






学完爬虫之后第一次实际尝试爬取信息,东拼西凑终于完成
这一部分获取所需页面内的所有租房信息的相关链接,并存入列表方便后续操作
# 基础URL
base_url = "https://nanjing.zu.fang.com/house/pn{}"
links=[]
# 获取当前页码内有关租房信息的链接
def get_link(url):
resp = requests.get(url)
resp_context = resp.text
soup = BeautifulSoup(resp_context, 'html.parser')
# 找到所有包含链接的dl元素
dl_elements = soup.find_all('dl', class_='list hiddenMap rel')
# 提取链接并存入列表
for dl in dl_elements:
a_tag = dl.find('a')
if a_tag:
link = urljoin(url, a_tag['href'])
links.append(link)
# 访问不同的页码
urls = [base_url.format(i) for i in range(1, 11)]
for url in urls:
get_link(url)这段代码是参考房天下网站二手房爬虫、数据清洗及可视化(python)对房天下偶尔出现的验证界面的处理
def get_real(url):
resp = requests.get(url, headers=header)
soup = BeautifulSoup(resp.content, 'html.parser', from_encoding='gb18030')
if soup.find('title').text.strip() == '跳转...':
pattern1 = re.compile(r"var t4='(.*?)';")
script = soup.find("script", text=pattern1)
t4 = pattern1.search(str(script)).group(1)
pattern1 = re.compile(r"var t3='(.*?)';")
script = soup.find("script", text=pattern1)
t3 = re.findall(pattern1, str(script))[-2]
url = t4 + '?' + t3
HTML = requests.get(url, headers=header)
soup = BeautifulSoup(HTML.content, 'html.parser', from_encoding='gb18030')
elif soup.find('title').text.strip() == '访问验证-房天下':
pass
return soup主要的爬取过程如下
for i, url in enumerate(links, start=1):
print(f'>>> 正在获取 {url}')
trline = []
trlitem = []
soup = get_real(url)
trline = soup.find_all('div', class_='tr-line clearfix')
trlitem = soup.find_all('div', class_='trl-item2 clearfix')
if len(trlitem) == 2:
trlitem.append(trlitem[1])
trlitem[1] = None
distance = None
else:
distance = trlitem[1].find('div', class_='rcont').find('a').getText().strip()
facilities = soup.find('div', class_='content-item zf_new_ptss')
if facilities is not None:
facilities_cleaned = clean(facilities.find('div', class_='cont clearfix').getText().strip())
highlights = soup.find('div', class_='fyms_con floatl gray3').getText().strip()
highlights_cleaned = clean(highlights)
result = {
"序号": i,
"城市": "南京",
"房屋租金": soup.find('div', class_='trl-item sty1').find('i').getText().strip(),
"支付方式": soup.find('div', class_='trl-item sty1').find('a').getText().strip(),
"出租方式": trline[0].find('div', class_='trl-item1 w146').find('div', class_='tt').
find('a').getText().strip(),
"房屋户型": trline[0].find('div', class_='trl-item1 w182').find('div', class_='tt').
getText().strip(),
"房屋面积": trline[0].find('div', class_='trl-item1 w132').find('div', class_='tt').
getText().strip(),
"房屋朝向": trline[1].find('div', class_='trl-item1 w146').
find('div', class_='tt').getText().strip(),
"楼层": trline[1].find('div', class_='trl-item1 w182').
find('div', class_='tt').getText().strip(),
"房屋装修": trline[1].find('div', class_='trl-item1 w132').
find('div', class_='tt').getText().strip(),
"小区": trlitem[0].find('div', class_='rcont').find('a').getText().strip(),
"距地铁的距离": distance,
"地址": trlitem[2].find('div', class_='rcont').find('a').getText().strip(),
"配套设施": facilities_cleaned,
"房源亮点": highlights_cleaned
}
if trlitem[1] is not None:
result["距地铁的距离"] = trlitem[1].find('div', class_='rcont').find('a').getText().strip()
else:
result["距地铁的距离"] = "None"
print(result)
result_list.append(result)
time.sleep(5) # 为了避免给网站造成过多负担,可以添加适当的延迟其中有些愚蠢的处理,但我想不到其他方法,所以就简单操作了
例如这段,是facilities针对配套设施缺少进行的处理
highlights是为了处理多余的字符('\n')所以单独拎出来写的,
facilities = soup.find('div', class_='content-item zf_new_ptss')
if facilities is not None:
facilities_cleaned = clean(facilities.find('div', class_='cont clearfix').getText().strip())
highlights = soup.find('div', class_='fyms_con floatl gray3').getText().strip()
highlights_cleaned = clean(highlights)之后在获取离地铁的距离部分也进行了处理,一开始主观认为信息不会缺失,所以直接用find_all()函数获取了class = 'tr-line clearfix'的所有div元素,但实际过程中出现了一部分租房信息缺少这部分内容的情况。
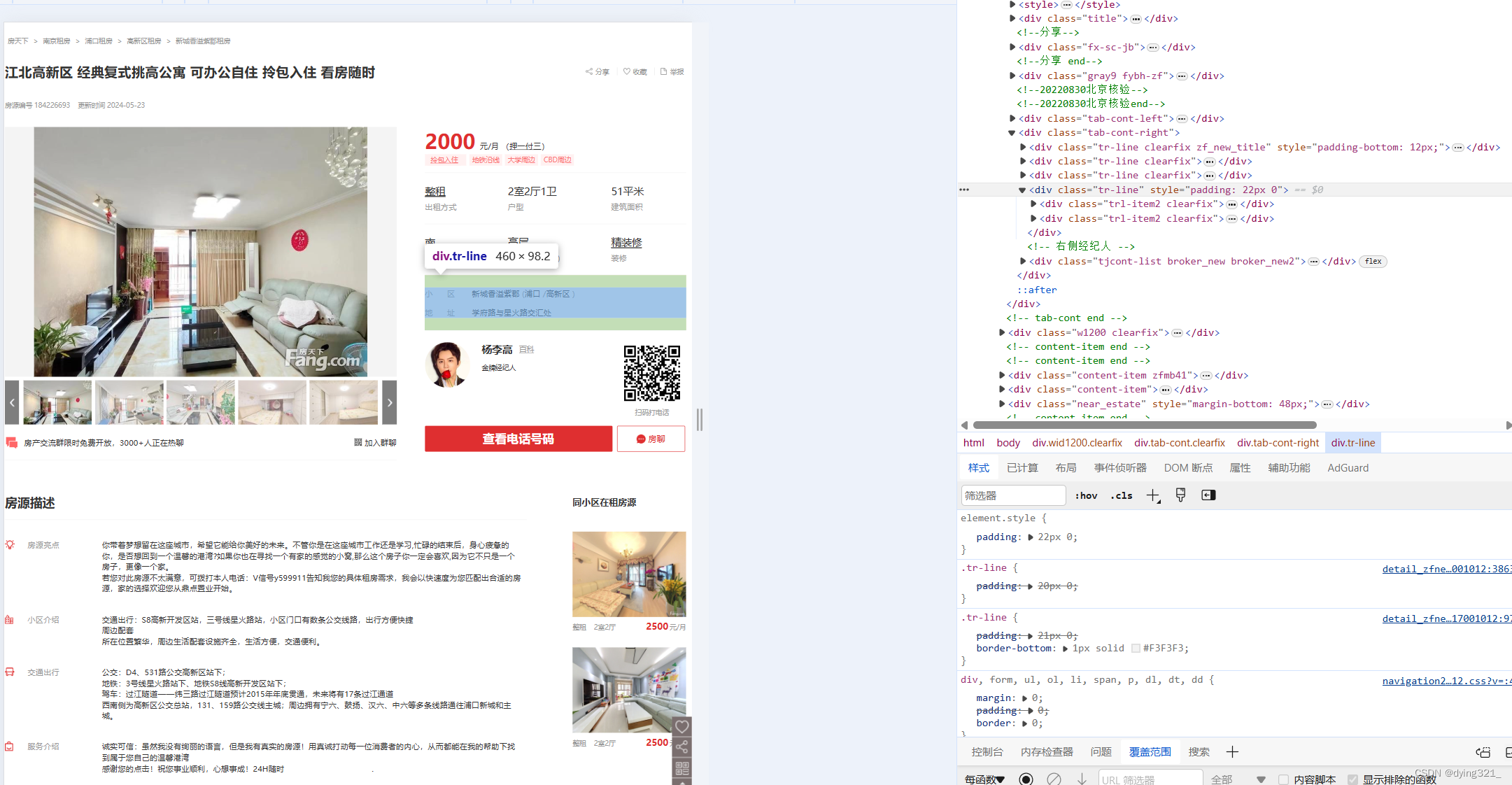
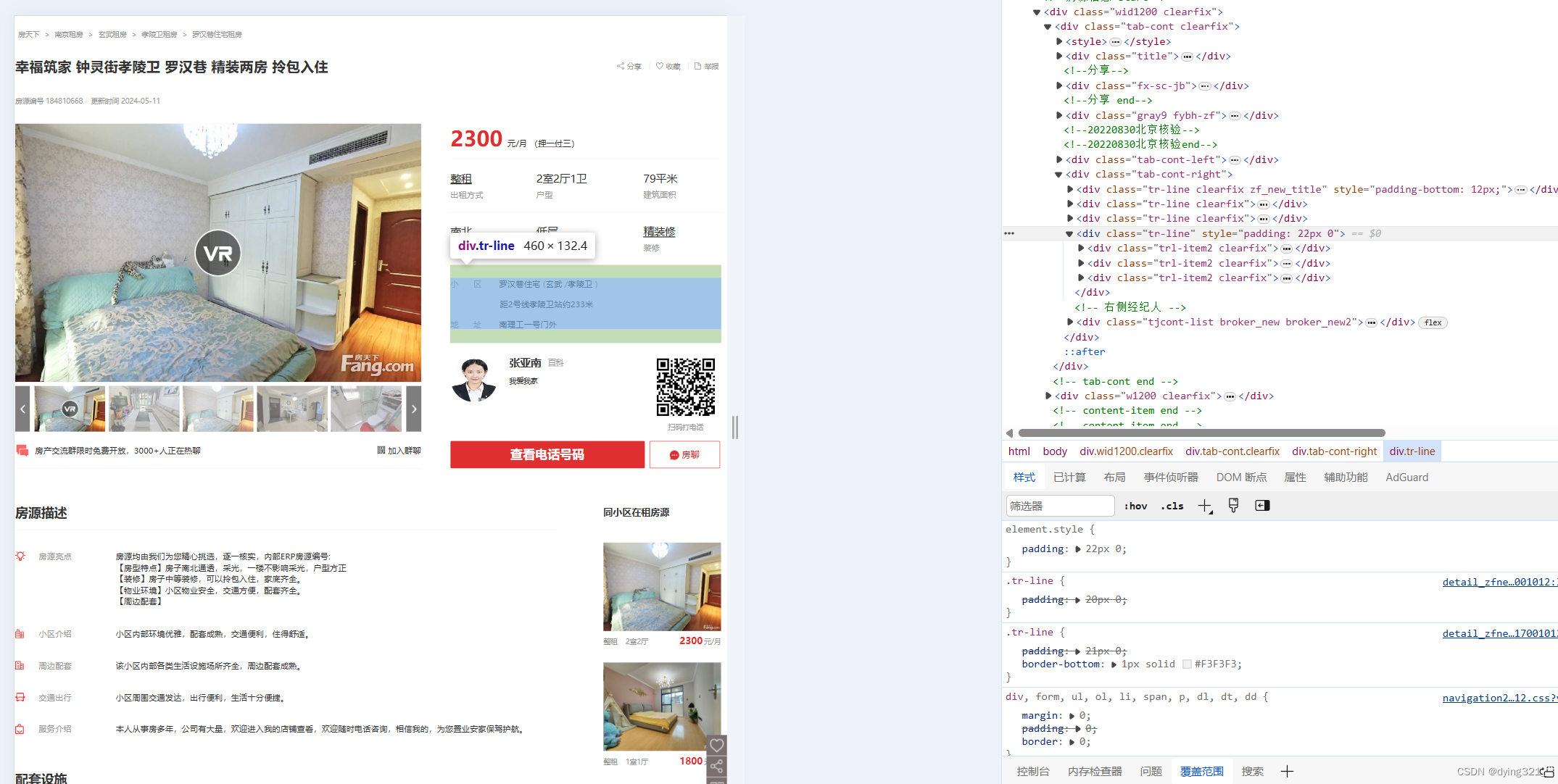
因此对于缺少离地铁的距离的信息,人为插入一个空元素,并在result字典中不对其进行操作,在字典外再进行trlitem[1]是否为None的判定
if len(trlitem) == 2:
trlitem.append(trlitem[1])
trlitem[1] = None
distance = None
else:
distance = trlitem[1].find('div', class_='rcont').find('a').getText().strip()
***省略其中代码***
if trlitem[1] is not None:
result["距地铁的距离"] = trlitem[1].find('div', class_='rcont').find('a').getText().strip()
else:
result["距地铁的距离"] = "None"
最后是源码,源码中将获取到的信息存入列表,再存入了csv文件,方便直接调用或者交给其他人使用
"""
@filename:rent_data.py
@author:dying
@time:2024-05-24
"""
import re
from collections import Counter
from urllib.parse import urljoin
import requests
from bs4 import BeautifulSoup
import csv
import requests
from lxml import etree
import time
# 基础URL
# 更换地点时只需将nanjing换掉
base_url = "https://nanjing.zu.fang.com/house/pn{}"
# 记录所有的链接
links = []
# 记录所有的结果
result_list = []
#模拟访问网站的身份
header = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) '
'AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/64.0.3282.186 Safari/537.36'}
# 获取当前页面下有关租房信息的链接
def get_link(url):
resp = requests.get(url)
resp_context = resp.text
soup = BeautifulSoup(resp_context, 'html.parser')
# 找到所有包含链接的dl元素
dl_elements = soup.find_all('dl', class_='list hiddenMap rel')
# 提取链接并存入列表
for dl in dl_elements:
a_tag = dl.find('a')
if a_tag:
link = urljoin(url, a_tag['href'])
links.append(link)
def get_real(url):
resp = requests.get(url, headers=header)
soup = BeautifulSoup(resp.content, 'html.parser', from_encoding='gb18030')
if soup.find('title').text.strip() == '跳转...':
pattern1 = re.compile(r"var t4='(.*?)';")
script = soup.find("script", text=pattern1)
t4 = pattern1.search(str(script)).group(1)
pattern1 = re.compile(r"var t3='(.*?)';")
script = soup.find("script", text=pattern1)
t3 = re.findall(pattern1, str(script))[-2]
url = t4 + '?' + t3
HTML = requests.get(url, headers=header)
soup = BeautifulSoup(HTML.content, 'html.parser', from_encoding='gb18030')
elif soup.find('title').text.strip() == '访问验证-房天下':
pass
return soup
def clean(data):
return ''.join(data.split())
# 访问不同的页码,修改range内的值即可
urls = [base_url.format(i) for i in range(1, 11)]
for url in urls:
get_link(url)
for i, url in enumerate(links, start=1):
print(f'>>> 正在获取 {url}')
trline = []
trlitem = []
soup = get_real(url)
trline = soup.find_all('div', class_='tr-line clearfix')
trlitem = soup.find_all('div', class_='trl-item2 clearfix')
if len(trlitem) == 2:
trlitem.append(trlitem[1])
trlitem[1] = None
distance = None
else:
distance = trlitem[1].find('div', class_='rcont').find('a').getText().strip()
facilities = soup.find('div', class_='content-item zf_new_ptss')
if facilities is not None:
facilities_cleaned = clean(facilities.find('div', class_='cont clearfix').getText().strip())
highlights = soup.find('div', class_='fyms_con floatl gray3').getText().strip()
highlights_cleaned = clean(highlights)
result = {
"序号": i,
"城市": "南京", #按需更换
"房屋租金": soup.find('div', class_='trl-item sty1').find('i').getText().strip(),
"支付方式": soup.find('div', class_='trl-item sty1').find('a').getText().strip(),
"出租方式": trline[0].find('div', class_='trl-item1 w146').find('div', class_='tt').
find('a').getText().strip(),
"房屋户型": trline[0].find('div', class_='trl-item1 w182').find('div', class_='tt').
getText().strip(),
"房屋面积": trline[0].find('div', class_='trl-item1 w132').find('div', class_='tt').
getText().strip(),
"房屋朝向": trline[1].find('div', class_='trl-item1 w146').
find('div', class_='tt').getText().strip(),
"楼层": trline[1].find('div', class_='trl-item1 w182').
find('div', class_='tt').getText().strip(),
"房屋装修": trline[1].find('div', class_='trl-item1 w132').
find('div', class_='tt').getText().strip(),
"小区": trlitem[0].find('div', class_='rcont').find('a').getText().strip(),
"距地铁的距离": distance,
"地址": trlitem[2].find('div', class_='rcont').find('a').getText().strip(),
"配套设施": facilities_cleaned,
"房源亮点": highlights_cleaned
}
if trlitem[1] is not None:
result["距地铁的距离"] = trlitem[1].find('div', class_='rcont').find('a').getText().strip()
else:
result["距地铁的距离"] = "None"
print(result)
result_list.append(result)
time.sleep(5) # 为了避免给网站造成过多负担,可以添加适当的延迟
# 这个值几乎不触发验证
print(result_list)
# 将字典列表写入CSV文件
fieldnames = ['序号', '城市', '房屋租金', '支付方式', '出租方式', '房屋户型', '房屋面积', '房屋朝向', '楼层',
'房屋装修', '小区', '距地铁的距离', '地址', '配套设施', '房源亮点']
with open('rent_data.csv', mode='w', newline='', encoding='utf-8') as file:
writer = csv.DictWriter(file, fieldnames=fieldnames)
# 写入表头
writer.writeheader()
# 写入数据
for data in result_list:
writer.writerow(data)















 3263
3263











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









