







前言
数组是一种引用数据类型.
数组引用变量只是一个引用.
数组元素和数组变量在内存里是分开存放的.
下面将深入介绍数组在内存中的运行机制.
内存中的数组
数组引用变量只是一个引用.
这个引用变量可以指向任何有效的内存.
只有当该引用指向有效内存后, 才可以通过该数组变量来访问数组元素.与所有引用变量相同的是, 引用变量是 访问真实对象 的根本方式.
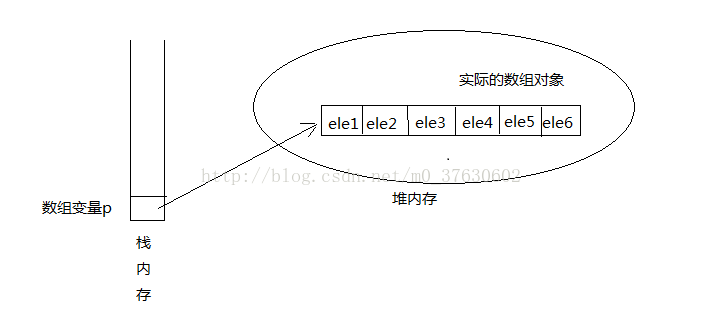
也就是说, 如果希望在程序中访问数组对象本身, 则只能通过这个数组的引用变量来访问它.实际的数组对象被存放在堆(heap)内存中.
如果引用该数组对象的 数组引用变量 是一个局部变量, 那么它被存储在栈(stack)内存中.
下面我们看个示意图:
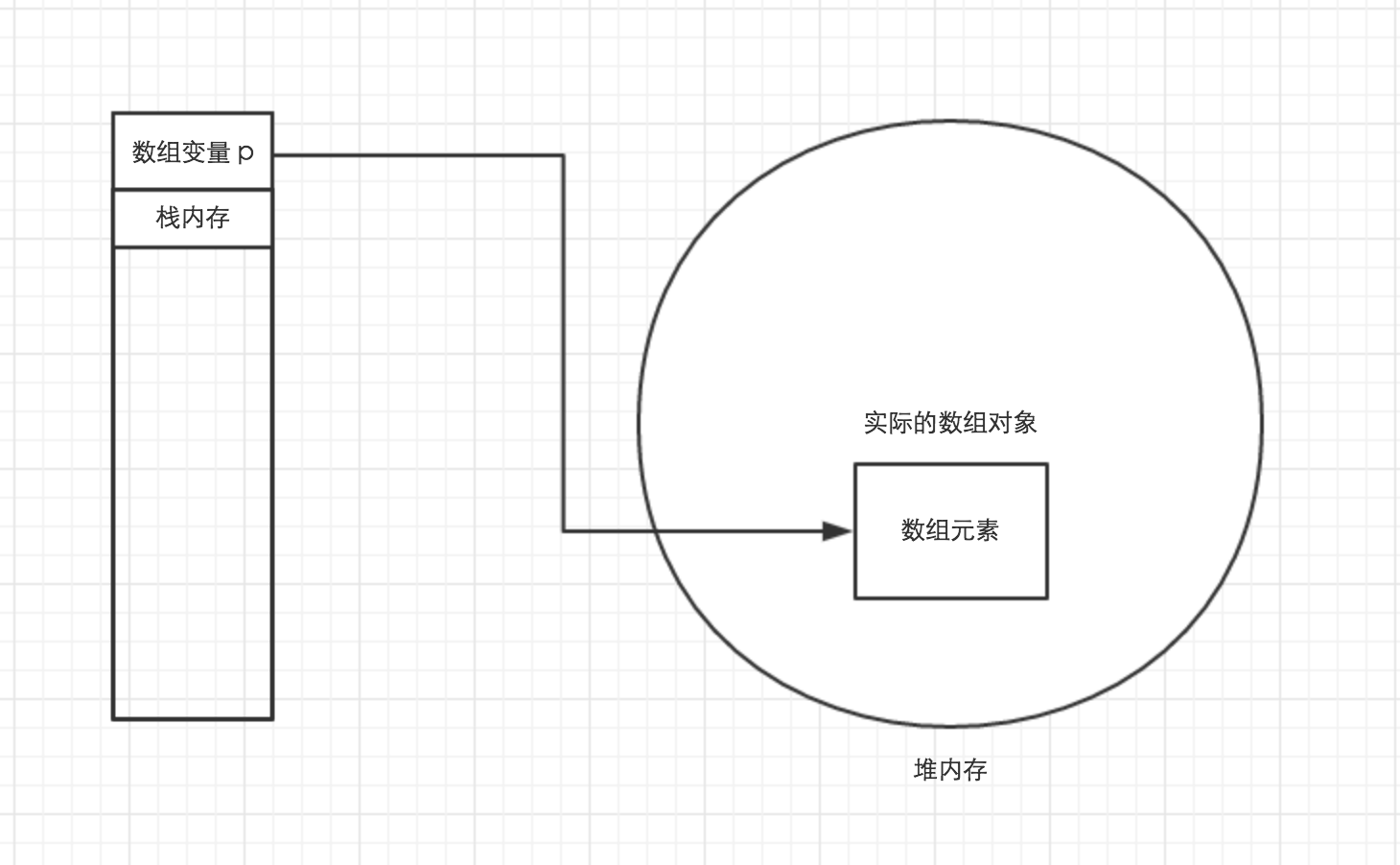
首先, 我们想知道 什么是栈内存, 什么是堆内存. 点我查看
通过上面的解答, 我们大概可以总结为:
- 栈内存用于存放 地址
- 堆内存用于存放 具体的数据
如果映射到现实中的话, 栈内存就是记录你家地址信息的. 堆内存就是你家.
快递员想要把东西送到你家. 知道你家地址后, 就可以找到你家. 嗯. 大概就是这么个意思. 不过肯定更复杂. 不过当下来讲, 先简单了解下就行了.那么我们还可以再深入一点.
为什么有 栈内存 和 堆内存 之分呢??当一个方法执行时, 会建立 属于自己的内存栈.
在这个方法内定义的变量将会逐个放入这块栈内存里..
当方法结束时, 属于这个方法的 栈内存 也将会被系统销毁.在程序创建一个对象时, 这个对象将被保存到 堆内存 中. 为了方便反复利用.
堆内存中的对象不会因方法的结束而被系统销毁.
因为这个对象还可以被其它引用变量引用 (在方法的参数传递时很常见).
只有当这个对象没有被任何引用变量引用时, 系统才会把这个对象销毁.映射到现实中, 我们可以这么看待这一过程.
你家门前的路 其名字 等等都是可以变的. 就算路销毁了, 你的房子并不会被销毁. 路就是栈内存, 你的房子就是堆内存.
除非你家门前再也不会修路, 同时你也不继续住这个房子了, 那么这个房子就变得没有了意义. 被销毁也就自然了.举得例子可能不太恰当, 但是希望你能明白这其中意义的不同.
即使你现在不太能够理解, 也没关系.如果堆内存中的数组 不再有任何引用变量 指向自己.
则这个数组将成为垃圾, 该数组所占的内存将会被系统回收.数组是一种引用数据类型,数组引用变量只是一个引用,数组元素和数组变量在内存里是分开存放的。实际的数组对象被存储在堆(heap)内存中,如果引用该数组对象的数组引用变量是一个局部变量,那么它被存储在栈中。数组在内存中的存储示意图:
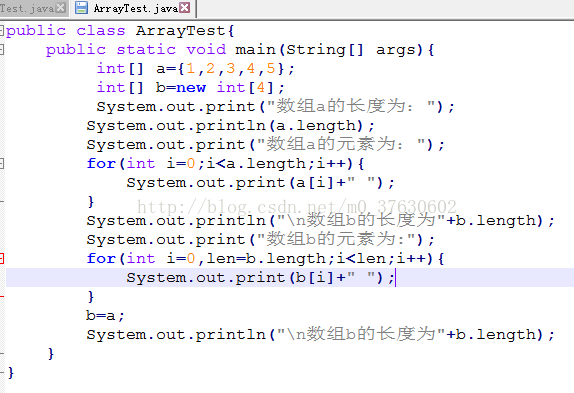
通过一个例子来说明一下:
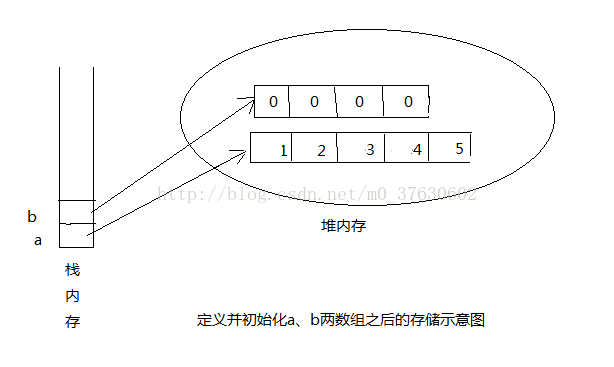
有这样一段代码,首先定义了两个数组a和b,分别初始化两个数组,输出数组的长度和元素,然后将a数组赋值给b数组,再输出数组b的长度。
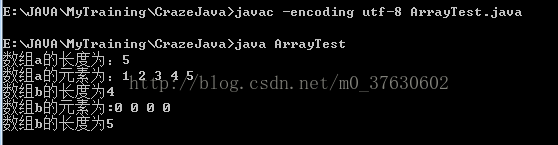
执行结果如下:
从结果中可以看出,在初始化b数组时没有给数组b赋值,系统默认赋值为0.另外,可以看到当a数组赋值给b之后,b的长度为5,看起来似乎数组的长度发生了变化,其实这只是一个假象。
要知道:定义并初始化一个数组后,在内存中分离了两个空间,一个用户存放数组本身,另一个用于存放数组引用变量,结合例子可以知道,系统在内存中一共产生了4个内存区,其中栈内存中有两个引用变量,分别为a和b,堆内存中也有两个内存区,分别用于指向a引用和b引用所指向的数组本身。如图所示:
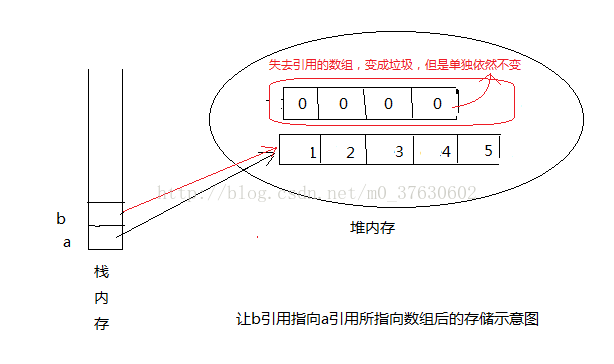
当执行b=a这条语句之后,系统将会把a的值赋给b,由于a和b都是引用变量,存储的都是地址,因此把a赋值给b之后,就是让b指向a所指向的地址。此时内存中的存储结构如下:
从上面的这个示意图可以看出,a和b都引用了第一个数组,此时第二个数组失去了引用,变成了垃圾,只有等待垃圾回收机制来回收,但是它的长度依然不变,直到它彻底消失。















 3499
3499

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









