







文章来源:http://itindex.net/detail/51477-storm-%E7%AC%94%E8%AE%B0-kafka
storm与kafka的结合,即前端的采集程序将实时数据源源不断采集到队列中,而storm作为消费者拉取计算,是典型的应用场景。因此,storm的发布包中也包含了一个集成jar,支持从kafka读出数据,供storm应用使用。这里结合自己的应用做个简单总结。
由于storm已经提供了storm-kafka,因此可以直接使用,使用kafka的低级api读取数据。如果有需要的话,自己实现也并不困难。使用方法如下:
// 设置kafka的zookeeper集群
BrokerHosts hosts = new ZkHosts("10.1.80.249:2181,10.1.80.250:2181,10.1.80.251:2181/kafka");
// 初始化配置信息
SpoutConfig conf = new SpoutConfig(hosts, "topic", "/zkroot","topo");
// 在topology中设置spout
builder.setSpout("kafka-spout", new KafkaSpout(conf));
这里需要注意的是,spout会根据config的后面两个参数在zookeeper上为每个kafka分区创建保存读取偏移的节点,如:/zkroot/topo/partition_0。默认情况下,spout下会发射域名为bytes的binary数据,如果有需要,可以通过设置schema进行修改。
如上面所示,使用起来还是很简单的,下面简单的分析一下实现细节。
(1) 初始化:
/**
KafkaSpout.open
**/
// 初始化用于读写zookeeper的客户端对象_state
Map stateConf = new HashMap(conf);
stateConf.put(Config.TRANSACTIONAL_ZOOKEEPER_SERVERS, zkServers);
stateConf.put(Config.TRANSACTIONAL_ZOOKEEPER_PORT, zkPort);
stateConf.put(Config.TRANSACTIONAL_ZOOKEEPER_ROOT, _spoutConfig.zkRoot);
_state = new ZkState(stateConf);
// 初始化用于读取kafka数据coordinator,真正数据读取使用的是内部的PartitionManager
_coordinator = new ZkCoordinator(_connections, conf, _spoutConfig, _state, context.getThisTaskIndex(), totalTasks, _uuid);
(2) 读取数据:
/**
KafkaSpout.nextTuple
**/
// 通过各个分区对应的PartitionManager读取数据
List<PartitionManager> managers = _coordinator.getMyManagedPartitions();
for (int i = 0; i < managers.size(); i++) {
// in case the number of managers decreased
_currPartitionIndex = _currPartitionIndex % managers.size();
// 调用manager的next方法读取数据并emit
EmitState state = managers.get(_currPartitionIndex).next(_collector);
}
// 提交读取到的位置到zookeeper
long now = System.currentTimeMillis();
if((now - _lastUpdateMs) > _spoutConfig.stateUpdateIntervalMs) {
commit();
}
(3) ack和fail:
/**
KafkaSpout.ack
**/
KafkaMessageId id = (KafkaMessageId) msgId;
PartitionManager m = _coordinator.getManager(id.partition);
if (m != null) {
//调用PartitionManager的ack
m.ack(id.offset);
}
/**
KafkaSpout.fail
**/
KafkaMessageId id = (KafkaMessageId) msgId;
PartitionManager m = _coordinator.getManager(id.partition);
if (m != null) {
//调用PartitionManager的fail
m.fail(id.offset);
}
可以看出,主要的逻辑都在PartitionManager这个类中。下面对它做个简单的分析:
(1)
构造:
//从zookeeper中读取上一次的偏移
Map<Object, Object> json = _state.readJSON(path);
//根据当前时间获取一个偏移
Long currentOffset = KafkaUtils.getOffset(_consumer, spoutConfig.topic, id.partition, spoutConfig);
//maxOffsetBehind为两个偏移的最大范围,如果超过这个范围,则用最新偏移覆盖读取偏移,两个偏移间的数据会被丢弃。如果不希望这样,应该将它设置成一个较大的值或者MAX_VALUE
if (currentOffset - _committedTo > spoutConfig.maxOffsetBehind || _committedTo <= 0) {
_committedTo = currentOffset;
}
//初始化当前偏移
_emittedToOffset = _committedTo;
(2)
next和fill:
/**
PartitionManager.next
**/
//调用fill填充待发送队列
if (_waitingToEmit.isEmpty()) {
fill();
}
//发送数据
while (true) {
MessageAndRealOffset toEmit = _waitingToEmit.pollFirst();
Iterable<List<Object>> tups = KafkaUtils.generateTuples(_spoutConfig, toEmit.msg);
if (tups != null) {
for (List<Object> tup : tups) {
collector.emit(tup, new KafkaMessageId(_partition, toEmit.offset));
}
break;
} else {
ack(toEmit.offset);
}
}
/**
PartitionManager.fill
**/
//初始化当前偏移,读取消息
if (had_failed) {
//先处理失败的偏移
offset = failed.first();
} else {
offset = _emittedToOffset;
}
ByteBufferMessageSet msgs = KafkaUtils.fetchMessages(_spoutConfig, _consumer, _partition, offset);
for (MessageAndOffset msg : msgs) {
final Long cur_offset = msg.offset();
if (cur_offset < offset) {
// Skip any old offsets.
continue;
}
if (!had_failed || failed.contains(cur_offset)) {
numMessages += 1;
//将偏移添加到pending中
_pending.add(cur_offset);
//将消息添加到待发送中
_waitingToEmit.add(new MessageAndRealOffset(msg.message(), cur_offset));
_emittedToOffset = Math.max(msg.nextOffset(), _emittedToOffset);
if (had_failed) {
failed.remove(cur_offset);
}
}
}
(3)
ack和fail
/**
PartitionManager.ack
**/
//从_pending中移除该偏移,如果该偏移与当前偏移的差大于maxOffsetBehind,则清空pending
if (!_pending.isEmpty() && _pending.first() < offset - _spoutConfig.maxOffsetBehind) {
// Too many things pending!
_pending.headSet(offset).clear();
} else {
_pending.remove(offset);
}
numberAcked++;
/**
PartitionManager.fail
**/
//将偏移添加到失败队列中
failed.add(offset);
numberFailed++;
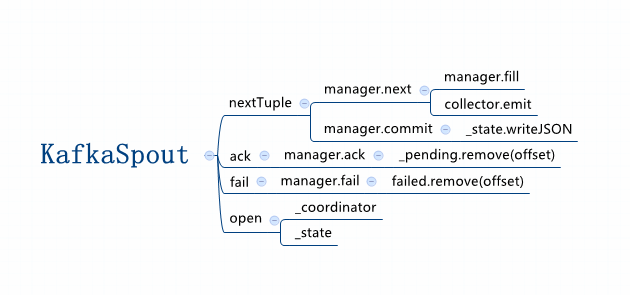
最后,加上一张图做个总结:
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









