






拼多多商家在运营店铺的时候,可能会想要看相关数据,那么拼多多数据怎么看?拼多多数据在哪里看呢?
多多情报通免费试用
下边给各位介绍多多情报通的关键功能,也是拼多多店家使用次数较为高的。
一、市场分析
当你不清楚要做什么类目、哪些商品的时候,市场分析就显得很重要的,这儿带来了全部类目地数据统计,包含现阶段某个类目的行业规模,潜力类目、热销类目等等,让你对选品选款有一个判断。
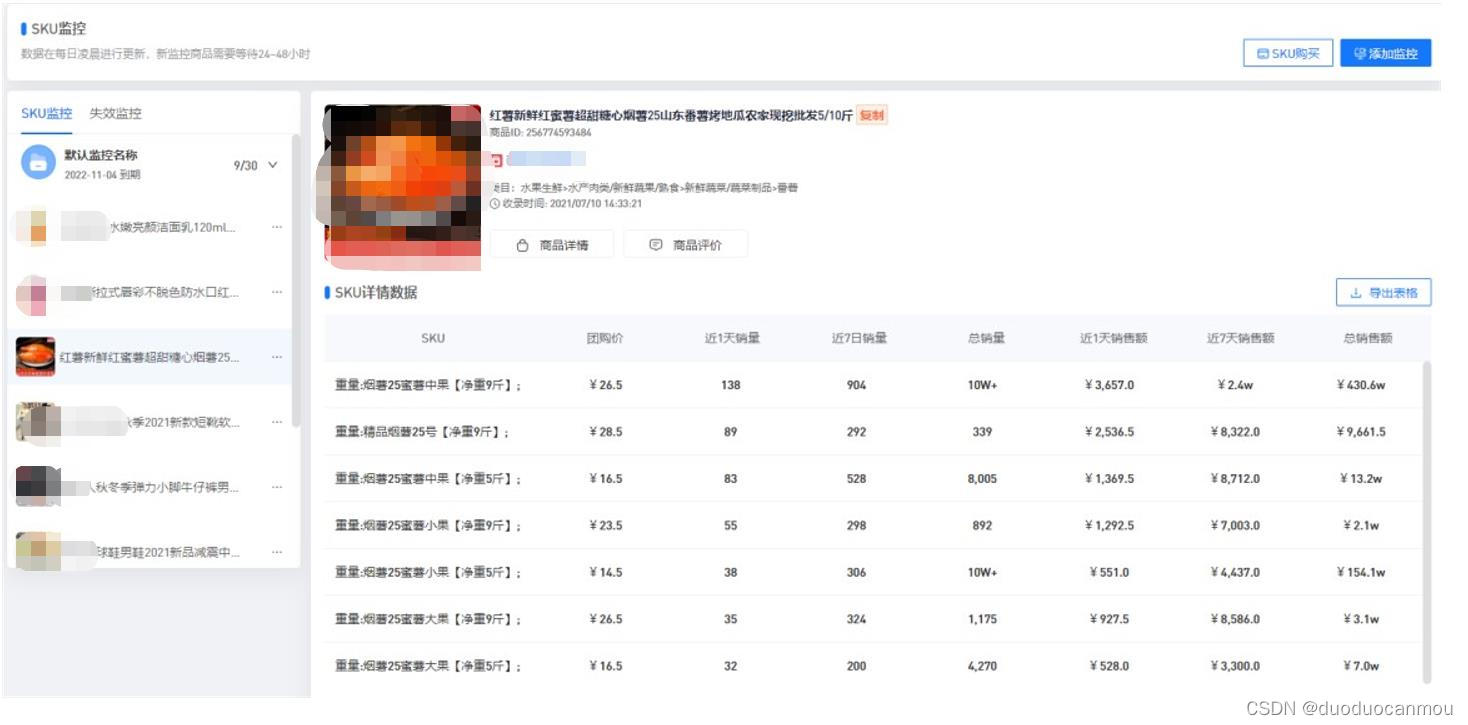
二、竞品监控
除开对行业现状和市场前景的掌握,拼多多店家们还必须多留意竞争者的动态,“多多情报通”的商品分析和店铺监控功能,可以不错的充分发挥这一点,同行的商品定价、销量、SKU设置、入店关键词都能查看到。
三、排名榜
看排行榜的意义在于可以让我们直观了解到做得好的店铺和商品是怎样的,方便我们学习别人的优秀经验。还有就是潜力爆款榜,让大家可以更好地选出爆款产品,很实用。

















 1638
1638

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









