







spacy是一个辅助自然语言处理的工具库。
spacy能做什么
它集成了各种实用的句子分析功能,包括分词、词性分析、词性还原等等,所有功能特性可参考官网 spacy-101的features一章,有Tokenization、Part-of-speech (POS) Tagging等等。
如何安装
它易于安装。参考官网 Install spaCy,完整的spacy安装分两步:
1. 用pip安装spacy。
2. 根据你要分析的语言,安装语言模型。比如对于英语,可以安装en_core_web_sm。因为网络原因,这条命令大概率失败,可参考NLP Spacy中en_core_web_sm安装问题,及最新版下载地址下载语言模型。
案例 分词功能
阅读官网 spacy-101的Tokenization一节,可以了解该库的分词功能。由于某个rnn教程用到了它的分词功能,笔者会试图翻译这一节。
在处理时,spacy会先将文本分词,比如把它分成单词、标点符合,等等。比如句子尾部的标点符号应当被分开,而"U.K."应当维持一个单词。每个Doc对象包含了一些token对象,可供遍历:
import spacy
nlp = spacy.load("en_core_web_sm")
doc = nlp("Apple is looking at buying U.K. startup for $1 billion")
for token in doc:
print(token.text)
它们会按顺序被分成下图的11个单词。

首先,文本被以空格分割,类似于text.split(' ')。然后分词器会从左向右处理文本,对于每个子串,它会作两个检查:
- 这个字串是否符合例外规则?比如"Don’t"不包含空格,但应当被分割为两个单词,“do"和"n’t”,然而"U.K."应当始终是一个单词。
- 是否有前缀、后缀、中缀应当被分割?比如各种标点符号,如逗号、句号、中划线、引号。
如果有符合的情况,那么就会触发规则,然后分词器会从新分割的字串继续处理。这样,spacy有能力分割复杂、多层的单词,比如缩写与各种标点符号的组合。
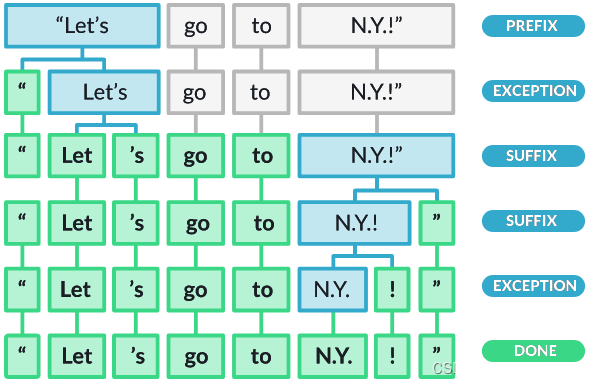
如图所示:
- 先按空格分割,得到第一行
- 再触发exception规则,对作为前缀prefix的双引号分割,得到第二行
- 再触发suffix规则,对作为后缀suffix的单引号分割,得到第三行
- 再触发suffix规则,对作为后缀suffix的双引号分割,得到第四行
- 再对触发exception规则,对感叹号分割,得到第五行
- 再分割得到最后一行
标点符号规则通常是宽泛的,分词器的例外规则很大程度上依赖于语言特性。这就是为什么每种语言都有其特有的子类,比如英语或者德语,它们各自加载一系列硬编码的数据和例外规则。
由于精力关系,笔者不会去翻译更多例子。请读者自己继续阅读英文的教程。















 2508
2508











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









