









基于 Python 的 mlxtend.frequent_patterns 模块,使用 apriori() 函数获取频繁项集的过程主要包括以下几个步骤:
当然可以,下面是使用 apriori() 获取频繁项集的每一句代码的含义解释:
🔧 1. 安装依赖库
pip install mlxtend
✅ 含义: 安装用于挖掘频繁项集和关联规则分析的 Python 库 mlxtend(Machine Learning Extensions)。
📦 2. 数据准备
import pandas as pd
✅ 含义: 导入 pandas 库,用于处理结构化数据。
dataset = [
['牛奶', '面包', '饼干'],
['牛奶', '尿布', '啤酒', '鸡蛋'],
['面包', '黄油', '尿布', '牛奶'],
['面包', '牛奶', '尿布', '啤酒'],
['面包', '牛奶', '尿布', '鸡蛋']
]
✅ 含义: 定义一个事务型数据列表,每一行表示一位顾客的购买清单,是 Apriori 算法的输入形式(事务集)。
from mlxtend.preprocessing import TransactionEncoder
✅ 含义: 从 mlxtend 中导入 TransactionEncoder,用于将事务型数据转换为适合算法处理的格式。
te = TransactionEncoder()
✅ 含义: 创建一个 TransactionEncoder 对象,用于“编码”交易数据。
te_ary = te.fit(dataset).transform(dataset)
✅ 含义:
-
.fit(dataset):识别所有出现过的商品名称; -
.transform(dataset):将每个事务转成布尔型数组(True/False),表明每个商品是否出现在某一事务中。
df = pd.DataFrame(te_ary, columns=te.columns_)
✅ 含义: 将布尔型数组转为 pandas 的 DataFrame 表格,每列为一个商品,行为一个事务,True/False 表示有/没有购买。
⚙️ 3. 调用 Apriori 算法
from mlxtend.frequent_patterns import apriori
✅ 含义: 导入 apriori 函数,用于生成频繁项集。
frequent_itemsets = apriori(df, min_support=0.5, use_colnames=True)
✅ 含义:
-
df:传入经过编码的数据; -
min_support=0.5:设置最小支持度阈值为 50%,即只保留出现在 50% 以上交易中的项集; -
use_colnames=True:显示商品名称而非索引数字; -
frequent_itemsets:保存频繁项集的结果(包括支持度和项集本身)。
print(frequent_itemsets)
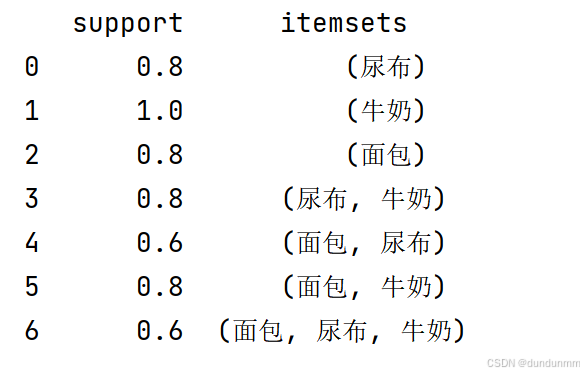
✅ 含义: 输出频繁项集结果表格,显示每个项集及其支持度。
➕ 4. 可选步骤:生成关联规则
from mlxtend.frequent_patterns import association_rules
✅ 含义: 导入 association_rules 函数,用于从频繁项集中挖掘有意义的“如果A就可能B”的规则。
rules = association_rules(frequent_itemsets, metric="confidence", min_threshold=0.7)
✅ 含义:
-
从
frequent_itemsets中生成关联规则; -
metric="confidence":以“置信度”为衡量指标; -
min_threshold=0.7:只保留置信度 ≥ 70% 的规则; -
rules:保存规则的DataFrame,包含前件(antecedent)、后件(consequent)及其指标(支持度、置信度、提升度等)。
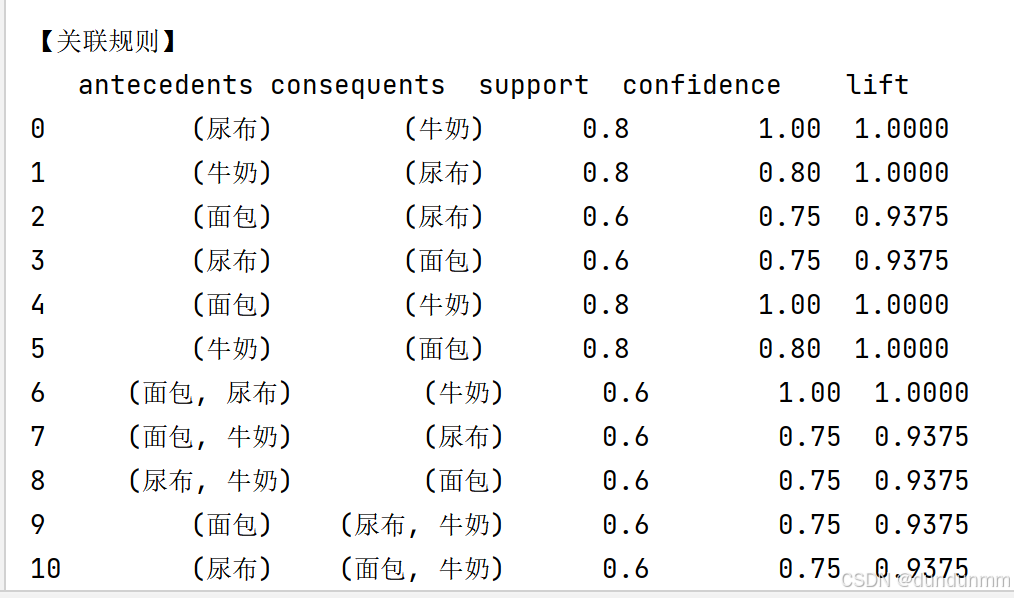
print(rules[['antecedents', 'consequents', 'support', 'confidence', 'lift']])
✅ 含义: 输出结果中每条规则的:
-
antecedents:前件(如果买了...)
-
consequents:后件(那么也可能买...)
-
support:规则中项集出现的比例
-
confidence:前件出现时后件也出现的概率
-
lift:提升度,衡量项集之间的关联强度
✅ Apriori 频繁项集与关联规则挖掘完整脚本(Python + mlxtend)
# 安装依赖包(如果未安装)
# pip install mlxtend pandas
import pandas as pd
from mlxtend.preprocessing import TransactionEncoder
from mlxtend.frequent_patterns import apriori, association_rules
# 1. 定义交易数据(事务型列表)
dataset = [
['牛奶', '面包', '饼干'],
['牛奶', '尿布', '啤酒', '鸡蛋'],
['面包', '黄油', '尿布', '牛奶'],
['面包', '牛奶', '尿布', '啤酒'],
['面包', '牛奶', '尿布', '鸡蛋']
]
# 2. 使用 TransactionEncoder 进行数据编码
te = TransactionEncoder()
te_ary = te.fit(dataset).transform(dataset)
df = pd.DataFrame(te_ary, columns=te.columns_)
# 3. 使用 Apriori 算法挖掘频繁项集
frequent_itemsets = apriori(df, min_support=0.5, use_colnames=True)
print("【频繁项集】")
print(frequent_itemsets)
# 4. 生成关联规则
rules = association_rules(frequent_itemsets, metric="confidence", min_threshold=0.7)
print("\n【关联规则】")
print(rules[['antecedents', 'consequents', 'support', 'confidence', 'lift']])


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









