







Consumer客户端
1 消费者模型
在开始编码之前, 我们先回顾一下一些基本概念。 在Kafka中, 每个topic被分成一组称为Partitions的logs。 Producer向这些logs的末尾写入消息, Consumer则自己按自己的节奏读取log。 Kafka通过在一个Consumer Group中分配Partitions来伸缩topic的消费, Consumer Group是一组有同样Group id的consumers。 下图表示的是一个拥有3个分区的topic, 以及一个有两个成员的Consumer Group。 每一个分区都只会分配给组内的一个成员。
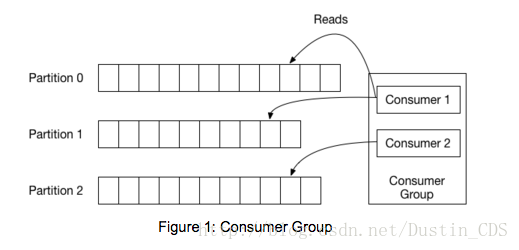
旧的Consumer依赖于Zookeeper来进行Group管理, 新的消费者使用kafka内部的Group coordination协议。 对于每个Group, brokers中的一个被选为Group coordinator。 这个coordinator负责管理Group的状态, 它的主要工作是当新的成员加入, 或者原本的成员离开, 或者topic的元数据发生了改变时, 协调Partition分配。 重新分配Partition这个过程被称为rebalancing the Group。
当Group第一次初始化时, Consumer通常从分区的最开始或者最末尾开始读取。 每个Partition log中的消息都是按顺序读取。 随着Consumer的读取, 它将会commit它所成功处理的message的offset。 例如下图中, Consumer的位置位于offset 6, 上一次commit的offset为1。
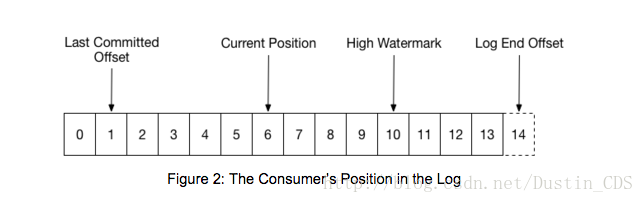
当一个Partition被重分配给组内的另一个Consumer, 其最初位置会被设置成上一次commit的offset。 如果上例中的Consumer突然奔溃了, 那么接管这个Partition的另外一个组成员会从offset 1继续消费。 在这种情况下,它会重新处理上一次提交位置到消费者奔溃的位置6的消息。
这张图还有两个log中比较重要的位置。 log end offset是最后一条写入log的message的offset, 而high watermark是最后一条message成功复制到所有的log replica的message offset。 从Consumer的角度来看, 所知道的最主要的事情就是其最多能够读到high watermark的message。 这能够阻止Consumer读取到未被复制到其他broker的, 可能会丢失的message。
2 配置和初始化
开始使用Consumer之前, 需要将kafka-clients依赖加入到你的项目中。
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>0.9.0.0-cp1</version>
</dependency>12345Consumer使用一个Properties file来进行构建。 以下提供了使用Consumer Group所需要的最小配置。
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("group.id", "consumer-tutorial");
props.put("key.deserializer", StringDeserializer.class.getName());
props.put("value.deserializer", StringDeserializer.class.getName());
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);123456和之前的Consumer, Producer一样, 我们需要为Consumer提供一个broker的初始化列表, 以用于发现集群中其他的broker。 这个配置并不需要提供所有的broker, client会从给定的配置中发现所有的当前存活的broker。 这里我们假设broker运行在本地, 同时Consumer还需要知道如何反序列化message key和value。 最后, 为了加入Consumer Group, 我们需要配置一个Group id。 随着教程的继续, 我们会介绍更多的配置。
3 Topic订阅
为了开始消费, 你必须指定你的应用需要读取的topics, 在下面的例子中, 我们订阅了topic foo和bar。
Consumer.subscribe(Arrays.asList(“foo”, “bar”));订阅之后, Consumer会与组内其他Consumer协调来获取其分区分配。 这都是在你开始消费数据时自动处理的。 后面我们会说明如何使用assign api来手动分配分区, 但是要注意的是, 不能同时混合使用自动和手动的分配。
subscribe方法并不是递增的: 你必须包含所有你想要消费的topics。 你可以在任何时刻改变你想消费的topic集, 当你调用subscribe时, 之前订阅的topics列表会被新的列表取代。
3 基本的Poll事件循环
3.1 Consumer使用了NIO技术
Consumer需要能够并行获取数据, 在众多brokers中获取多个topic的多个分区消息。 为了实现这个目的, Consumer API的设计成风格类似于unix中的poll或者select调用: 一旦topic注册了, 所有的coordination, rebalancing和data fetch都是由一个处于循环中的poll调用来驱动。 这样就提供了一个能在一个线程里处理所有的IO的简单有效的实现。
3.2 启动Poll Loop
在你订阅一个topic之后, 你需要启动这个event loop以获得Partition分配和开始获取数据。 听起来很复杂, 但是所有你需要做的就只有调用poll, 然后Consumer客户端本身负责处理其他的工作。 每一次poll调用都会返回从所分配的Partition获取的一组消息(也许是空的)。 下面的例子展示了一个基本的poll循环, 打印获取的records的offset和value。
try {
while (running) {
ConsumerRecords<String, String> records = Consumer.poll(1000); // 超时时间1000毫秒
for (ConsumerRecord<String, String> record : records)
System.out.println(record.offset() + ": " + record.value());
}
} finally {
Consumer.close();
}poll API根据当前的位置返回records,当Group第一次创建时, 消费开始的位置会被根据reset policy(一般设置成从每个分区的最早的offset或者最新的offset开始)来设置。 只要Consumer开始提交offset, 那么之后的rebalance都会重置消费开始位置到最新的被提交的offset。 传递给poll的参数是Consumer在当前位置等待有record返回时需要被阻塞的时间。 一旦有record时, Consumer会立即返回, 如果没有record, 它将会等待直到超时。
Consumer被设计成只在自己的线程中运行, 在没有外部同步措施的情况下, 在多线程中使用时不安全的, 同时也不建议这样做。 在这个例子中, 我们使用了一个flag来使得当应用停止时能够从循环中跳出。 当这个flag被另一个线程设置成false时, pool返回时循环会跳出, 无论返回什么record, 处理过程都会结束。这个的例子使用了一个相对较少的超时时间, 以使得关闭Consumer并不会有太大的延时。
你还可以设置一个较长的timeout, 并且使用wakeup API来使得其从循环中跳出。
try {
while (true) {
ConsumerRecords<String, String> records = Consumer.poll(Long.MAX_VALUE);
for (ConsumerRecord<String, String> record : records)
System.out.println(record.offset() + “: ” + record.value());
}
} catch (WakeupException e) {
// ignore for shutdown
} finally {
Consumer.close();
}我们将timeout改为了Long.MAX_VALUE, 意味着Consumer会一直阻塞直到有record返回。 和前面设置flag不同, 用于触发shutdown的线程可以调用Consumer.wakeup()来中断一次poll, 使其抛出WakeupExection。 这个API是线程安全的。 注意如果当前没有活跃的poll, 那么异常会在下一次poll调用时抛出。 在这个例子中, 我们捕捉这个异常, 阻止其继续传播。
4 完整代码
在接下来的例子中, 我们将所有的代码块放到一起来构建一个task, 初始化Consumer, 订阅一个topic列表, 并且执行poll调用直到外部关闭它。
public class 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 4773
4773











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









