








这次要说的点依旧不大,主要想给大家讲的是如果发现 Flink on Yarn 定位Native Memory超出限制一个排查思路加上第二篇文章讲的Direct Memory相关。第四篇我大概率会讲一个堆内存相关的案例。
背景
这次问题发生是在18年,我们开始调研Flink。当时运维帮忙搭建了一个不大的hadoop集群,提供给我们提交perjob任务。本以为可以开开心心的学习Flink,然鹅过程走的确实灰常艰难。
现象
Flink的Taskmanager跑一段时间就会挂掉 ,在Yarn Nodemanager日志就会发现Container 内存超了。无论怎么加内存, Taskmanager迟早都会挂掉。
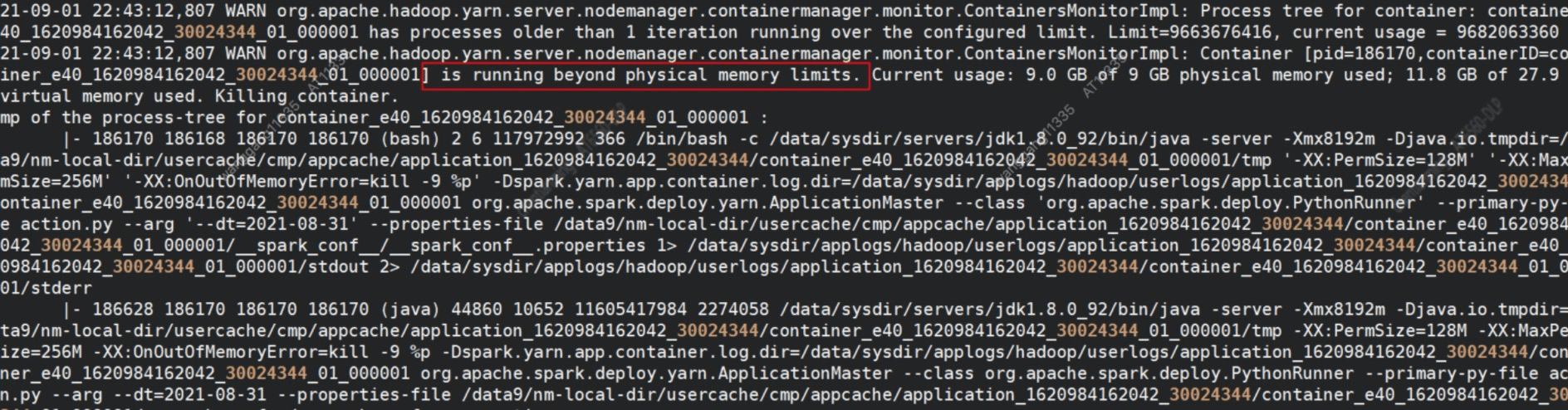
(当时没有保存现场,这张图找离线的同学要的)
排查过程1: 跟进Jobmanager (AM) 启动时Taskmanager(Container)的内存分配
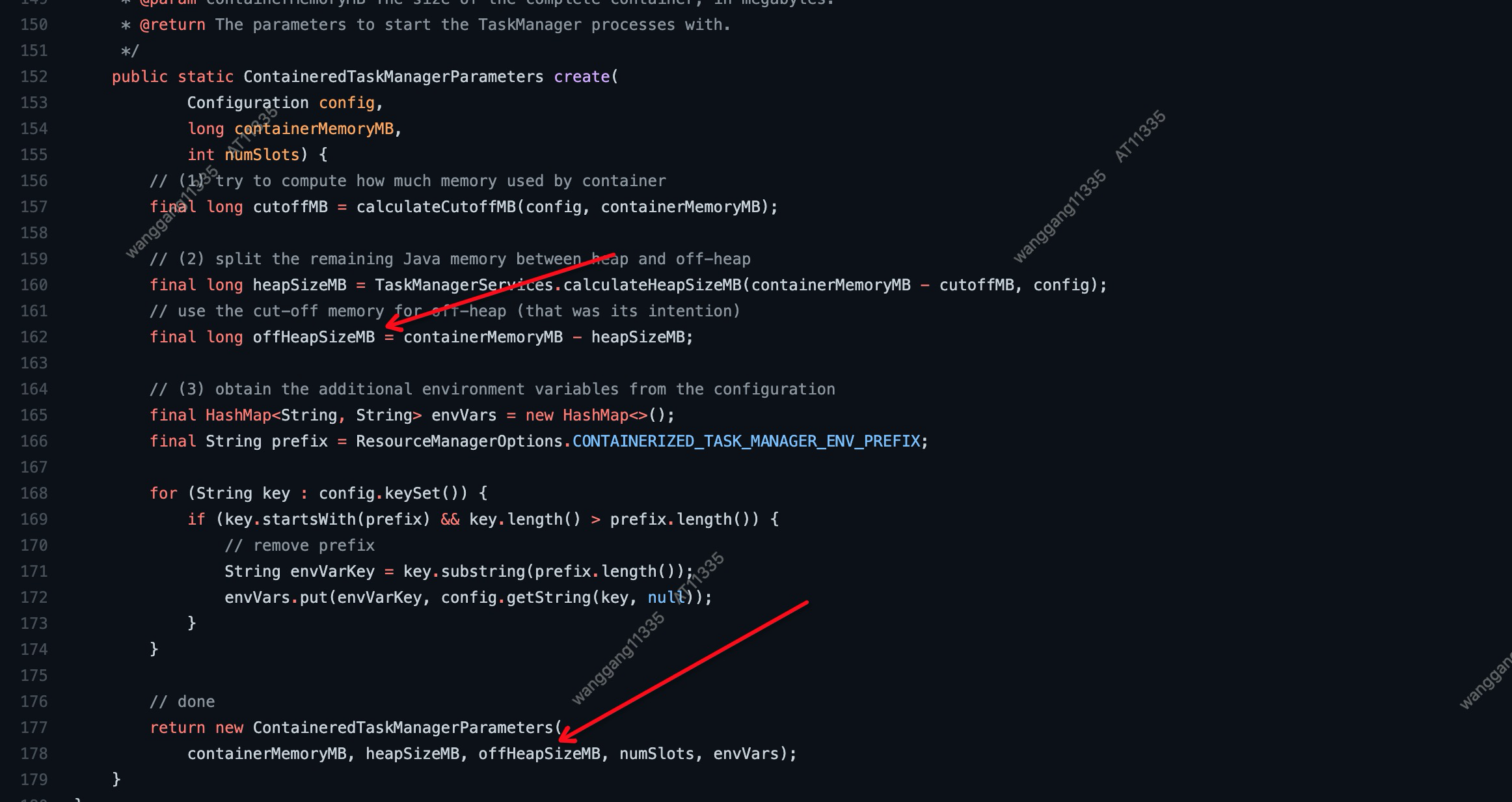
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









