而备受关注,但其高计算成本使其难以应用于大规模多视图聚类。针对这一问题,本文提出了一种简单高效的大规模多视图谱聚类算法,该算法基于两阶段均匀分布锚点选择策略(TWAS)。首先,将数据集划分为多个不相交的样本块,以获得全局均匀分布的锚点候选集。然后,在每个局部锚点候选集中选择代表性锚点。该两阶段锚点选择策略能够以较低的计算成本识别具有显著代表性的锚点,从而有效捕获数据的内在结构。其次,本文设计了一种自适应近邻图学习方法,用于构建基于锚点的视内相似度矩阵。最后,通过多视图融合获得一致的视间相似度矩阵,并最终得到聚类结果。大量实验表明,TWAS 算法在聚类效果、计算效率和稳定性方面均具有优越性。
引言
随着传感器和互联网的快速普及,同一对象通常可以以多个视角进行捕获和表示[1,2],例如,不同新闻机构对同一事件的报道、不同监控视角下的同一物体,以及不同语言翻译的同一文本。从多视角数据中学习对象的信息通常比单视角数据能获得更准确的结果。在无监督学习领域,多视角聚类已受到广泛关注。多视角聚类算法可大致分为四类[3,4]:协同学习[5,6]、多核学习[7,8]、多视角子空间聚类[9–11]和多视角谱聚类[12–15]。
本文致力于研究基于多视角图的谱聚类。谱聚类是一种基于图论的经典聚类方法,由于其良好的聚类效果而被广泛应用[16]。例如,De 等人[17]首先研究了双视角数据的聚类,并提出了一种基于二部图最小化不一致准则的谱聚类算法。Zhou 等人[18]利用基于二部图的学习方法来综合最终的一致性聚类结果。Wang 等人[19]在每个视角上引入了局部流行度约束,进一步探索了基于低秩逼近的多视角谱聚类。Cai 等人[20]引入了非负性和正交性约束,研究了鲁棒的局部多视角谱聚类。
在大数据时代,数据量的指数级增长使得大规模多视角谱聚类面临重大的计算挑战[21]。谱聚类的高复杂度限制了其在大规模数据集上的应用[22],主要瓶颈在于相似性矩阵的构建和谱嵌入的计算。为了解决该问题,一些致力于提升计算效率的多视角谱聚类算法被提出,如基于矩阵分解和基于锚点的方法。例如,Wang 等人[23]提出了一种基于多样性矩阵分解的方法,通过减少多视角表示之间的冗余来提高学习效率。然而,这些方法往往仅关注公共表示的学习,而忽略了数据的内在结构。另一种方法是锚点策略,通过从原始数据中选择少量代表性锚点来捕获数据的潜在结构,从而有效降低计算成本。因此,锚点策略被广泛应用于大规模聚类[24,25]。例如,Guo 等人[26]提出了一种基于锚点的简单有效的部分多视角聚类方法。Li 等人[27]利用 K-Means 方法将多个视角整合到统一的单视角表示中,以构建二部图。然而,针对高维、大规模的多视角数据,这些方法仍然计算量较大。Li 等人[28]提出了一种基于直接交替采样的锚点选择方法,可用于处理大规模多视角数据集。但该方法每次仅选择一个锚点,导致效率较低。近年来,一些基于锚点图的高效聚类算法相继被提出。例如,Zhou 等人[29]基于特征值准则设计了一种锚点选择方法,使得可以直接通过谱聚类获取聚类结果。Zhang 等人[30]通过将稀疏相似性图引入对称矩阵分解,得到了一种能够捕获图结构细节的非负矩阵表示,并基于此提出了一种新的非负锚点图重构模型。为了减少锚点选择与后续子空间图构建之间的分离对聚类的负面影响,Wang 等人提出了一种快速、无参数的多视角子空间聚类算法,该算法由一致性锚点驱动,并取得了良好的聚类效果[31]。
总的来说,随机选择和 K-Means 算法是生成锚点的两种主要方法[32–38]。全局随机选择策略简单高效,但所选锚点的代表性无法得到保证,导致聚类结果的稳定性较差。相比之下,K-Means 方法使用聚类中心作为锚点,代表性较强,但计算复杂度较高,仍难以应用于大规模多视角数据。
为了解决锚点选择的问题,本文提出了一种新颖的锚点选择策略。该策略的目标是在计算成本与随机选择相当的情况下,选择一组具有代表性的锚点。为实现该目标,设计了一个两阶段方法。在第一阶段,即全局均匀锚点候选划分阶段,采用一种策略将数据集划分为若干个不相交的数据子集作为锚点候选,以确保下一步选出的锚点均匀分布。在第二阶段,即局部锚点选择阶段,在每个锚点候选集中使用低成本的随机方法生成锚点。通过这一两阶段选择过程,所选锚点能够有效地代表数据集结构,且计算成本接近全局随机锚点选择方法。基于所提出的两阶段锚点选择策略,进一步设计了一种新的大规模多视角谱聚类方法,该方法利用自适应最近邻图学习方法,构建基于锚点的相似性矩阵,从而有效解决谱聚类中相似性矩阵构建的高复杂度问题。大量实验表明,该算法能够高效地处理大规模多视角数据。
本文的主要贡献如下:
- 设计了一种两阶段均匀锚点选择策略,该策略具有接近线性的时间复杂度,所选锚点能够很好地代表数据结构,在处理大规模数据时保证了方法的有效性和高效性。
- 提出了一种基于锚点自适应的多视角融合策略,并基于此策略设计了一种无参数、可扩展的多视角聚类算法。
- 通过与当前最先进的多视角谱聚类方法进行广泛实验比较,验证了所提出方法的优越性。
模型
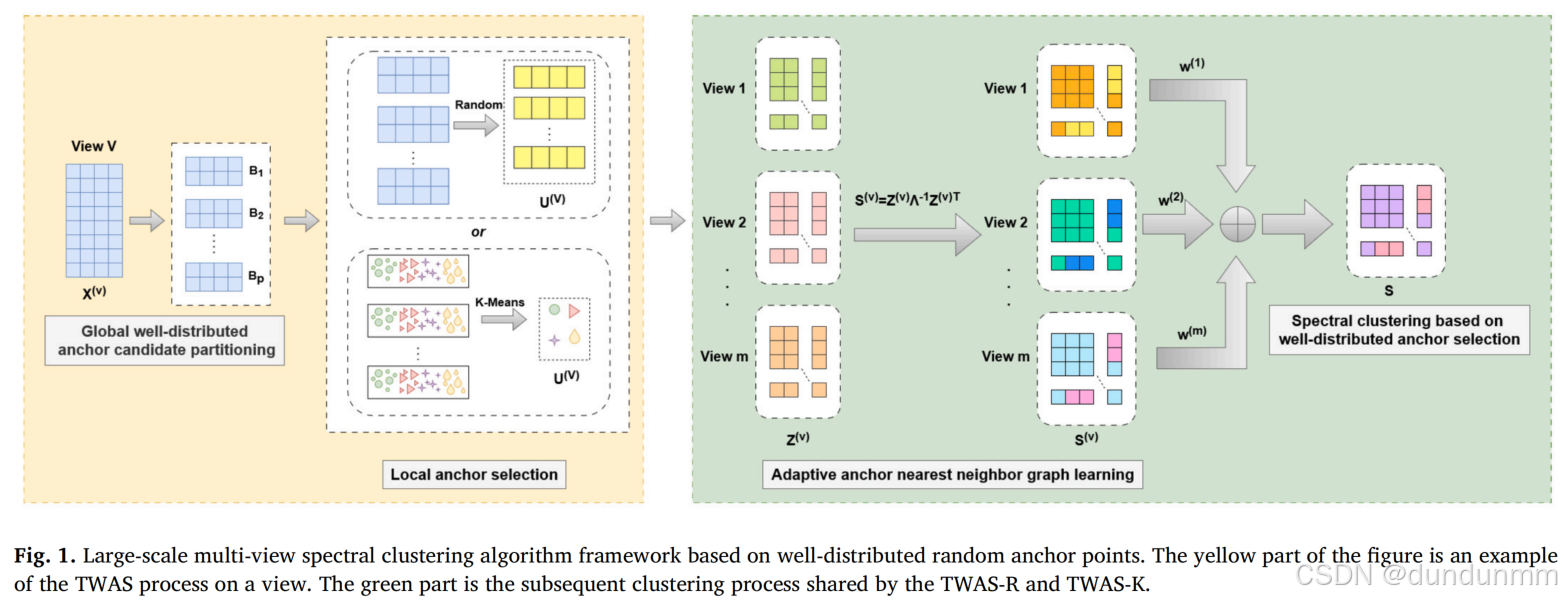
设计的方法的完整流程如图 1 所示。
首先,将每个视图均匀划分为若干数据块,以确保每个锚点候选集的分布均匀。然后,通过 K-Means 算法或随机算法选择锚点,并基于这些锚点学习相似性图。随后,将多个相似性图进行融合,以获得加权相似性图。最后,采用谱聚类算法进行聚类分析,得到最终的聚类结果。
定义 1. TWAS:两阶段均匀分布锚点选择策略
两阶段均匀分布锚点选择策略(Two-stage Well-distributed Anchor Selection strategy,TWAS)是一种两阶段的锚点选择策略。
- 第一阶段:根据距离度量函数,将数据集均匀划分为不相交的子数据集,作为锚点候选集。此方法的锚点候选划分方式称为均匀分布(well-distributed)。
- 第二阶段:称为局部锚点选择,在每个锚点候选集中,使用随机方法或K-Means 方法选择最终的锚点点集。
定义 2. TWAS-R
在 TWAS 的第二阶段,若采用随机算法选择锚点,则称之为 TWAS-R。
在 TWAS-R 方法中,为每个视图学习样本点与锚点的相似性图,并进行加权融合,得到最终的加权相似性图 S。随后,对 S 进行谱聚类,获得最终的聚类结果。
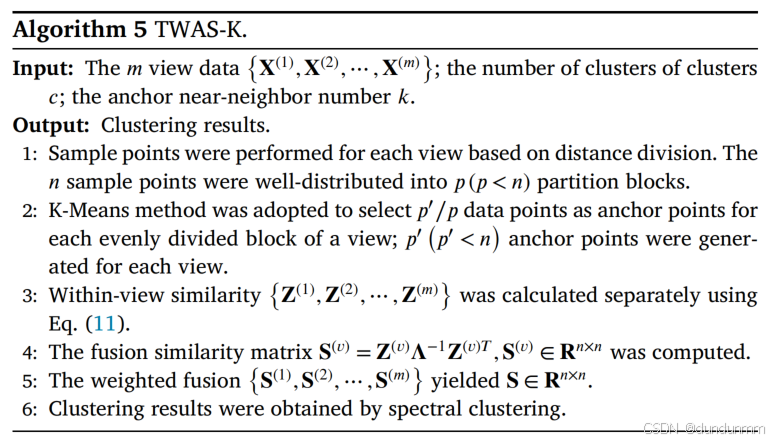
定义 3. TWAS-K
在 TWAS 的第二阶段,若采用K-Means 算法选择锚点,则称之为 TWAS-K。
TWAS-K 采用与 TWAS-R 相同的后续聚类方法,以获得最终的聚类结果。
3.2 两阶段锚点选择
本文提出的两阶段均匀分布锚点选择策略(TWAS)结合了随机方法的高效性与K-Means 方法的代表性,在锚点选择效果与计算成本之间实现了良好的平衡。本节将详细介绍 TWAS 的两个阶段。
3.2.1 全局均匀分布锚点候选划分
设非空数据集 X=[x1,x2,x3,…,xn]T∈Rn×d作为多视图的一个视角。
引入一个特殊的参考点,称为数据原点(data origin),记作 x0=[0,0,0,…,0]∈R1×d。
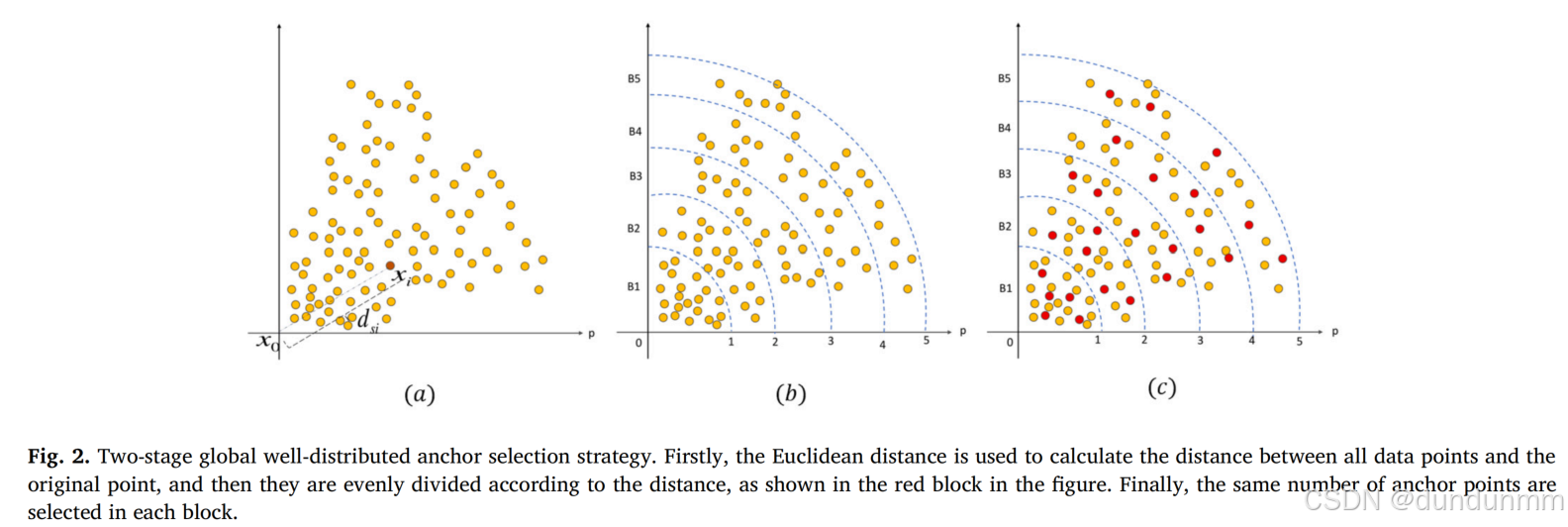
图 2 展示了在包含 100 个数据点的数据集上执行均匀分布锚点选择策略的过程。
-
步骤 1(图 2(a)):计算每个数据点 xi到数据原点 x0的欧几里得距离。
本研究采用欧几里得距离作为度量函数。
-
步骤 2:对所有距离值集合 D={d1,d2,d3,…,dn}按升序排序,得到排序后的集合。
进而,对应的数据集也按升序排序,记作X′={x1′,x2′,x3′,…,xn′}
-
步骤 3:将排序后的数据集划分为 p 个不相交的子集
其中,前 p−1个块每个包含 ⌊n/p⌋个数据点,最后一个块 Bp包含剩余的数据点。
由此可得:
B1∪B2∪⋯∪Bp=X,B1∩B2∩⋯∩Bp=∅在实验中,设定 p=5,即将数据集按从原点距离的大小划分为 B1,B2,B3,B4,B5五个区块,每个区块包含 20 个数据点。划分结果如图 2(b) 所示。
-
步骤 4(图 2(c)):在每个子集内选择局部锚点,采用随机方法或 K-Means 方法,最终的锚点以红色实心圆点表示。
结果表明,所选锚点在整个数据空间中分布均匀,能够更好地代表数据的全局结构。
3.2.2. 局部锚点选择
分别将均匀分布的思想应用于随机锚点选择和K-Means锚点选择。基于全局均匀分布的锚点候选划分策略,数据集被均匀地划分为 B1,B2,…,Bp,然后在每个锚点候选集合 B1,B2,…,Bp中随机选择相同数量的数据点,并合并成锚点集合
U=[u1,u2,u3,…,up′]T∈Rp′×d,(U∈X)
具体描述见算法 1。TWAS-R 使用此方法来选择锚点。

在基于 B1,B2,…,Bp的 K-Means 选择策略中,采用 K-Means 方法在每个锚点候选集内选择相同数量的数据点,并将它们合并到锚点集合
U=[u1,u2,u3,…,up′]T∈Rp′×d,(U∈X)
具体描述见算法 2。TWAS-K 使用此方法来选择锚点。

3.3. 自适应锚点最近邻图学习
给定数据矩阵
X=[x1,x2,x3,…,xn]T∈Rn×d
和锚点集合
U=[u1,u2,u3,…,up′]T∈Rp′×d
其中,n 表示样本数,p′表示锚点数,d 表示特征维度。基于锚点的自适应最近邻图学习问题可建模如下:
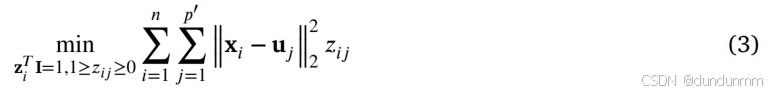
在公式 (3) 中,zij表示锚点 uj作为样本点 xi近邻的概率,其数值大小表示相似度大小。基于锚点相似度图,zij表示第 j 个锚点与第 i 个数据点相邻的概率,且其值大小与距离成反比。
然而,公式 (3) 存在平凡解,即:对于每个数据点 xi,仅有一个最近锚点的相似度值为 1,其余锚点的相似度均为 0。为避免此问题,在公式 (3) 中加入正则化项,得到以下优化目标:
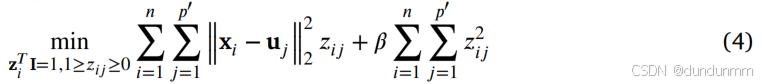
其中,β 为正则化参数。
则公式 (4) 可转换为向量形式:
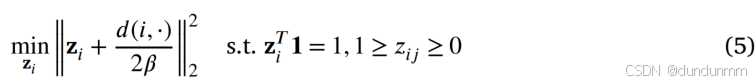
![]()
拉格朗日函数可表示为:
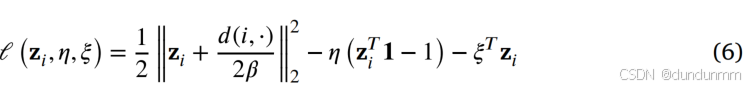
其中,η,ξ为拉格朗日乘子。对 zi求偏导并令其为 0,可得

根据KKT 条件,有 zijξj=0,从而最优解 z^ij 可表示为

假设 d(i,1),d(i,2),…,d(i,p′)按从小到大排序,并结合 k-近邻思想,即在 zi中最多只有 k 个非零值。结合公式 (8) 和约束 z_i^T \mathbf{1} = 1,可得
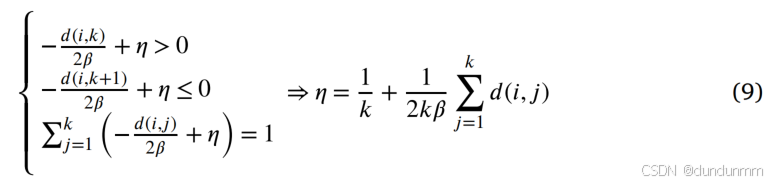
由此可得:
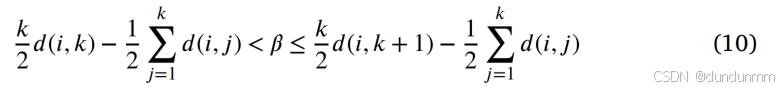
为了使 z^ij对锚点最近邻数 k 具有自适应性,设定参数值:
![]()

3.4. 基于均匀分布锚点选择的谱聚类
通过上一节介绍的方法,可以为每个视图构造锚点相似性图矩阵 Zv。相似性图矩阵 Z用于表示视图内的相似性。然而,Z 不能直接用于谱聚类。先前的研究表明,Z 可用于通过公式 (12) 计算实例相似性图矩阵 S,该矩阵融合了视图内和视图间的相似性信息。
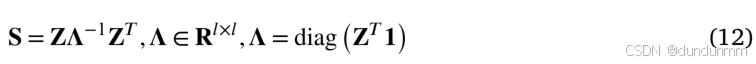
根据谱聚类算法,其目标函数可表示如下:

其中,tr(⋅)表示矩阵的迹,F∈Rn×c是用于输出聚类结果的低维嵌入矩阵,c 是最终的聚类数。L=D−S是拉普拉斯矩阵。根据 Mohar 等人的研究 [46],L 是一个半正定矩阵,D 是度矩阵,其定义如下:

设计了一种基于 TWAS 的大规模多视图谱聚类算法框架,该框架能够充分利用来自多个视图的互补信息,并能对多个视图的相似性矩阵进行加权求和。其中,w(v) 代表视图 v 的实例相似性图矩阵 S(v) 的权重。使用随机算法的 TWAS-R 算法流程如算法 4 所示,而使用 K-Means 算法的 TWAS-K 算法流程如算法 5 所示。
TWAS-R 和 TWAS-K 首先利用 TWAS 生成锚点,然后分别为每个视图生成相应的视图内相似性矩阵 Z(v),并计算实例相似性矩阵 S(v)。初始时,设定所有实例相似性矩阵的权重相等,即:
w(1)=w(2)=⋯=w(m)=1/m
然后,通过以下公式计算融合实例相似性矩阵:
![]()
并更新各实例相似性矩阵的权重参数,更新公式如下:

其中,∥⋅∥F代表矩阵的 Frobenius 范数,用于衡量两个矩阵之间的差异程度。算法会不断重复更新 S和 w(v),直到收敛。
由于图的拉普拉斯矩阵 L 进行特征分解的时间复杂度较高,不适用于大规模数据。因此,从公式 (14) 可得:
L=D−S=I−S
因此,公式 (13) 可重写为:

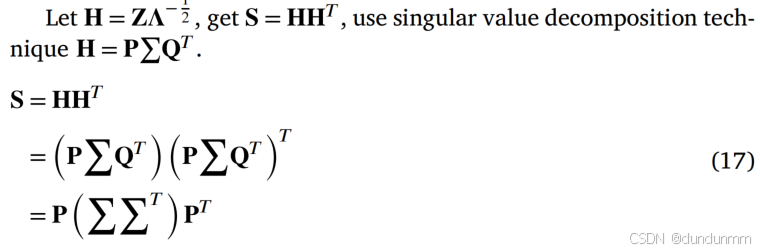


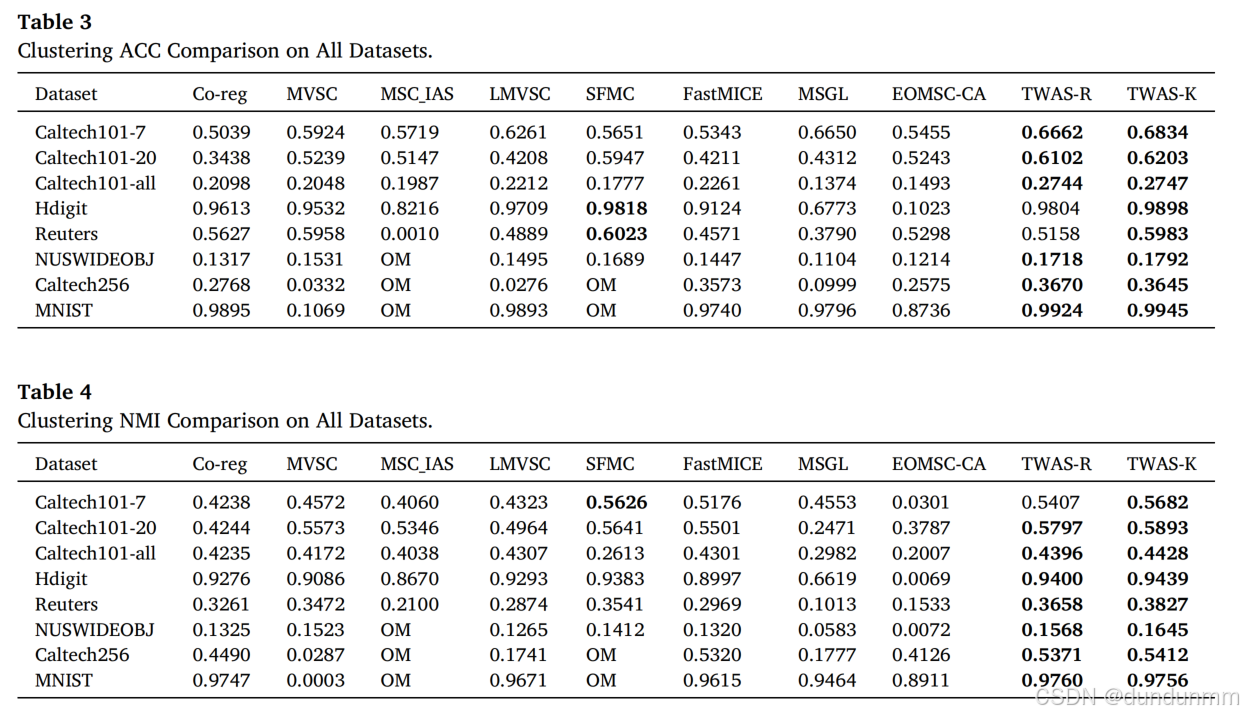
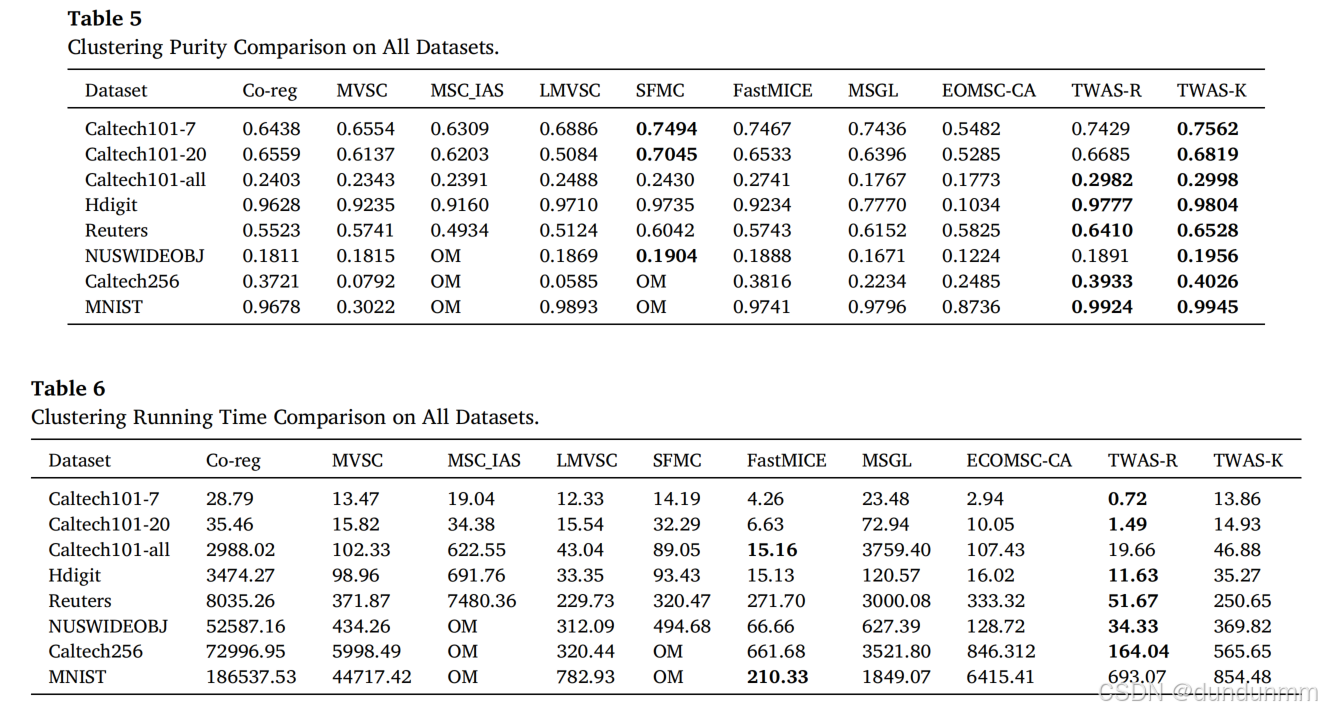
实验
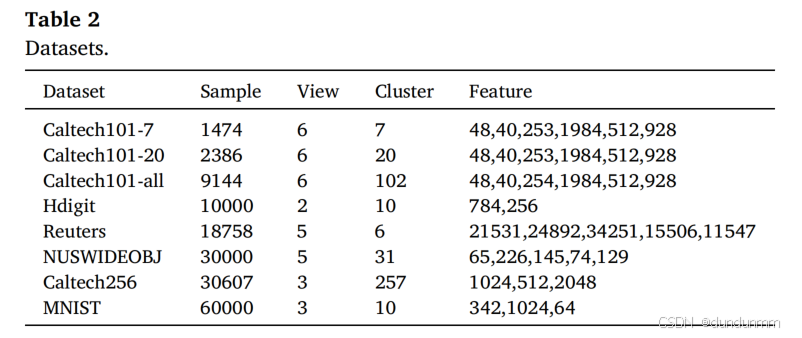
最近想要研究一下锚点的挑选方法,看一下大规模数据集的处理方式。。。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









