







- bLSM 提出了一种新的合并调度器来限制写入延迟,从而保持稳定的写入吞吐量,并且还使用 bloom 过滤器来提高性能。
Data management workloads are increasingly write-intensive and subject to strict latency SLAs. This presents a dilemma:
Update in place systems have unmatched latency but poor write throughput. In contrast, existing log structured techniques improve write throughput but sacrice read performance and exhibit unacceptable latency spikes.
We begin by presenting a new performance metric: read fanout, and argue that, with read and write amplication, it better characterizes real-world indexes than approaches such as asymptotic analysis and price/performance.
We then present bLSM, a Log Structured Merge (LSM) tree with the advantages of B-Trees and log structured approaches: (1) Unlike existing log structured trees, bLSM has near-optimal read and scan performance, and (2) its new "spring and gear" merge scheduler bounds write latency without impacting throughput or allowing merges to block writes for extended periods of time. It does this by ensuring merges at each level of the tree make steady progress with- out resorting to techniques that degrade read performance.
We use Bloom lters to improve index performance, and nd a number of subtleties arise. First, we ensure reads can stop after nding one version of a record. Otherwise, frequently written items would incur multiple B-Tree lookups.
Second, many applications check for existing values at insert. Avoiding the seek performed by the check is crucial.
数据管理工作负载越来越多的写入密集型工作,并且要遵守严格的延迟SLA。这带来了一个难题:
就地更新系统具有无与伦比的延迟,但写入吞吐量很差。相反,现有的日志结构化技术可提高写入吞吐量,但会牺牲读取性能,并且会出现不可接受的延迟峰值。
我们首先提出一种新的性能指标:读取扇出,并认为通过读写放大,它比渐进分析和价格/性能方法更好地刻画了现实世界中的指标。
然后,我们介绍bLSM,这是一种具有B树和日志结构化方法优点的日志结构合并(LSM)树:(1)与现有的日志结构树不同,bLSM具有近乎最佳的读取和扫描性能,以及(2)其新的“ spring and gear”合并调度程序在不影响吞吐量的情况下限制了写入延迟,也不允许合并在更长的时间内阻止写入。它通过确保在树的每个级别上的合并都能稳步进行,而无需诉诸降低读取性能的技术来做到这一点。
我们使用Bloom筛选器来改善索引性能,并且会发现许多细微差别。首先,我们确保找到记录的一个版本后可以停止读取。否则,经常写入的项目将导致多次B-Tree查找。
其次,许多应用程序会在插入时检查现有值。避免由检查执行的查找至关重要。
1. INTRODUCTION
Modern web services rely upon two types of storage for small objects. The rst, update-in-place, optimizes for random reads and worst case write latencies. Such stores are used by interactive, user facing portions of applications.
The second type is used for analytical workloads and emphasizes write throughput and sequential reads over latency or random access. This forces applications to be broken into \fast-path" processing, and asynchronous analytical tasks.
This impacts end-users (e.g., it may take hours for machine learning models to react to users' behavior), and forces operators to manage redundant storage infrastructures.
Such limitations are increasingly unacceptable. Cloud computing, mobile devices and social networking write data at unprecedented rates, and demand that updates be synchronously exposed to devices, users and other services.
Unlike traditional write-heavy workloads, these applications have stringent latency SLAs.
These trends have two immediate implications at Yahoo!.
First, in 2010, typical low latency workloads were 80-90% reads. Today the ratio is approaching 50%, and the shift from reads to writes is expected to accelerate in 2012. These trends are driven by applications that ingest event logs (such as user clicks and mobile device sensor readings), and later mine the data by issuing long scans, or targeted point queries.
Second, the need for performant index probes in write optimized systems is increasing. bLSM is designed to be used as backing storage for PNUTS, our geographically-distributed key-value storage system [10], and Walnut, our next-generation elastic cloud storage system [9].
1.引言
现代Web服务依靠两种类型的小对象存储。第一个是就地更新,它针对随机读取和最坏情况下的写入延迟进行了优化。此类存储由应用程序的交互式,面向用户的部分使用。
第二种类型用于分析工作负载,并强调写入吞吐量和在延迟或随机访问上的顺序读取。这迫使应用程序分成“快速路径”处理和异步分析任务。
这会影响最终用户(例如,机器学习模型可能需要数小时才能对用户的行为做出反应),并迫使运营商管理冗余存储基础架构。
这种限制越来越难以接受。云计算,移动设备和社交网络以前所未有的速度写入数据,并要求将更新同步显示给设备,用户和其他服务。
与传统的写繁重工作负载不同,这些应用程序具有严格的延迟SLA。
这些趋势对Yahoo!有两个直接的影响。
首先,在2010年,典型的低延迟工作负载是80-90%的读取。如今,这一比例已接近50%,预计从2012年到现在,读和写的转变将加速。这些趋势是由应用程序驱动的,这些应用程序提取事件日志(例如用户点击和移动设备传感器读数),然后通过发出长时间扫描或目标点查询。
其次,在写优化系统中对高性能索引探针的需求正在增加。 bLSM旨在用作PNUTS(我们的地理分布键值存储系统[10])和Walnut(我们的下一代弹性云存储系统[9])的后备存储。
Historically, limitations of log structured indexes have presented a trade off. Update-in-place storage provided superior read performance and predictability for writes; log-structured trees traded this for improved write throughput.
This is re ected in the infrastructures of companies such as Yahoo!, Facebook [6] and Google, each of which employs InnoDB and either HBase [1] or BigTable [8] in production.
This paper argues that, with appropriate tuning and our merge scheduler improvements, LSM-trees are ready to supplant B-Trees in essentially all interesting application scenarios. The two workloads we describe above, interactive and analytical, are prime examples: they cover most applications, and, as importantly, are the workloads that mostfrequently push the performance envelope of existing systems.
Inevitably, switching from B-Trees to LSM-Trees entails a number of tradeoffs, and B-Trees still outperform logstructured approaches in a number of corner cases. These are summarized in Table 1.
从历史上看,日志结构化索引的局限性是一个折衷方案。就地更新存储可提供卓越的读取性能和写入可预测性;日志结构树对此进行了交换,以提高写入吞吐量。
这在Yahoo!,Facebook [6]和Google等公司的基础架构中得到了体现,这些公司的基础架构在生产中均使用InnoDB以及HBase [1]或BigTable [8]。
本文认为,通过适当的调整和我们的合并调度程序的改进,LSM树准备好在基本上所有有趣的应用场景中取代B树。我们上面描述的两个工作负载(交互和分析)是主要的示例:它们涵盖了大多数应用程序,并且重要的是,这些工作负载最经常推动现有系统的性能。
不可避免地,从B树切换到LSM树需要进行许多折衷,并且B树在许多极端情况下仍优于对数结构化方法。这些总结在表1中。

Concretely, we target "workhorse" data management systems that are provisioned to minimize the price/performance of storing and processing large sets of small records.
Serving applications written atop such systems are dominated by point queries, updates and occasional scans, while analytical processing consists of bulk writes and scans. Unlike B-Trees and existing log structured systems, our approach is appropriate for both classes of applications.
Section 2 provides an overview of log structured index variants. We explain why partitioned, three level trees with Bloom filters (Figure 1) are particularly compelling.
Section 3 discusses subtleties that arise with the base approach, and presents algorithmic tweaks that improve read, scan and insert performance.
Section 4 describes our design in detail and presents the missing piece: with careful scheduling of background merge tasks we are able to automatically bound write latencies without sacricing throughput.
Beyond recommending and justifying a combination of LSM-Tree related optimizations, the primary contribution of this paper is a new class of merge schedulers called level schedulers. We distinguish level schedulers from existing partition schedulers and present a level scheduler we call the spring and gear scheduler.
In Section 5 we conrm our LSM-Tree design matches or outperforms B-Trees on a range of workloads. We compare against LevelDB, a state-of-the-art LSM-Tree variant that has been highly optimized for desktop workloads and makes different tradeoffs than our approach. It is a multi-level tree that does not make use of Bloom lters and uses a partition scheduler to schedule merges. These differences allow us to isolate and experimentally validate the effects of each of the major decisions that went into our design.
具体来说,我们的目标是“主力”数据管理系统,该系统的配置旨在最大程度地降低存储和处理大量小型记录的价格/性能。
在此类系统上编写的服务应用程序主要由点查询,更新和偶发扫描组成,而分析处理则由批量写入和扫描组成。与B树和现有的日志结构化系统不同,我们的方法适用于两种类型的应用程序。
第2节概述了日志结构化索引变量。我们解释了为什么具有Bloom过滤器的分区三级树(图1)特别引人注目。
第3节讨论了基本方法带来的细微差别,并提出了提高读取,扫描和插入性能的算法调整。
第4节详细介绍了我们的设计,并提出了缺少的部分:通过精心安排后台合并任务,我们能够自动限制写延迟,而无需牺牲吞吐量。
除了推荐和证明与LSM-Tree相关的优化的组合之外,本文的主要贡献是一类新的合并调度程序,称为级别调度程序。我们将级别调度程序与现有分区调度程序区分开,并介绍一个称为弹簧和齿轮调度程序的级别调度程序。
在第5节中,我们确定我们的LSM-Tree设计在一系列工作负载上匹配或优于B-Tree。我们将LevelDB与最先进的LSM-Tree变体进行了比较,该变体已针对桌面工作负载进行了高度优化,并与我们的方法进行了权衡。它是一个多级树,不使用Bloom lters,而是使用分区调度程序来调度合并。这些差异使我们能够隔离和实验验证设计中每个主要决策的效果。
2. BACKGROUND
Storage systems can be characterized in terms of whether they use random I/O to update data, or write sequentially and then use additional sequential I/O to asynchronously maintain the resulting structure. Over time, the ratio of the cost of hard disk random I/O to sequential I/O has increased, decreasing the relative cost of the additional sequential I/O and widening the range of workloads that can benet from log-structured writes.
As object sizes increase, update-in-place techniques begin to outperform log structured techniques. Increasing the relative cost of random I/O increases the object size that determines the "cross over" point where update-in-place techniques outperform log structured ones. These trends make log structured techniques more attractive over time.
Our discussion focuses on three classes of disk layouts: update-in-place B-Trees, ordered log structured stores, and unordered log structured stores. B-Tree read performance is essentially optimal. For most applications they perform at most one seek per read. Unfragmented B-Trees perform one seek per scan. However, they use random writes to achieve these properties. The goal of our work is to improve upon B-Tree writes without sacricing read or scan performance.
Ordered log structured indexes buer updates in RAM, sort them, and then write sorted runs to disk. Over time, the runs are merged, bounding overheads incurred by reads and scans. The cost of the merges depends on the indexed data's size and the amount of RAM used to buer writes.
Unordered log structured indexes write data to disk immediately, eliminating the need for a separate log. The cost of compacting these stores is a function of the amount of free space reserved on the underlying device, and is independent of the amount of memory used as cache. Unordered stores typically have higher sustained write throughput than ordered stores (order of magnitude dierences are not uncommon [22, 27, 28, 32]). These benets come at a price:unordered stores do not provide efficient scan operations.
Scans are required by a wide range of applications (and exported by PNUTS and Walnut), and are essential for efficient relational query processing. Since we target such use cases, we are unable to make use of unordered techniques.
However, such techniques complement ours, and a number of implementations are available (Section 6). We now turn to a discussion of the tradeos made by ordered approaches.
2.背景
可以根据存储系统是使用随机I / O更新数据还是顺序写入,然后使用其他顺序I / O异步维护生成的结构来表征存储系统。随着时间的流逝,硬盘随机I / O与顺序I / O的成本之比增加了,从而降低了其他顺序I / O的相对成本,并扩大了日志结构写入可能带来的工作负载范围。
随着对象大小的增加,就地更新技术开始胜过日志结构化技术。增加随机I / O的相对成本会增加确定“交叉”点的对象大小,在该点上,就地更新技术的性能优于日志结构化技术。这些趋势使日志结构化技术随着时间的推移更具吸引力。
我们的讨论集中在三类磁盘布局上:就地更新B树,有序日志结构化存储和无序日志结构化存储。
B树的读取性能本质上是最佳的。对于大多数应用程序,每次读取最多执行一次寻道。未碎片化的B树每次扫描执行一次搜索。但是,它们使用随机写入来实现这些属性。我们工作的目标是在不牺牲读取或扫描性能的情况下改进B树的写入。
有序的日志结构化索引会在RAM中进行更新,对其进行排序,然后将排序后的运行写入磁盘。随着时间的流逝,运行会合并,从而限制了读取和扫描所产生的开销。合并的成本取决于索引数据的大小和用于缓冲区写入的RAM数量。
无序的日志结构化索引会立即将数据写入磁盘,从而无需单独的日志。压缩这些存储的成本是在基础设备上保留的可用空间量的函数,并且与用作缓存的内存量无关。与有序存储相比,无序存储通常具有更高的持续写入吞吐量(数量级差异并不罕见[22、27、28、32])。这些好处是有代价的:无序存储不提供有效的扫描操作。
扫描是各种应用程序所需要的(并由PNUTS和Walnut导出),对于有效的关系查询处理而言,扫描是必不可少的。由于我们以此类用例为目标,因此我们无法利用无序技术。
但是,这种技术是对我们技术的补充,并且有许多实现方式可用(第6节)。现在我们来讨论通过有序方法进行的交易。
2.1 Terminology
A common theme of this work is the tradeoff between asymptotic and constant factor performance improvements.
We use the following concepts to reason about such tradeoffs. Read amplication [7] and write amplication [22] characterize the cost of reads and writes versus optimal schemes.
We measure read amplication in terms of seeks, since at least one random read is required to access an uncached piece of data, and the seek cost generally dwarfs the transfer cost.
In contrast, writes can be performed using sequential I/O, so we express write amplication in terms of bandwidth.
By convention, our computations assume worst-case access patterns and optimal caching policies.
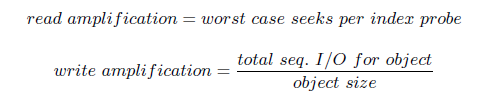
Write amplication includes both the synchronous cost of the write, and the cost of deferred merges or compactions.
Given a desired read amplication, we can compute the read fanout (our term) of an index. The read fanout is the ratio of the data size to the amount of RAM used by the index.
To simplify our calculations, we linearly approximate read fanout by only counting the cost of storing the bottom-most layer of the index pages in RAM. Main memory has grown to the point where read amplications of one (or even zero) are common (Appendix A). Here, we focus on read fanouts with a read amplication of one.
2.1术语
这项工作的一个共同主题是在渐近和恒定因子性能改进之间进行权衡。
我们使用以下概念来进行这种折衷。读取放大[7]和写入放大[22]表征了读写方案相对于最佳方案的成本。
由于需要至少一个随机读取才能访问未缓存的数据,因此我们根据寻道来标识读放大,并且寻道成本通常会使传输成本忽略不计。
相反,可以使用顺序I / O执行写操作,因此我们以带宽表示写放大。
按照惯例,我们的计算采用最坏情况下的访问模式和最佳的缓存策略。
写放大包括同步写开销和延迟合并或压缩的开销。
给定所需的读放大,我们可以计算索引的读扇出(我们的术语)。读取扇出是数据大小与索引使用的RAM量的比率。
为了简化计算,我们仅通过计算将索引页的最底层存储在RAM中的成本,来线性近似读取扇出。主存储器已经发展到一种普遍的读取放大倍数(甚至零)(附录A)。在这里,我们将重点放在读取放大倍数为1的读取扇出上。
2.2 B-Trees
Assuming that keys fit in memory, B-Trees provide optimal random reads; they perform a single disk seek each time an uncached piece of data is requested. In order to perform an update, B-Trees read the old version of the page, modify it, and asynchronously write the modification to disk.
This works well if data fits in memory, but performs two disk seeks when the data to be modified resides on disk. Update-inplace hashtables behave similarly, except that they give up the ability to perform scans in order to make more efficient use of RAM.
Update in place techniques’ effective write amplifications depend on the underlying disk. Modern hard disks transfer 100-200MB/sec, and have mean access times over 5ms. One thousand byte key value pairs are fairly common; it takes the disk 10us to write such a tuple sequentially.
Performing two seeks takes a total of 10ms, giving us a write amplification of approximately 1000.
Appendix A applies these calculations and a variant of the five minute rule [15] to estimate the memory required for a read amplification of one with various disk technologies.
2.2 B树
假设密钥适合内存,B树将提供最佳的随机读取。每当请求未缓存的数据时,它们都会执行一次磁盘搜索。为了执行更新,B树会读取页面的旧版本,对其进行修改,然后将修改异步写入磁盘。
如果数据适合内存,此方法效果很好,但是当要修改的数据驻留在磁盘上时,执行两次磁盘搜索。就地更新哈希表的行为类似,不同之处在于它们放弃了执行扫描以更有效地使用RAM的能力。
就地更新技术的有效写放大取决于底层磁盘。现代硬盘的传输速度为100-200MB /秒,平均访问时间超过5ms。一千个字节的键值对非常普遍;磁盘10us依次写入这样的元组。
执行两次寻道总共需要10毫秒,因此我们的写入放大倍数约为1000。一种新的写入放大计算方式。
附录A应用了这些计算和五分钟规则的一种变体[15]来估计使用各种磁盘技术对一个磁盘进行读放大所需要的内存。
2.3 LSM-Trees
This section begins by describing the base LSM-Tree algorithm, which has unacceptably high read amplification, cannot take advantage of write locality, and can stall application writes for arbitrary periods of time. However, LSMTree write amplification is much lower than that of a B-Tree, and the disadvantages are avoidable.
Write skew can be addressed with tree partitioning, which is compatible with the other optimizations. However, we find that long write pauses are not adequately addressed by existing proposals or by state-of-the-art implementations
2.3 LSM树
本节从描述基本的LSM-Tree算法开始,该算法具有无法接受的高读取放大率,无法利用写入局部性,并且可以在任意时间段内停止应用程序写入。 但是,LSMTree的写放大比B-Tree低得多,可以避免这些缺点。
可以通过与其他优化兼容的树分区解决写偏斜。 但是,我们发现现有的提案或最新的实现方式并不能充分解决长写入暂停问题
2.3.1 Base algorithm

LSM-Trees consist of a number of append-only B-Trees and a smaller update-in-place tree that fits in memory.
We call the in-memory tree C0. Repeated scans and merges of these trees are used to spill memory to disk, and to bound the number of trees consulted by each read.
The trees are stored in key order on disk and the inmemory tree supports efficient ordered scans. Therefore, each merge can be performed in a single pass. In the version of the algorithm we implement (Figure 1), the number trees is constant. The on-disk trees are ordered by freshness;
the newest data is in C0. Newly merged trees replace the higher-numbered of the two input trees. Tree merges are always performed between Ci and Ci+1.
The merge threads attempt to ensure that the trees increase in size exponentially, as this minimizes the amortized cost of garbage collection. This can be proven in many different ways, and stems from a number of observations [25]:
2.3.1基本算法
LSM树由多个仅附加的B树和一个较小的就地更新树(适合内存)组成。
我们将内存树称为C0。 这些树的重复扫描和合并用于将内存溢出到磁盘,并限制每次读取所查询的树数。
这些树以密钥顺序存储在磁盘上,内存树支持高效的有序扫描。 因此,每个合并都可以在一次通过中执行。 在我们实现的算法版本中(图1),树的数量是恒定的。 磁盘树按新鲜度排序;
最新数据在C0中。 新合并的树替换了两个输入树中编号较高的树。 树合并始终在Ci和Ci + 1之间执行。
合并线程试图确保树的大小成倍增加,因为这使垃圾回收的摊余成本最小化。 这可以用许多不同的方式来证明,并且源于许多观察[25]:
2.3.2 Leveraging write skew
Although we describe a special case solution in Section 4.2, partitioning is the best way to allow LSM-Trees to leverage write skew [16]. Breaking the LSM-Tree into smaller trees and merging the trees according to their update rates concentrates merge activity on frequently updated key ranges.
It also addresses one source of write pauses. If the distribution of the keys of incoming writes varies significantly from the existing distribution, then large ranges of the larger tree component may be disjoint from the smaller tree. Without partitioning, merge threads needlessly copy the disjoint data, wasting I/O bandwidth and stalling merges of smaller trees.
During these stalls, the application cannot make forward progress.
Partitioning can intersperse merges that will quickly consume data from the small tree with merges that will slowly consume the data, “spreading out” the pause over time. Sections 4.1 and 5 argue and show experimentally that, although necessary in some scenarios, such techniques are inadequate protection against long merge pauses. This conclusion is in line with the reported behavior of systems with partition-based merge schedulers, [1, 12, 19] and with previous work, [16] which finds that partitioned and baseline LSM-Tree merges have similar latency properties.
2.3.2 改善写偏斜
尽管我们在4.2节中描述了一种特殊情况的解决方案,但分区是允许LSM-Tree改善写入偏斜的最佳方法[16]。将LSM-Tree分解为较小的树,然后根据树的更新速率合并树,将合并活动集中在频繁更新的键范围上。
它还解决了写入暂停的一种来源。如果传入写入的键的分布与现有分布有很大不同,则较大树组件的较大范围可能与较小树不相交。如果不进行分区,合并线程将不必要地复制不相交的数据,从而浪费I / O带宽并停止较小树的合并。
在这些停顿期间,应用程序无法前进。
分区可以散布合并,合并将迅速消耗小树中的数据,合并将缓慢消耗数据,并随着时间的推移“散布”暂停。第4.1节和第5节争论并通过实验表明,尽管在某些情况下是必需的,但这种技术不足以防止较长的合并暂停。该结论与已报道的基于分区的合并调度程序的系统行为[1,12,19]和先前的工作[16]一致,后者发现分区的LSM-Tree合并和基线LSM-Tree合并具有相似的延迟属性。
3. ALGORITHMIC IMPROVEMENTS
We now present bLSM, our new LSM-Tree variant, which addresses the LSM-Tree limitations we describe above.
The first limitation of LSM-Trees, excessive read amplification, is only partially addressed by Bloom filters, and is closely related to two other issues: exhaustive lookups which needlessly retrieve multiple versions of a record, and seeks during insert.
The second issue, write pauses, requires scheduling infrastructure that is missing from current implementations
3.算法改进
现在,我们介绍bLSM,这是我们的新LSM-Tree变体,它解决了我们上面描述的LSM-Tree限制。
LSM树的第一个限制,即过度的读取放大,只能由Bloom过滤器部分解决,并且与其他两个问题密切相关:MVCC过程中的昂贵的查找方式,在插入期间进行查找。
第二个问题,写暂停,要求安排当前实现中缺少的基础结构
3.1 Reducing read amplification
Fractal cascading and Bloom filters both reduce read amplification. Fractal cascading reduces asymptotic costs; Bloom filters instead improve performance by a constant factor.
The Bloom filter approach protects the C1...CN tree components with Bloom filters. The amount of memory it requires is a function of the number of items to be inserted, not the items’ sizes.
Allocating 10 bits per item leads to a 1% false positive rate, and is a reasonable tradeoff in practice.
Such Bloom filters reduce the read amplification of LSMTree point lookups from N to 1+ N/100 .
Unfortunately, Bloom Filters do not improve scan performance. Appendix A runs through a “typical” application scenario; Bloom filters would increase memory utilization by about 5% in that setting.
Unlike Bloom filters, fractional cascading [18] reduces the asymptotic complexity of write-optimized LSM-Trees. Instead of varying R, these trees hold R constant and add additional levels as needed, leading to a logarithmic number of levels and logarithmic write amplification. Lookups and scans access a logarithmic (instead of constant) number of tree components.
Such techniques are used in systems that must maintain large number of materialized views, such as the TokuDB MySQL storage engine [18].
Fractional cascading includes pointers in tree component leaf pages that point into the leaves of the next largest tree.
Since R is constant, the cost of traversing one of these pointers is also constant. This eliminates the logarithmic factor associated with performing multiple B-Tree traversals.
The problem with this scheme is that the cascade steps of the search examine pages that likely reside on disk. In effect, it eliminates a logarithmic in-memory overhead by increasing read amplification by a logarithmic factor.
Figure 2 provides an overview of the lookup process, and plots read amplification vs. fanout for fractional cascading and for three-level LSM-Trees with Bloom filters. No setting of R allows fractional cascading to provide reads competitive with Bloom filters—reducing read amplification to 1 requires an R large enough to ensure that there is a single on-disk tree component. Doing so leads to O(n) write amplifications. Given this, we opt for Bloom filters.
3.1减少读放大
分形级联和布隆过滤器均会降低读取放大率。分形级联降低了渐近成本;相反,布隆过滤器通过一个常数将性能提高。
布隆过滤器方法使用布隆过滤器保护C1 ... CN树组件。所需的存储量取决于要插入的项目数,而不是项目的大小。
每个项目分配10位会导致1%的误报率,并且在实践中是一个合理的权衡。
这种Bloom过滤器将LSMTree点查找的读取放大率从N降低到1+ N / 100。
不幸的是,布隆过滤器不能提高扫描性能。附录A贯穿“典型”应用场景;在该设置下,Bloom过滤器会将内存利用率提高约5%。
与布隆过滤器不同,分数级联[18]降低了写优化的LSM树的渐近复杂度。这些树没有改变R,而是使R保持不变,并根据需要添加其他级别,从而导致级别的对数和对数写入放大。查找和扫描访问对数(而不是常数)的树组件。
此类技术用于必须维护大量实例化视图的系统中,例如TokuDB MySQL存储引擎[18]。
分数级联包括在树组件叶页面中的指针,这些指针指向第二棵大树的叶子。
由于R为常数,因此遍历这些指针之一的开销也为常数。这消除了与执行多个B-Tree遍历相关的对数因子。
该方案的问题在于,搜索的级联步骤将检查可能驻留在磁盘上的页面。实际上,它通过增加对数因子的读取放大来消除对数内存开销。
图2概述了查找过程,并绘制了级联级联和具有Bloom过滤器的三级LSM树的读取放大与扇出曲线。没有设置R允许小数级联提供与Bloom过滤器竞争的读取-将读取放大率减小到1需要一个足够大的R以确保只有一个磁盘树组件。这样做会导致O(n)写放大。鉴于此,我们选择Bloom过滤器。
3.1.1 Limiting read amplification for frequently updated data
On their own, Bloom filters cannot ensure that read amplifications are close to 1, since copies of a record (or its deltas) may exist in multiple trees. To get maximum read performance, applications should avoid writing deltas, and instead write base records for each update.
Our reads begin with the lowest numbered tree component, continue with larger components in order and stop at the first base record. Our reads are able to terminate early because they distinguish between base records and deltas, and because updates to the same tuple are placed in tree levels consistent with their ordering.
This guarantees that reads encounter the most recent version first, and has no negative impact on write throughput. Other systems nondeterministically assign reads to on-disk components, and use timestamps to infer write ordering. This breaks early termination, and can lead to update anomalies [1].
3.1.1对频繁更新的数据限制读放大
Bloom过滤器本身不能确保读取的放大率接近1,因为一条记录(或其增量)的副本可能存在于多个树中。 为了获得最大的读取性能,应用程序应避免写入增量,而应为每次更新写入基本记录。
我们的读取从编号最低的树组件开始,依次从大的组件开始,直到第一个基本记录。 我们的读取能够提前终止,因为它们区分基本记录和增量,并且因为对相同元组的更新位于与它们的顺序一致的树级别中。
这样可以确保读取操作首先遇到最新版本,并且对写入吞吐量没有负面影响。 其他系统不确定地将读取分配给磁盘上的组件,并使用时间戳推断写顺序。 这破坏了提前终止,并可能导致更新异常[1]。
3.1.2 Zero-seek “insert if not exists”
One might think that maintaining a Bloom filter on the largest tree component is a waste; this Bloom filter is by far the largest in the system, and (since C2 is the last tree to be searched) it only accelerates lookups of non-existent data.
It turns out that such lookups are extremely common; they are performed by operations such as “insert if not exists.”
In Section 5.2, we present performance results for bulk loads of bLSM, InnoDB and LevelDB. Of the three, only bLSM could efficiently load and check our modest 50GB unordered data set for duplicates. “Insert if not exists” is a widely used primitive; lack of efficient support for it renders high-throughput writes useless in many environments.
3.1.2零寻找“如果不存在则插入”
有人可能会认为在最大的树组件上维护Bloom过滤器是一种浪费;该Bloom过滤器是迄今为止系统中最大的过滤器,并且(由于C2是要搜索的最后一棵树),它只会加速对不存在数据的查找。
事实证明,这种查询极为普遍。它们通过诸如“如果不存在则插入”之类的操作来执行。
在5.2节中,我们介绍了bLSM,InnoDB和LevelDB的大容量负载的性能结果。在这三个中,只有bLSM可以有效地加载和检查我们适度的50GB无序数据集是否重复。 “如果不存在,则插入”是一种广泛使用的原语;缺乏有效的支持使高吞吐量写入在许多环境中无用。
3.2 Dealing with write pauses
Regardless of optimizations that improve read amplification and leverage write skew, index implementations that impose long, sporadic write outages on end users are not particularly practical. Despite the lack of good solutions LSM-Trees are regularly put into production.
We describe workarounds that are used in practice here.
At the index level, the most obvious solution (other than unplanned downtime) is to introduce extra C1 components whenever C0 is full and the C1 merge has not yet completed [13]. Bloom filters reduce the impact of extra trees, but this approach still severely impacts scan performance.
Systems such as HBase allow administrators to temporarily disable compaction, effectively implementing this policy [1].
As we mentioned above, applications that do not require performant scans would be better off with an unordered log structured index.
Passing the problem off to the end user increases operations costs, and can lead to unbounded space amplification.
However, merges can be run during off-peak periods, increasing throughput during peak hours. Similarly, applications that index data according to insertion time end up writing data in “almost sorted” order, and are easily handled by existing merge strategies, providing a stop-gap solution until more general purposes systems become available.
Another solution takes partitioning to its logical extreme, creating partitions so small that even worst case merges introduce short pauses. This is the technique taken by Partitioned Exponential Files [16] and LevelDB [12]. Our experimental results show that this, on its own, is inadequate. In particular, with uniform inserts and a “fair” partition scheduler, each partition would simultaneously evolve into the same bad state described in Figure 4.
At best, this would lead to a throughput collapse (instead of a complete cessation of application writes).
Obviously, we find each of these approaches to be unacceptable. Section 4.1 presents our approach to merge scheduling. After presenting a simple merge scheduler, we describe an optimization and extensions designed to allow our techniques to coexist with partitioning
3.2处理写暂停
不管改善读取放大并利用写入偏斜的优化如何,对最终用户造成长时间零星写入中断的索引实现都不是特别实用。尽管缺少好的解决方案,但LSM-Trees仍会定期投入生产。
我们在此介绍在实践中使用的变通方法。
在索引级别,最明显的解决方案(计划外停机时间除外)是在C0已满且C1合并尚未完成时引入额外的C1组件[13]。布隆过滤器可以减少多余树木的影响,但是这种方法仍然会严重影响扫描性能。
诸如HBase之类的系统允许管理员暂时禁用压缩,从而有效地实施此策略[1]。
正如我们上面提到的,不需要执行扫描的应用程序最好使用无序的日志结构化索引。
将问题传递给最终用户会增加运营成本,并可能导致无限的空间放大。
但是,可以在非高峰时段运行合并,从而增加了高峰时段的吞吐量。同样,根据插入时间对数据进行索引的应用程序最终以“几乎排序”的顺序写入数据,并易于通过现有的合并策略进行处理,从而提供了一个权宜之计,直到可以使用更多通用系统为止。
另一种解决方案将分区扩展到其逻辑极限,创建的分区是如此之小,以至于即使是最坏的情况下的合并也会导致短暂的暂停。这是分区指数文件[16]和LevelDB [12]所采用的技术。我们的实验结果表明,这本身是不够的。特别是,使用统一的插入和“公平”的分区调度程序,每个分区将同时演变为图4中描述的相同坏状态。
充其量,这将导致吞吐量崩溃(而不是完全停止应用程序写操作)。
显然,我们发现每种方法都是不可接受的。第4.1节介绍了我们的合并调度方法。在介绍了一个简单的合并调度程序之后,我们描述了一种优化和扩展,旨在使我们的技术能够与分区共存
3.3 Two-seek scans
Scan operations do not benefit from Bloom filters and must examine each tree component. This, and the importance of delta-based updates led us to bound the number of on-disk tree components. bLSM currently has three components and performs three seeks. Indeed, Section 5.6 presents the sole experiment in which InnoDB outperforms bLSM: a scan-heavy workload.
We can further improve short-scan performance in conjunction with partitioning. One of the three on-disk components only exists to support the ongoing merge. In a system that made use of partitioning, only a small fraction of the tree would be subject to merging at any given time. The remainder of the tree would require two seeks per scan.
3.3两遍扫描
扫描操作无法从布隆过滤器中受益,必须检查每个树组件。 这以及基于增量的更新的重要性使我们限制了磁盘上树组件的数量。 bLSM当前包含三个组件,并执行三个搜索。 实际上,第5.6节介绍了InnoDB优于bLSM的唯一实验:扫描繁重的工作负载。
我们可以结合分区进一步提高短扫描性能。 磁盘上三个组件之一仅用于支持正在进行的合并。 在使用分区的系统中,在任何给定时间仅会合并一小部分树。 树的其余部分每次扫描将需要两次搜索。
4. BLSM
As the previous sections explained, scans and reads are crucial to real-world application performance. As we decided which LSM-Tree variants and optimizations to use in our design, our first priority was to outperform B-Trees in practice.
Our second concern was to do so while providing asymptotically optimal LSM-Tree write throughput.
The previous section outlined the changes we made to the base LSM-Tree algorithm in order to meet these requirements.
Figure 1 presents the architecture of our system. We use a three-level LSM-Tree and protect the two on-disk levels with Bloom filters. We have not yet implemented partitioning, and instead focused on providing predictable, low latency writes. We avoid long write pauses by introducing a new class of merge scheduler that we call a level scheduler (Figure 4).
Level schedulers are designed to complement
existing partition schedulers (Figure 3).
4. BLSM
如前所述,扫描和读取对于实际应用程序性能至关重要。 当我们决定在设计中使用哪种LSM-Tree变体和优化时,我们的首要任务是在实践中胜过B-Tree。
我们的第二个考虑是这样做,同时提供渐近最佳的LSM-Tree写吞吐量。
上一节概述了为满足这些要求而对基本LSM-Tree算法所做的更改。
图1展示了我们系统的体系结构。 我们使用三级LSM-Tree,并使用Bloom过滤器保护两个磁盘级。 我们尚未实现分区,而是专注于提供可预测的低延迟写入。 通过引入新的合并调度程序类(我们称为级别调度程序),我们避免了长时间的写暂停(图4)。
级别调度程序旨在补充
现有的分区调度程序(图3)。
4.1 Gear scheduler
In this section we describe a gear scheduler that ensures merge processes complete at the same time (Figure 5).
This scheduler is a subcomponent of the spring and gear scheduler (Section 4.3). We begin with the gear scheduler because it is conceptually simpler, and to make it clear how to generalize spring and gear to multiple levels of tree components.
As Section 3.2 explained, we are unwilling to let extra tree components accumulate, as doing so compromises scan performance. Instead, once a tree component is full, we must block upstream writes while downstream merges complete.
Downstream merges can take indefinitely long, and we are unwilling to give up write availability, so our only option is to synchronize merge completions with the processes that fill each tree component. Each process computes two progress indicators: inprogress and outprogress.
In Figure 5, numbers represent the outprogress of C0 and the inprogress of C1. Letters represent the outprogress of C1 and the inprogress of C2.
We use a clock analogy to reason about the merge processes in our system. Clock gears ensure each hand moves at a consistent rate (so the minute and hour hand reach 12 at the same time, for example). Our merge processes ensure that trees fill at the same time as more space becomes available downstream. As in a clock, multiple short upstream merges (sweeps of the minute hand) may occur per downstream merge (sweep of the hour hand).
Unlike with a clock, the only important synchronization point is the hand-off from smaller component to larger (the meeting of the hands at 12).
4.1齿轮调度器
在本节中,我们描述了一个齿轮调度程序,它确保合并过程同时完成(图5)。
该调度程序是弹簧和齿轮调度程序的子组件(第4.3节)。我们从齿轮调度器开始,因为它在概念上更简单,并且要弄清楚如何将弹簧和齿轮归纳为多个层次的树组件。
如3.2节所述,我们不愿意让多余的树组件累积,因为这样做会损害扫描性能。相反,一旦树组件已满,我们就必须在下游合并完成时阻止上游写入。
下游合并可能需要无限长的时间,并且我们不愿意放弃写可用性,因此我们唯一的选择是将合并完成与填充每个树组件的进程同步。每个过程都计算两个进度指示器:进度和进度。
在图5中,数字表示C0的进度和C1的进度。字母表示C1的进度和C2的进度。
我们使用时钟类比来推断系统中的合并过程。时钟齿轮确保每只指针均以一致的速度运动(例如,分针和时针同时达到12点)。我们的合并过程可确保在下游有更多可用空间的同时填充树木。就像在时钟中一样,每个下游合并(时针的扫描)可能会发生多个短的上游合并(分针的扫描)。
与时钟不同,唯一重要的同步点是从较小的组件到较大的组件的交接(指针在12点相遇)。















 4398
4398











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









