







基于Lease的一致性最初应用于分布式文件Cache,后来随着互联网的快速发展,发现非常适合于Web Proxy,因此针对Proxy Cache领域中的Lease便多了起来。
1. Lease的由来
关于Lease最经典的解释来源于Lease的原始论文<<Leases: An Efficient Fault-Tolerant Mechanism for Distributed File Cache Consistency>>:
a lease is a contract that gives its holder specific rights over property for a limited period of time
即Lease是一种带期限的契约,在此期限内拥有Lease的节点有权利操作一些预设好的对象,一般把拥有Lease节点称为Master。从更深 层次上来看,Lease就是一把带有超时机制的分布式锁,如果没有Lease,分布式环境中的锁可能会因为锁拥有者的失败而导致死锁,有了lease死锁 会被控制在超时时间之内。
在租约期限内,客户端可以保证其缓存中的数据是最新的。同时,租约可以容忍各种非拜占庭式失效(机器崩溃、网络分割等)。如果客户端崩溃或者网络中断,服务器只需要等待其租约过期就可以进行修改操作。如果服务器出错丢失了所有客户端的信息,它只需要知道租约的最长期限,就可以在这个期限之后安全的修改数据。与回调方式相比,服务器只需记住还拥有租约的客户端即可。
2. Web Server Proxy
众所周知,一般会采用Proxy的方式加速对Web资源的访问速度,而Proxy也是HTTP协议里面的一个标准组件,其基本原理就是对远程 Server上的资源进行Cache,Client在访问Proxy时如果所需的内容在Proxy Cache中不存在,则访问Server;否则直接把Cache中的内容返回给Client。通过Proxy既提高了用户体验,又降低了Server负 载。当然,一个Server会存在很多个Proxy。
因此,保证Cache中的数据与Server一致成为Proxy Cache能正确工作的前提。之前,一般互联网数据不需要很强的一致性,但随着支付、股票等应用的发展,强一致性成为比不可少的要求,Lease就是解决这类强一致性的折中方案。
在不需要强一致性的环境中,Cache只要每隔一段时间与Server同步一下即可,但在需要强一致性的环境这种做法远不能满足需求。一般的实现强一致性有下面两种方式:
- 客户端驱动:每次Read之前都check,像HTTP协议的If-Modified-Since头
- Server驱动:Server上面的每次变更都通知Cache,这种方式具体又有两种实现:
- Server仅通知Cache数据失效,Cache主动把失效数据拉过来
- Server把变更的数据通知Cache
基于客户端的好处是,同步过程与Server完全无关,两套系统没有耦合,维护性强,但会造成很大的无效流量,Server要承担很大的负载。基于 Server的好处是没有无效流量,每次更新都很准确,但通信量太大,不需要的更新的内容也被更新。Server驱动还有另外一个问题,就是如果某个 Proxy无法响应,Server可能会陷于死锁状态,从而影响其他Cache的正常工作。
3.应用Lease到Proxy
引入Lease后规定:
- Cache第一次访问Server时,Server返回该Request的内容与一个Lease(Cache称为Holder)
- 在Lease期限之内,Server会主动把更新数据推送到Cache(是推送失效通知还是变更数据要看应用的情况)
- 如果Lease超时,Cache需要重新申请Lease
如果Lease时间无穷大,就是Server驱动模式;如果为0,则为客户端驱动模式,因此Lease是二者的一个折中。
很明显,影响Lease效果的一个重要的一个参数是Lease的时间:太长,Server端需要为Request予准备很多的状态(占用很多的空 间);太小,则会造成Cache与Server之间的流量增大,加大Server负载。在专业论文中用很多的公式来描述这个参数的影响,感觉没多大必要, 这里略过不表。
Lease模式可以称为“按需一致”,即用户访问的数据才进行一致,而对那些没有访问的数据不需要一致,这就一定程度上克服了Server驱动模式 下全部推送数据的缺点。试想有多个Proxy的场景,只要某条数据在多个Proxy上访问过,那么他们在所有的Proxy上是一致的,否则可能会不一致。
4. Lease的特点
很显然,Lease更擅长解决Cache与某个数据源之间的数据一致性问题,而不关心多Cache之间数据是否一致,其应用场景有较强的限制,非常 适合与类似Proxy这样的情况。但在真正Proxy Cache实现中中会根据不同的数据,同时存在弱一致性和Lease强一致性,也称为可调节的一致性。
Lease算法看似简单,但为我们在其他处理分布式问题时提供了很好的思路。尤其是原论文作者对Lease的定义,其价值远大于其在Proxy中的应用。
When a datum is fetched from the server (the primary storage site of the datum), the server also returns a lease guaranteeing that the data will not be written by any client during the lease rerm unless the server first obtains the approval of this leaseholder. If the datum is read again within the term of the lease (and the datum is still in the cache), the cache provides immediate access to the datum without communicating with the server.After the lease expires, a read of the datum requires that the cache first extend the lease on the datum, updating the cache if the datum has been modified since the lease expired. When a client writes a datum, the server must defer the request until each leaseholder has granted approval or the term of its lease has expired.
Short lease terms have several advantages. One is that they minimize the delay resulting from client and server failures (and partitioning communication failures). When the server cannot communicate with a client, the server must delay writes to a file for which the failed client holds a lease until that lease expires. When a server is recovering after crashing, it must honor the leases it granted before it crashed. This is most easily done if it remembers the maximum term for which it had granted a lease, and it delays writes to all tiles for that period, effectively increasing the time to fully recover by the maximum term.
当数据从服务器(数据的主要存储网站)获取,服务器也返回租约保证数据不会被租赁rerm期间所写的任何客户端,除非服务器首先获得该承租人的批准。如果数据是在租赁期限内再次读取(和数据仍处于高速缓存),缓存提供了即时访问数据不与租约到期的server.After通信时,数据的读取要求缓存第一延长基准租赁,更新缓存,如果数据被修改,因为租约到期。当客户端写入数据时,服务器必须按照要求,直到每个承租人已批准或租约期限已过期。
短期租约条款有几个优点。之一是它们最小化从客户端和服务器的故障(和分区通信故障)而产生的延迟。当服务器无法与客户沟通时,服务器必须延迟写入了其失败的客户持有的租约,直到租约到期的文件。当服务器崩溃后恢复,就必须遵守授予坠毁前的租约。这是最容易做的,如果它记住了,它已经批准租赁的最长期限,并延迟写入所有瓷砖此期间,有效地提高到了最高刑期完全恢复的时间。
5.Lease演化
很多人沿着Lease这条路继续向下走,又产生了:
- volume lease:把对象作为一个集合
- hierarchical lease:把Lease层次化
这些算法的目标都是在特定场景下寻找平衡lease时间的方法。
因为我们着重研究Lease的一致性,对其在Web环境下的具体应用讨论的并不多,感兴趣的同学可以参考:
- Adaptive Leases: A Strong ConsistencyMechanism for the World Wide Web
- Lease Based Consistency Scheme in the Web Environment.pdf
1. 动态密钥管理
中 心密钥服务器维护着全局的密钥生成和发放,所有需要使用密钥的外围系统向密钥服务器申请密钥用于本系统的加解密工作。出于性能和可用性考虑,不能每个请求 都向中心服务器去申请,因此密钥通常被缓存在本地系统中。那么当需要修改中心系统的密钥时(出于安全性考虑的定期修改),如何保证所有使用该密钥的本地系 统都立刻丢弃过期的密钥,而立刻向中心密钥服务器重新申请最新的密钥,并保持所有系统中密钥的一致性?(不一致可能导致系统不可用)。
这 种场景非常适合使用 lease 机制来解决,中心服务器发放密钥的时候,同时发放一个 lease 承诺在一定时间内不修改该密钥。本地系统获取密钥时,同时根据 lease 的约定只在其有效期内使用密钥,lease 一旦过期立刻重新申请密钥。当变更密钥时,在所有已颁发的 lease 全部过期前修改不能生效,并且在变更密钥生效期间不能颁发新的 lease,避免形成活锁(永远等不到所有 lease 失效)。
这个机制大体如上述,但还有一些细节点需要考虑,lease 机制依赖于分布式环境下的服务器时钟同步,如果出现时钟不同步的情况,在这个应用场景下会带来什么影响?如何规避或解决?
中心服务器时钟比客户端系统慢:这种情况下, 客户端将 lease 过期时中心服务器还未过期,客户端只需重新发起新的 lease 申请即可,如果此时遇到中心服务器正在进行密钥更新锁定不能颁发 lease,则可只返回当前的密钥数据,而不颁发 lease。客户端将在这个时间窗口中退化为每请求一次性的使用该密钥数据。
2. 分布式文件系统
以GFS为例,每个文件块都有多个副本分布在多个chunckserver上,在 并行追加时必须有一个全局统一的追加顺序。
当然这个顺序全部由中心 master 来决定,那 master 将承担过大的负荷。
GFS中的Lease:
GFS中使用lease确定Chunk的primary部分。lease由master节点颁发给primary副本,持有lease的副本成为primary副本。primary副本控制该chunk的数据更新流量,确定并发更新操作在chunk上的执行顺序。GFS中的lease信息由master在响应各个节点的heart beat时附带传递。但GFS得master失去某个节点的heart beat时,只需待该节点上的primary chunk的lease超时,便可以为这些chunk重新选择primary副本并颁发lease。
3. 状态检测
在通常的集群系统中,我们采用心跳来检测节点状态。但普通的心跳机制是无协议和承诺约定的,所以它的检测结果可能不可靠。很多监控系统采用心跳检测集群中节点的存活性,这种机制存在误报警的可能。
基于“心跳heartbeat”的方法并不能很好的解决这个问题。A,B,C周期性的向Q发送心跳信息,若Q超过一定时间收不到某个节点的心跳信息,则认为节点异常。但显然,通信异常也有可能是网络中断导致的,更大的可能是节点间的网络拥塞造成的“瞬断”,而“瞬断”是可以很快恢复的。
假设A本身工作正常,但Q与A之间的网络暂时中断,A与B,C之间的网络正常。此时Q认为A异常,重新选择B为primary,并通知A,B,C新的primary为B。由于Q的通知消息到达节点A,B,C的顺序无法确定,假设先到B,则在这一时刻,系统中同时存在两个primary,即A,B。假如此时A,B都接受外部请求并与C同步数据,会产生严重的数据错误。
解决的方法可以是利用lease机制确定节点状态:由中心节点向其他节点发送lease,若某个节点持有有效的lease,则认为该节点正常可以服务。例如,A,B,C依然周期性的发送心跳信息报告自身状态,节点Q收到心跳后发送一个lease,表示确认了A,B,C的状态,并允许节点在lease有效期内正常工作。Q可以给primary节点一个特殊的lease, 表示节点可以作为primary工作。一但节点Q希望切换新的primary,则只需等前一个primary的lease过期,则就可以安全的颁发新的lease给新的primary节点,这样可以避免“双主”问题。
Lease的有效时间的选择:若太短(如1秒),很容易因为网络抖动造成lease丢失。若太长(如1分钟),一旦接收者异常,颁发者需要很长时间才能收回lease承诺。工程中,通常选择10秒级别。
在实际生产开发中,遇到一些多节点共存,需要选主,并且要实现HA自动容错的场景,思考了写方法拿出来和大家分享一下。
- Lease协议,Mysql ACID
- 高可用选主方案设计
- 适用场景
- Java语言实现描述
- 进一步优化
系统中有很多应用场景要类似主从架构,主服务器(Master)对外提供服务,从服务器(Salve)热备份,不提供服务但随时活着,如果Master出现宕机或者网络问题,Slave即可接替Master对外服务,并由Slave提升为Master(新主)。典型的多节点共存,但只能同时存在一个主,并且所有节点的状态能统一维护。
大家一定首先想到了著名的Paxos算法(http://baike.baidu.com/view/8438269.htm)。简单的说,Paxos通过每个节点的投票算法,来决议一个事情,当多余1/2个节点都投票通过时,Paxos产生一个唯一结果的决议,并通知各个节点维护这个信息。例如Paxos的选主,首先产生一个关于某个节点希望当Master的投票,然后各个节点给出反馈,最终Paxos集群维护唯一的Master的结论。Zookeeper就是Paxos的一种实现。这种场景最适合用zookeeper来选主,但zookeeper有个明显的缺点,当存活的节点小于zookeeper集群的1/2时,就不能工作了。比如zk有10各节点,那么必须满足可用的节点大于5才可。
在实际环境中,如果对Master要求不是那么严格的话,可以通过某些改进和取舍来达到目的。比如可能在秒级别允许Master暂时不能访问、选主时间内可能存在一定的冲突但通过再次选主即可。本人设计了一个简易的利用Mysql一致性和简易版Lease来workaround。
Mysql ACID保证了一条数据记录的一致性、完整性,不会出现多进程读写的一致性问题和唯一正确性。Lease协议(协议细节可以Google之)通过向Master发送一个lease(租期)包,Master在这个lease期之内充当主角色,如果lease期到了则再次去申请lease,如果lease期到了,但是网络除了问题,这时Master可以i主动下线,让其他节点去竞选Master。举个例子,三个节点A、B、C经过第一轮选主之后,A成为Master,它获得了10秒的lease,当前时间假设是00:00:00,那么它Master地位可以用到00:00:10,当时间到达00:00:10时,A、B、C会重新进行Master选举,每个节点都有可能成为Master(从工程的角度触发,A继续为Master的概率更大),如果这时候A的网络断了,不能联通B、C的集群了,那么A会自动下线,不会去竞争,这样就不会出现“脑裂”的现象。
---------------------------------------------- 华丽的分割线 ----------------------------------------------
设计方案如下:(server代表集群中的一台机器,也可看作一个进程,server之间是平等的)
- 各个server之间用ntpserver时间同步(保证服务器之间秒级同步即可)
- 各个server持有一个唯一ID号(ip+进程号),通过此id唯一标识一个server实例
- 各个server定义一个lease租期,单位为秒
- Mysql唯一表唯一一条记录维护全局Master的信息,ACID保证一致性
- Master Server每半个lease期向Mysql更新如上的唯一一条记录,并更新心跳,维护Master状态
- Slaver Server每半个lease周期从mysql获取Master Server信息,如果数据库中Master的Lease超过了当前时间(heartbeat_time+ lease > current_time),则申请当Master。
这其中比较棘手的问题是:
1、由于数据库访问和休眠的时间(lease的一半),有时延的存在,要处理Mysql异常、网络异常。
2、可能存在同时抢占Master的server,这个时候就需要一个验证机制保证为抢到Master的server自动退位为Slaver
下面给出图实例 :(10.0.0.1为Master)
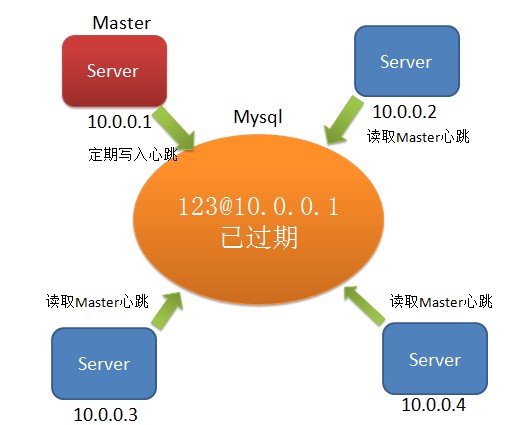

10.0.0.1 crash了。mysql中维护的10.0.0.1的主信息已过期,其他节点去抢占
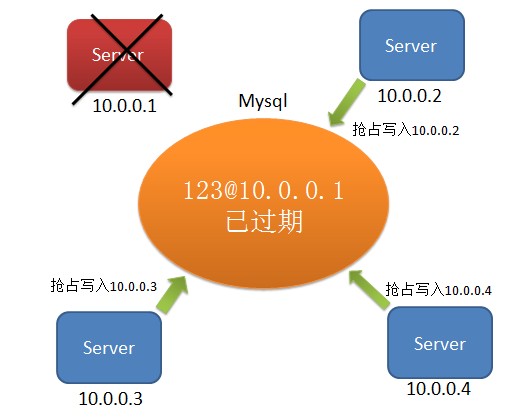
各个节点再次读取数据库,查看是否是自己抢占成功了:
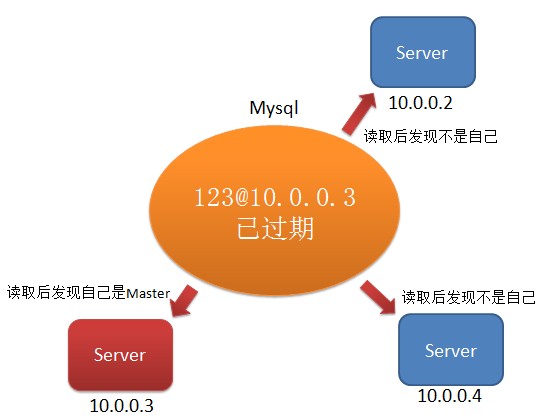
之后,10.0.0.3作为Master对外服务。此时如果10.0.0.1重启,可作为Slaver。如果10.0.0.1因为网络分化或者网络异常而不能维护心跳,则在超过自身lease时自动停止服务,不会出现“双Master”的现象。
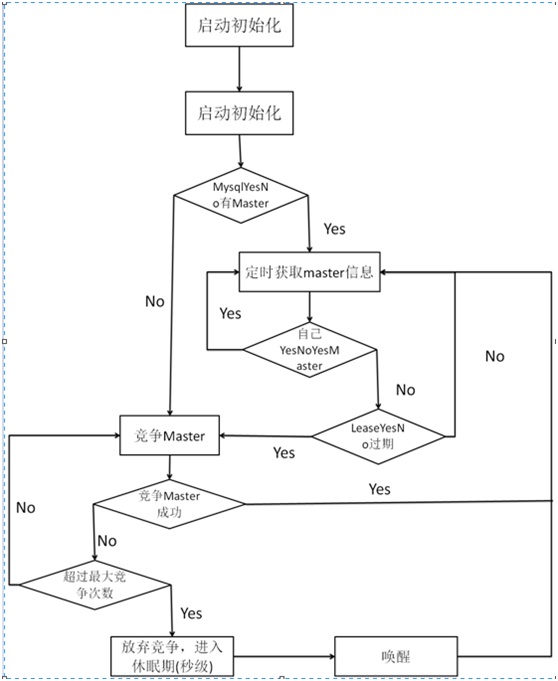
每个Server遵循如下流程:
数据库设计:
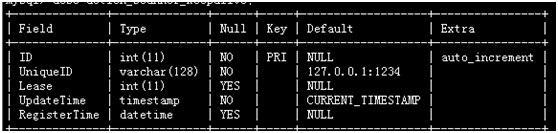
某一时刻,数据库中Master的信息:

当前时间: 45分15秒
当前Master Lease :6秒
当前Master Lease可用到: 45分21秒
---------------------------------------------- 华丽的分割线 ----------------------------------------------
3、适用的场景
一、生命周期内可使用Mysql、并且各个server之间时间同步。
二、需要集群中选出唯一主对外提供服务,其他节点作为slaver做standby,主lease过期时竞争为Master
三、对比zookeeper,可满足如果集群挂掉一半节点,也可正常工作的情况,比如只有一主一备。
四、允许选主操作在秒级容错的系统,选主的时候可能有lease/2秒的时间窗口,此时服务可能不可用。
五、允许lease/2秒内出现极限双Master情况,但是概率很小。















 8796
8796

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









