







昨天晚上写作业写到太晚了,所以今早来补上本来昨晚该发的博客~
这篇博客首先写一下分组转换方法transform
(1)数据分组转换----transform
创建Dataframe,并按‘key1’分组求均值
df = pd.DataFrame({'data1':np.random.rand(5),
'data2':np.random.rand(5),
'key1':list('aabba'),
'key2':['one','two','one','two','one']})
k_mean = df.groupby('key1').mean()
print(df)
print(k_mean)
输出结果:

合并df和k_mean,并在每个index添加前缀‘mean_’,通过add_prefix来实现
print(pd.merge(df,k_mean,left_on='key1',right_index=True).add_prefix('mean_')) # .add_prefix('mean_'):添加前缀
输出结果:

按照‘key2’分组求均值,按照‘key2’分组,并进行分组转换,使data1,data2的每个位置元素取对应分组列的均值
print(df.groupby('key2').mean()) # 按照key2分组求均值
print(df.groupby('key2').transform(np.mean))
输出结果:

(2)一般化Groupby方法:apply
创建Dataframe
df = pd.DataFrame({'data1':np.random.rand(5),
'data2':np.random.rand(5),
'key1':list('aabba'),
'key2':['one','two','one','two','one']})
print(df)
输出结果:

使用apply,输出Dataframe的数据信息
print(df.groupby('key1').apply(lambda x: x.describe()))
这里的 lambda为匿名函数
输出结果:

我们也可以自定义某些函数,再通过apply应用到Dataframe中
def f_df1(d,n):#返回排序后的前n行数据
return(d.sort_index()[:n])
def f_df2(d,k1):#返回分组后表的k1列,结果为Series,层次化索引
return(d[k1])
print(df.groupby('key1').apply(f_df1,2),'\n')
print(df.groupby('key1').apply(f_df2,'data2'))
print(type(df.groupby('key1').apply(f_df2,'data2')))
输出结果:

(3)数据透视表----pivot_table
创建数据
date = ['2017-5-1','2017-5-2','2017-5-3']*3
rng = pd.to_datetime(date)
df = pd.DataFrame({'date':rng,
'key':list('abcdabcda'),
'values':np.random.rand(9)*10})
print(df)
输出结果:

数据透视
print(pd.pivot_table(df, values = 'values', index = 'date', columns = 'key', aggfunc=np.sum)) # 也可以写 aggfunc='sum'
输出结果:

这里要注意它的一些参数:
data:Dataframe对象
values:要聚合的列或列的列表
index:数据透视表的index,从原数据的列中筛选
aggfunc:用于聚合的函数,默认为numpy.mean,支持numpy的计算方法
以date,key共同做数据透视,值为values,统计不同(date,key)情况下values的平均值
print(pd.pivot_table(df, values = 'values', index = ['date','key'], aggfunc=len))
输出结果:

(4)交叉表–crosstab
在默认情况下,crosstab计算因子的频率表,比如用于str的数据透视分析
创建Dataframe
df = pd.DataFrame({'A': [1, 2, 2, 2, 2],
'B': [3, 3, 4, 4, 4],
'C': [1, 1, np.nan, 1, 1]})
print(df)
输出结果:

接收两个Series,提供一个频率表,用A的唯一值,统计B的唯一值出现的次数
print(pd.crosstab(df['A'],df['B']))
输出结果:
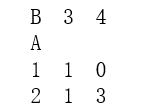
输出结果表示,当A=1,B=3,时,在原Dataframe中出现一次
对出现次数归一化
print(pd.crosstab(df['A'],df['B'],normalize=True))
输出结果:

根据‘C’列聚合
相当于以A和B界定分组,计算出每组中第三个系列C的值
print(pd.crosstab(df['A'],df['B'],values=df['C'],aggfunc=np.sum))
这里要注意一些参数:
values:可选,根据因子聚合的值数组
aggfunc:可选,如果未传递values数组,则计算频率表,如果传递数组,则按照指定计算
输出结果:

可以用过margins添加行、列边距
print(pd.crosstab(df['A'],df['B'],values=df['C'],aggfunc=np.sum, margins=True))
输出结果:

关注欢喜,走向成功~















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









