







NMT
NMT是Native Memory Tracking的缩写,一个JDK自带的小工具,用来跟踪JVM本地内存分配情况(本地内存指的是non-heap,例如JVM在运行时需要分配一些辅助数据结构用于自身的运行)。
NMT功能默认关闭,可以在Java程序启动参数中加入以下参数来开启:
-XX:NativeMemoryTracking=[summary | detail]
其中,“summary”和“deatil”的差别主要在输出信息的详细程度。
开启NMT功能后,就可以使用JDK提供的jcmd命令来读取NMT采集的数据了,具体命令如下:
jcmd <pid> VM.native_memory [summary | detail | baseline | summary.diff | detail.diff | shutdown]
NMT参数的含义可以通过“jcmd <pid> help VM.native_memory”命令查询。通过NMT工具,我们可以快速区分内存泄露是否源自JVM分配。
pmap
对于非JVM分配的内存,经常需要用到pmap这个工具了,这是一个linux系统自带工具,能够从系统层面输出目标进程内存使用的详细情况,用法非常简单:
pmap [参数] <pid>
常用的选项是“-x”或“-X”,都是用来控制输出信息的详细程度。

这个也可以通过 cat /proc/[pid]/smaps获取
上图是pmap部分输出信息,每列含义为
| Address | 每段内存空间起始地址 |
|---|---|
| Kbytes | 每段内存空间大小(单位KB) |
| RSS | 每段内存空间实际使用内存大小(单位KB) |
| Dirty | 每段内存空间脏页大小(单位KB) |
| Mode | 每段内存空间权限属性 |
| Mapping | 可以映射到文件,也可以是“anon”表示匿名内存段,还有一些特殊名字如“stack” |
现象:
某业务集群中,多个节点出现业务进程内存消耗缓慢增长现象,以其中一个节点为例:

cat /proc/[pid]/status |grep VmPeak -A 14
如图所示,这个业务进程当前占用了4.7G的虚拟内存空间,以及2.2G的物理内存。已知正常状态下该业务进程的物理内存占用量不超过1G。
分析:
使用命令“jcmd <pid> VM.native_memory detail”可以看到所有受JVM监控的内存分布情况:

上图只是截取了nmt(Native Memory Tracking)命令展示的概览信息,这个业务进程占用的2.2G物理内存中,受JVM监控的大概只占了0.7G(上图中的committed),意味着有1.5G物理内存不受JVM管控。JVM可以监控到Java堆、元空间、CodeCache、直接内存等区域,但无法监控到那些由JVM之外的Native Code申请的内存,例如典型的场景是,一个第三方so库中调用malloc了一片内存的行为就无法被JVM感知到。
nmt除了会展示概览之外,还会详细罗列每一片受JVM监控的内存,包括其地址,将这些JVM监控到的内存布局跟用pmap得到的完整的进程内存布局做一个对比筛查,这里忽略nmt和pmap(下图pmap命令中25600是进程号)详细内存地址的信息,直接给出最可疑的那块内存:
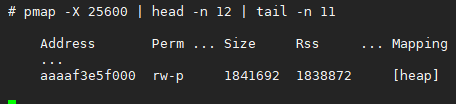
由图可知,这片1.7G左右的内存区域属于系统层面的堆区。
备注:这片系统堆区之所以稍大于上面计算得到的差值,原因大概是nmt中显示的committed内存并不对应真正占用的物理内存(linux使用Lazy策略管理进程内存),实际通常会稍小。
系统堆区主要就是由libc库接口malloc申请的内存组合而成,所以接下来就是去跟踪业务进程中的每次malloc调用,上GDB:

实际上会有大量的干扰项,这些干扰项一方面来自JVM内部,比如:

这部分干扰项很容易被排除,凡是调用栈中存在“os::malloc”这个栈帧的干扰项就可以直接忽视,因为这些malloc行为都会被nmt监控到,而上面已经排除了受JVM监控内存泄漏的可能。
另一部分干扰项则来自JDK,比如:

有如上图所示,不少JDK的本地方法中直接或间接调用了malloc,这部分malloc行为通常是不受JVM监控的,所以需要根据具体情况逐个排查,还是以上图为例,排查过程如下:
注意图中临时中断的值(0x0000ffff5fc55d00)来自于第一个中断b malloc中断发生后的结果。
这里稍微解释一下上面GDB在做的排查过程,就是检查malloc返回的内存地址后续是否有通过free释放(通过tb free if $x0 ==$X3这个命令,具体用法可以参考gdb调试),显然在这个例子中是有释放的。
通过这种排查方式,几经筛选,最终找到了一个可疑的malloc场景:

从调用栈信息可以知道,这是一个JDK中的本地方法sun.nio.fs.UnixNativeDispatcher.opendir0,作用是打开一个目录,但后续始终没有进行关闭操作。进一步分析可知,该可疑opendir操作会周期性执行,而且都是操作同一个目录“/xxx/nginx/etc/nginx/conf”,看来,是有个业务线程在定时访问nginx的配置目录,每次访问完却没有关闭打开的目录。
分析到这里,其实这个问题已经差不多水落石出。跟业务方确认,存在一个定时器线程在周期性读取nginx的配置文件,代码大概是这样子的:
翻了一下相关JDK源码,Files.list方法是有在末尾注册一个关闭钩子的:
也就是说,Files.list方法返回的目录资源是需要手动释放的,否则就会发生资源泄漏。
由于这个目录资源底层是会关联一个fd的,所以泄漏问题还可以通过另一个地方进行佐证:
该业务进程目前已经消耗了51116个fd!
假设这些fd都是opendir关联的,每个opendir消耗32K,则总共消耗1.6G,显然可以跟上面泄漏的内存值基本对上。
总结:
稍微了解了一下,发现几乎没人知道JDK方法Files.list是需要关闭的,这个案例算是给大家都提了个醒。
为了研究透Linux和JVM 的内存结构,写了一个小程序,如下
public class MemoryTest {
private static final byte[] array = new byte[1024*1024];
private static final long size = 1024*1024*10 ;
public static void main(String[] args) {
File file = new File("/webapp/test/mmap.buf");
try {
RandomAccessFile randomAccessFile = new RandomAccessFile(file,"rw");
MappedByteBuffer mappedByteBuffer = randomAccessFile.getChannel().map(FileChannel.MapMode.READ_WRITE,0,1024*1024*10);
long count = size/1024/4;
for(int i = 0 ;i< count;i+=(1024*4)){
mappedByteBuffer.put(i,(byte)0);
}
System.out.println("this is array size :"+array.length);
} catch (Exception e) {
throw new RuntimeException(e);
}
ThreadPoolUtils.getThreadPool().execute(()->{
System.out.println("start execute task.");
int i = 0 ;
while(true){
System.out.println("this is "+i+" times");
try {
Thread.sleep(60*1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
System.out.println("main method is complete.");
}
}分别运行jmap -heap , jstack -l , jcmd VM.native_memory detail ,pmap -X pid ,cat /proc/pid/smaps, 以及cat /proc/[pid]/status |grep VmPeak -A 14 分别得到以下文件:
















 7263
7263











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









