






Druid连接池
声明:以下内容均来自GitHub及其他博客的整理总结,仅供个人学习使用。1. Druid连接池简介
1.1 Druid简介
DRUID是阿里巴巴开源平台上一个数据库连接池实现,它结合了C3P0、DBCP、PROXOOL等DB池的优点,同时加入了日志监控,可以很好的监控DB池连接和SQL的执行情况,可以说是针对监控而生的DB连接池。
1.2 Druid组成
Druid是一个JDBC组件,它包括三个部分:
l 基于Filter-Chain模式的插件体系
l DruidDataSource 高效可管理的数据库连接池
l SQLParser
1.3 Druid功能简介
(1)替换DBCP和C3P0。Druid提供了一个高效、功能强大、可扩展性好的数据库连接池。
(2)可以监控数据库访问性能,Druid内置提供了一个功能强大的StatFilter插件,能够详细统计SQL的执行性能,这对于线上分析数据库访问性能有帮助。
(3)数据库密码加密。直接把数据库密码写在配置文件中,这是不好的行为,容易导致安全问题。DruidDriver和DruidDataSource都支持PasswordCallback。
(4)SQL执行日志,Druid提供了不同的LogFilter,能够支持Common-Logging、Log4j和JdkLog,你可以按需要选择相应的LogFilter,监控你应用的数据库访问情况。
(5)扩展JDBC,如果你要对JDBC层有编程的需求,可以通过Druid提供的Filter机制,很方便编写JDBC层的扩展插件。
2. 基本参数配置
2.1 配置参数
配置 | 缺省值 | 说明 |
name |
| 配置这个属性的意义在于,如果存在多个数据源,监控的时候可以通过名字来区分开来。 |
jdbcUrl |
| 连接数据库的url,不同数据库不一样。例如: |
username |
| 连接数据库的用户名 |
password |
| 连接数据库的密码。如果你不希望密码直接写在配置文件中,可以使用ConfigFilter。详细看这里:https://github.com/alibaba/druid/wiki/%E4%BD%BF%E7%94%A8ConfigFilter |
driverClassName | 根据url自动识别 | 这一项可配可不配,如果不配置druid会根据url自动识别dbType,然后选择相应的driverClassName(建议配置下) |
initialSize | 0 | 初始化时建立物理连接的个数。初始化发生在显示调用init方法,或者第一次getConnection时 |
maxActive | 8 | 最大连接池数量 |
maxIdle | 8 | 已经不再使用,配置了也没效果 |
minIdle |
| 最小连接池数量 |
maxWait |
| 获取连接时最大等待时间,单位毫秒。配置了maxWait之后,缺省启用公平锁,并发效率会有所下降,如果需要可以通过配置useUnfairLock属性为true使用非公平锁。 |
poolPreparedStatements | false | 是否缓存preparedStatement,也就是PSCache。PSCache对支持游标的数据库性能提升巨大,比如说oracle。在mysql下建议关闭。 |
maxOpenPreparedStatements | -1 | 要启用PSCache,必须配置大于0,当大于0时,poolPreparedStatements自动触发修改为true。在Druid中,不会存在Oracle下PSCache占用内存过多的问题,可以把这个数值配置大一些,比如说100 |
validationQuery |
| 用来检测连接是否有效的sql,要求是一个查询语句。如果validationQuery为null,testOnBorrow、testOnReturn、testWhileIdle都不会其作用。 |
testOnBorrow | true | 申请连接时执行validationQuery检测连接是否有效,做了这个配置会降低性能。 |
testOnReturn | false | 归还连接时执行validationQuery检测连接是否有效,做了这个配置会降低性能 |
testWhileIdle | false | 建议配置为true,不影响性能,并且保证安全性。申请连接的时候检测,如果空闲时间大于timeBetweenEvictionRunsMillis,执行validationQuery检测连接是否有效。 |
timeBetweenEvictionRunsMillis |
| 有两个含义: 2) testWhileIdle的判断依据,详细看testWhileIdle属性的说明 |
numTestsPerEvictionRun |
| 不再使用,一个DruidDataSource只支持一个EvictionRun |
minEvictableIdleTimeMillis |
| |
connectionInitSqls |
| 物理连接初始化的时候执行的sql |
exceptionSorter | 根据dbType自动识别 | 当数据库抛出一些不可恢复的异常时,抛弃连接 |
filters |
| 属性类型是字符串,通过别名的方式配置扩展插件,常用的插件有: |
proxyFilters |
| 类型是List<com.alibaba.druid.filter.Filter>,如果同时配置了filters和proxyFilters,是组合关系,并非替换关系 |
2.2 参考配置
<bean id="dataSource" class="com.alibaba.druid.pool.DruidDataSource" init-method="init" destroy-method="close"> <!-- 基本属性 url、user、password --> <property name="url" value="${jdbc_url}" /> <property name="username" value="${jdbc_user}" /> <property name="password" value="${jdbc_password}" />
<!-- 配置初始化大小、最小、最大 --> <property name="initialSize" value="1" /> <property name="minIdle" value="1" /> <property name="maxActive" value="20" />
<!-- 配置获取连接等待超时的时间 --> <property name="maxWait" value="60000" />
<!-- 配置间隔多久才进行一次检测,检测需要关闭的空闲连接,单位是毫秒 --> <property name="timeBetweenEvictionRunsMillis" value="60000" />
<!-- 配置一个连接在池中最小生存的时间,单位是毫秒 --> <property name="minEvictableIdleTimeMillis" value="300000" />
<property name="validationQuery" value="SELECT 'x'" /> <property name="testWhileIdle" value="true" /> <property name="testOnBorrow" value="false" /> <property name="testOnReturn" value="false" />
<!-- 打开PSCache,并且指定每个连接上PSCache的大小 --> <property name="poolPreparedStatements" value="true" /> <property name="maxPoolPreparedStatementPerConnectionSize" value="20" />
<!-- 配置监控统计拦截的filters --> <property name="filters" value="stat" /> </bean> |
通常来说,只需要修改initialSize、minIdle、maxActive。
如果用Oracle,则把poolPreparedStatements配置为true,mysql可以配置为false。分库分表较多的数据库,建议配置为false。
3. 与其他连接池的对比
3.1 性能比较
功能 | DBCP | Druid | c3p0 | tomcat-jdbc | HikariCP |
是否支持PSCache | 是 | 是 | 是 | 否 | 否 |
监控 | jmx | jmx/log/http | jmx,log | jmx | jmx |
扩展性 | 弱 | 好 | 弱 | 弱 | 弱 |
sql拦截及解析 | 无 | 支持 | 无 | 无 | 无 |
代码 | 简单 | 中等 | 复杂 | 简单 | 简单 |
特点 | 依赖于common-pool | 阿里开源,功能全面 | 历史久远,代码逻辑复杂,且不易维护 | 优化力度大,功能简单,起源于boneCP | |
连接池管理 | LinkedBlockingDeque | 数组 | FairBlockingQueue | threadlocal+CopyOnWriteArrayList |
(1)性能方面 HikariCP>Druid>tomcat-jdbc>dbcp>c3p0。HikariCP的高性能得益于最大限度的避免锁竞争。
(2)Druid功能最为全面,sql拦截等功能,统计数据较为全面,具有良好的扩展性。
(3)综合性能,扩展性等方面,可考虑使用druid或者hikariCP连接池。
(4)可开启prepareStatement缓存,对性能会有大概20%的提升。
3.2 特有功能说明
3.2.1 ExceptionSorter
当网络断开或者数据库服务器Crash时,连接池里面会存在“不可用连接”,连接池需要一种机制剔除这些“不可用连接”。在Druid和JBoss连接池中,剔除“不可用连接”的机制称为ExceptionSorter,实现的原理是根据异常类型/Code/Reason/Message来识别“不可用连接”。没有类似ExceptionSorter的连接池,在数据库重启或者网络中断之后,不能恢复工作,所以ExceptionSorter是连接池是否稳定的重要标志。在Druid中,会根据连接池连接数据库的类型自动匹配不同类型的ExceptionSorter,不需要额外配置。
以下是Druid内置的ExceptionSorter:
dbType | ExceptionSorter Implementation | description |
DB2 | com.alibaba.druid.pool.vendor.DB2ExceptionSorter | |
Informix | com.alibaba.druid.pool.vendor.InformixExceptionSorter | |
SQL Server | com.alibaba.druid.pool.vendor.MSSQLValidConnectionChecker | |
MySQL | com.alibaba.druid.pool.vendor.MySqlExceptionSorter | 支持OceanBase和阿里云RDS特定的ErrorCode |
Oracle | com.alibaba.druid.pool.vendor.OracleExceptionSorter | |
Postgresql | com.alibaba.druid.pool.vendor.PGExceptionSorter | |
Sybase | com.alibaba.druid.pool.vendor.SybaseExceptionSorter |
3.2.2 Oracle数据库下PreparedStatementCache内存问题解决方案
Oracle支持游标,一个PreparedStatement对应服务器一个游标,如果PreparedStatement被缓存起来重复执行,PreparedStatement没有被关闭,服务器端的游标就不会被关闭,性能提高非常显著。在类似SELECT * FROM T WHERE ID =?这样的场景,性能可能是一个数量级的提升。
由于PreparedStatementCache性能提升明显,DruidDataSource、DBCP、JBossDataSource、WeblogicDataSource都实现了PreparedStatementCache。
但是Oracle 10系列的Driver,如果开启PSCache,会占用大量的内存。通过分析发现占内存的是字段char[] defineChars。defineChars大小的计算公式是这样的:
defineChars大小 = rowSize * rowPrefetchCount |
rowPrefetchCount在Oracle中,缺省值为10。
其中rowSize是执行查询设计的每一列的大小的和。计算公式是:
rowSize = col_1_size + col_2_size + ... + col_n_size |
有些列数据类型是varchar2(4000),于是rowSize巨大,很多个表关联的SQL,rowSize可能高达数十K,再乘以rowPrefetchCount,defineChars大小接近1M。可以想想,maxPoolSize设置为30,PreparedStatementCacheSize设置为50的场景下,是可能导致PreparedStatementCache占据上G的内存。
实际占据内存的公式:
占据内存大小峰值 = defineChars大小 * PreparedStatementCacheSize * MaxPoolSize |
一个应用运行的SQL大约数百条,PreparedStatementCacheSize为50,PreparedStatementCache的算法为LRU,很多的SQL执行之后,在Cache中HitCount为0就被淘汰了,淘汰的过程,其位置从第1移到第50,这个漫长的过程导致了defineChars不能够被young gc回收。
解决方案:
使用OracleDriver提供的PreparedStatementCache支持方法,清理PreparedStatement所持有的buffer。 Oracle在10.x和11.x的Driver中,都提供了如下管理PreparedStatementCache的接口,如下:
package oracle.jdbc.internal; import java.sql.SQLException; public interface OraclePreparedStatement extends oracle.jdbc.OraclePreparedStatement, OracleStatement { public void enterImplicitCache() throws SQLException; public void exitImplicitCacheToActive() throws SQLException; public void exitImplicitCacheToClose() throws SQLException; } |
DruidDataSource在管理Oracle PreparedStatementCache时,调用了上述方法。当调用了enterImplicitCache之后,T4CPreparedStatement中的defineChars和defineBytes都会被清空。
测试表明,通过上述处理,能够有效降低内存。
4. Filter配置说明
4.1 配置Filter
DruidDataSource支持通过Filter-Chain模式进行扩展,类似Serlvet的Filter,扩展十分方便,你可以拦截任何JDBC的方法。
有两种配置Filter的方式,一种是配置filters属性,一种是配置proxyFilters属性。filters和proxyFilters的配置是组合关系,而不是替换关系。
4.1.1 配置Filter属性
配置filters属性比较简单,filters的类型是字符串,多个filter使用逗号隔开。例如:
<bean id="dataSource" class="com.alibaba.druid.pool.DruidDataSource" init-method="init" destroy-method="close"> <property name="url" value="jdbc:derby:memory:spring-test;create=true" /> <property name="initialSize" value="1" /> <property name="maxActive" value="20" /> <property name="filters" value="stat,log4j" /> </bean> |
Filters属性的配置使用别名或者全类名,以下是内置Filter的别名:
Filter类名 | 别名 |
default | com.alibaba.druid.filter.stat.StatFilter |
stat | com.alibaba.druid.filter.stat.StatFilter |
mergeStat | com.alibaba.druid.filter.stat.MergeStatFilter |
encoding | com.alibaba.druid.filter.encoding.EncodingConvertFilter |
log4j | com.alibaba.druid.filter.logging.Log4jFilter |
log4j2 | com.alibaba.druid.filter.logging.Log4j2Filter |
slf4j | com.alibaba.druid.filter.logging.Slf4jLogFilter |
commonlogging | com.alibaba.druid.filter.logging.CommonsLogFilter |
wall | com.alibaba.druid.wall.WallFilter |
4.1.2 配置proxyFilter属性
proxyFilters的类型是List,使用proxyFilters配置,可以有更多的配置选项:
<bean id="stat-filter" class="com.alibaba.druid.filter.stat.StatFilter"> </bean>
<bean id="dataSource" class="com.alibaba.druid.pool.DruidDataSource" init-method="init" destroy-method="close"> <property name="url" value="jdbc:derby:memory:spring-test;create=true" /> <property name="initialSize" value="1" /> <property name="maxActive" value="20" /> <property name="proxyFilters"> <list> <ref bean="stat-filter" /> </list> </property> </bean> |
4.2 配置StatFilter
Druid内置提供一个StatFilter,用于统计监控信息。
4.2.1 别名配置
StatFilter的别名是stat,这个别名映射配置信息保存在druid-xxx.jar!/META-INF/druid-filter.properties。在spring中使用别名配置方式如下:
<bean id="dataSource" class="com.alibaba.druid.pool.DruidDataSource" init-method="init" destroy-method="close"> ... ... <property name="filters" value="stat" /> </bean> |
4.2.2 组合配置
StatFilter可以和其他的Filter配置使用,比如:
<bean id="dataSource" class="com.alibaba.druid.pool.DruidDataSource" init-method="init" destroy-method="close"> ... ... <property name="filters" value="stat,log4j" /> </bean> |
在上面的配置中,StatFilter和Log4jFilter组合使用。
4.2.3 通过ProxyFilters属性配置
别名配置是通过filters属性配置的,filters属性的类型是String。如果需要通过bean的方式配置,使用proxyFilters属性。
<bean id="stat-filter" class="com.alibaba.druid.filter.stat.StatFilter"> <property name="slowSqlMillis" value="10000" /> <property name="logSlowSql" value="true" /> </bean> <bean id="dataSource" class="com.alibaba.druid.pool.DruidDataSource" init-method="init" destroy-method="close"> ... ... <property name="filters" value="log4j" /> <property name="proxyFilters"> <list> <ref bean="stat-filter" /> </list> </property> </bean> |
其中filters和proxyFilters属性是组合关系的,不是替换的,在上面的配置中,dataSource有了两个Filter,StatFilter和Log4jFilter。
4.2.4 SQL合并配置
当你程序中存在没有参数化的sql执行时,sql统计的效果会不好。比如:
select * from t where id = 1 select * from t where id = 2 select * from t where id = 3 |
在统计中,显示为3条sql,这不是我们希望要的效果。StatFilter提供合并的功能,能够将这3个SQL合并为如下的SQL:
select * from t where id = ? |
配置StatFilter的mergeSql属性:
<bean id="stat-filter" class="com.alibaba.druid.filter.stat.StatFilter"> <property name="mergeSql" value="true" /> </bean> <bean id="dataSource" class="com.alibaba.druid.pool.DruidDataSource" init-method="init" destroy-method="close"> ... ... <property name="proxyFilters"> <list> <ref bean="stat-filter" /> </list> </property> </bean> |
StatFilter支持一种简化配置方式,和上面的配置等同的。如下:
<bean id="dataSource" class="com.alibaba.druid.pool.DruidDataSource" init-method="init" destroy-method="close"> ... ... <property name="filters" value="mergeStat" /> </bean> |
mergeStat是的MergeStatFilter缩写,我们看MergeStatFilter的实现:
public class MergeStatFilter extends StatFilter { public MergeStatFilter() { super.setMergeSql(true); } } |
从实现代码来看,仅仅是一个mergeSql的缺省值。
也可以通过connectProperties属性来打开mergeSql功能,例如:
<bean id="dataSource" class="com.alibaba.druid.pool.DruidDataSource" init-method="init" destroy-method="close"> ... ... <property name="filters" value="stat" /> <property name="connectionProperties" value="druid.stat.mergeSql=true" /> </bean> |
或者通过增加JVM的参数配置:
-Ddruid.stat.mergeSql=true |
在druid-0.2.17版本之后,sql合并支持tddl,能够对分表进行合并。
4.2.5 慢SQL记录
StatFilter属性slowSqlMillis用来配置SQL慢的标准,执行时间超过slowSqlMillis的就是慢。slowSqlMillis的缺省值为3000,也就是3秒。
<bean id="stat-filter" class="com.alibaba.druid.filter.stat.StatFilter"> <property name="slowSqlMillis" value="10000" /> <property name="logSlowSql" value="true" /> </bean> |
在上面的配置中,slowSqlMillis被修改为10秒,并且通过日志输出执行慢的SQL。
slowSqlMillis属性也可以通过connectProperties来配置,例如:
<bean id="dataSource" class="com.alibaba.druid.pool.DruidDataSource" init-method="init" destroy-method="close"> ... ... <property name="filters" value="stat" /> <property name="connectionProperties" value="druid.stat.slowSqlMillis=5000" /> </bean> |
4.2.6 合并多个DruidDataSource的监控数据
缺省多个DruidDataSource的监控数据是各自独立的,在Druid-0.2.17版本之后,支持配置公用监控数据,配置参数为useGlobalDataSourceStat。例如:
<bean id="dataSource" class="com.alibaba.druid.pool.DruidDataSource" init-method="init" destroy-method="close"> ... ... <property name="useGlobalDataSourceStat" value="true" /> </bean> |
或者通过jvm启动参数来指定,例如:
-Ddruid.useGlobalDataSourceStat=true |
全部使用jvm启动参数来配置,可以这样:
-Ddruid.filters=mergeStat -Ddruid.useGlobalDataSourceStat=true |
4.3 配置LogFilter
Druid内置提供了四种LogFilter(Log4jFilter、Log4j2Filter、CommonsLogFilter、Slf4jLogFilter),用于输出JDBC执行的日志。
4.3.1 别名映射
在druid-xxx.jar!/META-INF/druid-filter.properties文件中描述了这四种Filter的别名:
druid.filters.log4j=com.alibaba.druid.filter.logging.Log4jFilter druid.filters.log4j2=com.alibaba.druid.filter.logging.Log4j2Filter druid.filters.slf4j=com.alibaba.druid.filter.logging.Slf4jLogFilter druid.filters.commonlogging=com.alibaba.druid.filter.logging.CommonsLogFilter druid.filters.commonLogging=com.alibaba.druid.filter.logging.CommonsLogFilter |
他们的别名分别是log4j、log4j2、slf4j、commonlogging和commonLogging。其中commonlogging和commonLogging只是大小写不同。
<bean id="dataSource" class="com.alibaba.druid.pool.DruidDataSource" init-method="init" destroy-method="close"> ... ... <property name="filters" value="stat,log4j" /> </bean> |
4.3.2 loggerName配置
LogFilter都是缺省使用四种不同的Logger执行输出,看实现代码:
public abstract class LogFilter { protected String dataSourceLoggerName = "druid.sql.DataSource"; protected String connectionLoggerName = "druid.sql.Connection"; protected String statementLoggerName = "druid.sql.Statement"; protected String resultSetLoggerName = "druid.sql.ResultSet"; } |
你可以根据你的需要修改,在log4j.properties文件上做配置时,注意配置使用相关的logger。
4.3.3 配置输出日志
缺省输入的日志信息全面,但是内容比较多,有时候我们需要定制化配置日志输出。
<bean id="log-filter" class="com.alibaba.druid.filter.logging.Log4jFilter"> <property name="resultSetLogEnabled" value="false" /> </bean>
<bean id="dataSource" class="com.alibaba.druid.pool.DruidDataSource" init-method="init" destroy-method="close"> ... <property name="proxyFilters"> <list> <ref bean="log-filter"/> </list> </property> </bean> |
参数 | 说明 |
dataSourceLogEnabled | 所有DataSource相关的日志 |
connectionLogEnabled | 所有连接相关的日志 |
connectionLogErrorEnabled | 所有连接上发生异常的日志 |
statementLogEnabled | 所有Statement相关的日志 |
statementLogErrorEnabled | 所有Statement发生异常的日志 |
resultSetLogEnabled | |
resultSetLogErrorEnabled | |
connectionConnectBeforeLogEnabled | |
connectionConnectAfterLogEnabled | |
connectionCommitAfterLogEnabled | |
connectionRollbackAfterLogEnabled | |
connectionCloseAfterLogEnabled | |
statementCreateAfterLogEnabled | |
statementPrepareAfterLogEnabled | |
statementPrepareCallAfterLogEnabled | |
statementExecuteAfterLogEnabled | |
statementExecuteQueryAfterLogEnabled | |
statementExecuteUpdateAfterLogEnabled | |
statementExecuteBatchAfterLogEnabled | |
statementCloseAfterLogEnabled | |
statementParameterSetLogEnabled | |
resultSetNextAfterLogEnabled | |
resultSetOpenAfterLogEnabled | |
resultSetCloseAfterLogEnabled |
4.3.4 log4j.properties配置
如果你使用log4j,可以通过log4j.properties文件配置日志输出选项,例如:
log4j.logger.druid.sql=warn,stdout log4j.logger.druid.sql.DataSource=warn,stdout log4j.logger.druid.sql.Connection=warn,stdout log4j.logger.druid.sql.Statement=warn,stdout log4j.logger.druid.sql.ResultSet=warn,stdout |
4.3.5 输出可执行的SQL
Java启动参数配置方式:
-Ddruid.log.stmt.executableSql=true |
logFilter参数直接配置
<bean id="log-filter" class="com.alibaba.druid.filter.logging.Log4jFilter"> <property name="statementExecutableSqlLogEnable" value="true" /> </bean> |
4.4 配置WallFilter
4.4.1 使用缺省配置的WallFilter
<bean id="dataSource" class="com.alibaba.druid.pool.DruidDataSource" init-method="init" destroy-method="close"> ... <property name="filters" value="wall"/> </bean> |
4.4.2 结合其他Filter一起使用
WallFilter可以结合其他Filter一起使用,例如:
<bean id="dataSource" class="com.alibaba.druid.pool.DruidDataSource" init-method="init" destroy-method="close"> ... <property name="filters" value="wall,stat"/> </bean> |
这样,拦截检测的时间不在StatFilter统计的SQL执行时间内。
如果希望StatFilter统计的SQL执行时间内,则使用如下配置:
<bean id="dataSource" class="com.alibaba.druid.pool.DruidDataSource" init-method="init" destroy-method="close"> ... <property name="filters" value="stat,wall"/> </bean> |
4.4.3 指定dbType
有时候,一些应用框架做了自己的JDBC Proxy Driver,是的DruidDataSource无法正确识别数据库的类型,则需要特别指定,如下:
<bean id="wall-filter" class="com.alibaba.druid.wall.WallFilter"> <property name="dbType" value="mysql" /> </bean>
<bean id="dataSource" class="com.alibaba.druid.pool.DruidDataSource" init-method="init" destroy-method="close"> ... <property name="proxyFilters"> <list> <ref bean="wall-filter"/> </list> </property> </bean> |
4.4.4 指定配置装载的目录
缺省情况下,配置装载的目录如下:
数据库类型 | 目录 |
mysql | META-INF/druid/wall/mysql |
oracle | META-INF/druid/wall/oracle |
sqlserver | META-INF/druid/wall/sqlserver |
postgres | META-INF/druid/wall/postgres |
从配置目录中以下文件中读取配置:
deny-variant.txt deny-schema.txt deny-function.txt deny-table.txt deny-object.txt |
指定配置装载的目录是可以指定,例如:
<bean id="wall-filter-config" class="com.alibaba.druid.wall.WallConfig" init-method="init"> <!-- 指定配置装载的目录 --> <property name="dir" value="META-INF/druid/wall/mysql" /> </bean>
<bean id="wall-filter" class="com.alibaba.druid.wall.WallFilter"> <property name="dbType" value="mysql" /> <property name="config" ref="wall-filter-config" /> </bean>
<bean id="dataSource" class="com.alibaba.druid.pool.DruidDataSource" init-method="init" destroy-method="close"> ... <property name="proxyFilters"> <list> <ref bean="wall-filter"/> </list> </property> </bean> |
4.4.5 WallConfig详细说明
Druid提供了WallFilter,它是基于SQL语义分析来实现防御SQL注入攻击的。
4.4.5.1 本身的配置
配置项 | 缺省值 |
dir | 按照dbType分别配置: mysql : META-INF/druid/wall/mysql oracle : META-INF/druid/wall/oracle sqlserver : META-INF/druid/wall/sqlserver |
4.4.5.2 拦截配置-语句
配置项 | 缺省值 | 描述 |
selelctAllow | true | 是否允许执行SELECT语句 |
selectAllColumnAllow | true | 是否允许执行SELECT * FROM T这样的语句。如果设置为false,不允许执行select * from t,但select * from (select id, name from t) a。这个选项是防御程序通过调用select *获得数据表的结构信息。 |
selectIntoAllow | true | SELECT查询中是否允许INTO字句 |
deleteAllow | true | 是否允许执行DELETE语句 |
updateAllow | true | 是否允许执行UPDATE语句 |
insertAllow | true | 是否允许执行INSERT语句 |
replaceAllow | true | 是否允许执行REPLACE语句 |
mergeAllow | true | 是否允许执行MERGE语句,这个只在Oracle中有用 |
callAllow | true | 是否允许通过jdbc的call语法调用存储过程 |
setAllow | true | 是否允许使用SET语法 |
truncateAllow | true | truncate语句是危险,缺省打开,若需要自行关闭 |
createTableAllow | true | 是否允许创建表 |
alterTableAllow | true | 是否允许执行Alter Table语句 |
dropTableAllow | true | 是否允许修改表 |
commentAllow | false | 是否允许语句中存在注释,Oracle的用户不用担心,Wall能够识别hints和注释的区别 |
noneBaseStatementAllow | false | 是否允许非以上基本语句的其他语句,缺省关闭,通过这个选项就能够屏蔽DDL。 |
multiStatementAllow | false | 是否允许一次执行多条语句,缺省关闭 |
useAllow | true | 是否允许执行mysql的use语句,缺省打开 |
describeAllow | true | 是否允许执行mysql的describe语句,缺省打开 |
showAllow | true | 是否允许执行mysql的show语句,缺省打开 |
commitAllow | true | 是否允许执行commit操作 |
rollbackAllow | true | 是否允许执行roll back操作 |
如果把selectIntoAllow、deleteAllow、updateAllow、insertAllow、mergeAllow都设置为false,这就是一个只读数据源了。
4.4.5.3 拦截配置-永真条件
配置项 | 缺省值 | 描述 |
selectWhereAlwayTrueCheck | true | 检查SELECT语句的WHERE子句是否是一个永真条件 |
selectHavingAlwayTrueCheck | true | 检查SELECT语句的HAVING子句是否是一个永真条件 |
deleteWhereAlwayTrueCheck | true | 检查DELETE语句的WHERE子句是否是一个永真条件 |
deleteWhereNoneCheck | false | 检查DELETE语句是否无where条件,这是有风险的,但不是SQL注入类型的风险 |
updateWhereAlayTrueCheck | true | 检查UPDATE语句的WHERE子句是否是一个永真条件 |
updateWhereNoneCheck | false | 检查UPDATE语句是否无where条件,这是有风险的,但不是SQL注入类型的风险 |
conditionAndAlwayTrueAllow | false | 检查查询条件(WHERE/HAVING子句)中是否包含AND永真条件 |
conditionAndAlwayFalseAllow | false | 检查查询条件(WHERE/HAVING子句)中是否包含AND永假条件 |
conditionLikeTrueAllow | true | 检查查询条件(WHERE/HAVING子句)中是否包含LIKE永真条件 |
4.4.5.4 其他拦截配置
配置项 | 缺省值 | 描述 |
selectIntoOutfileAllow | false | SELECT ... INTO OUTFILE 是否允许,这个是mysql注入攻击的常见手段,缺省是禁止的 |
selectUnionCheck | true | 检测SELECT UNION |
selectMinusCheck | true | 检测SELECT MINUS |
selectExceptCheck | true | 检测SELECT EXCEPT |
selectIntersectCheck | true | 检测SELECT INTERSECT |
mustParameterized | false | 是否必须参数化,如果为True,则不允许类似WHERE ID = 1这种不参数化的SQL |
strictSyntaxCheck | true | 是否进行严格的语法检测,Druid SQL Parser在某些场景不能覆盖所有的SQL语法,出现解析SQL出错,可以临时把这个选项设置为false,同时把SQL反馈给Druid的开发者。 |
conditionOpXorAllow | false | 查询条件中是否允许有XOR条件。XOR不常用,很难判断永真或者永假,缺省不允许。 |
conditionOpBitwseAllow | true | 查询条件中是否允许有"&"、"~"、"|"、"^"运算符。 |
conditionDoubleConstAllow | false | 查询条件中是否允许连续两个常量运算表达式 |
minusAllow | true | 是否允许SELECT * FROM A MINUS SELECT * FROM B这样的语句 |
intersectAllow | true | 是否允许SELECT * FROM A INTERSECT SELECT * FROM B这样的语句 |
constArithmeticAllow | true | 拦截常量运算的条件,比如说WHERE FID = 3 - 1,其中"3 - 1"是常量运算表达式。 |
limitZeroAllow | false | 是否允许limit 0这样的语句 |
selectLimit | -1 | 配置最大返回行数,如果select语句没有指定最大返回行数,会自动修改selct添加返回限制 |
4.4.5.5 禁用对象检测配置
配置项 | 缺省值 | 描述 |
tableCheck | true | 检测是否使用了禁用的表 |
schemaCheck | true | 检测是否使用了禁用的Schema |
functionCheck | true | 检测是否使用了禁用的函数 |
objectCheck | true | 检测是否使用了“禁用对对象” |
variantCheck | true | 检测是否使用了“禁用的变量” |
readOnlyTables | 空 | 指定的表只读,不能够在SELECT INTO、DELETE、UPDATE、INSERT、MERGE中作为"被修改表"出现< |
4.4.5.6 JDBC相关配置
配置项 | 缺省值 | 描述 |
metadataAllow | true | 是否允许调用Connection.getMetadata方法,这个方法调用会暴露数据库的表信息 |
wrapAllow | true | 是否允许调用Connection/Statement/ResultSet的isWrapFor和unwrap方法,这两个方法调用,使得有办法拿到原生驱动的对象,绕过WallFilter的检测直接执行SQL。 |
4.4.5.7 WallFilter配置说明
配置项 | 缺省值 | 描述 |
logViolation | false | 对被认为是攻击的SQL进行LOG.error输出 |
throwException | true | 对被认为是攻击的SQL抛出SQLExcepton |
config | ||
provider |
刚开始引入WallFilter的时候,把logViolation设置为true,而throwException设置为false。就可以观察是否存在违规的情况,同时不影响业务运行。
4.5 配置WebStatFilter
WebStatFilter用于采集web-jdbc关联监控的数据。
4.5.1 web.xml配置
<filter> <filter-name>DruidWebStatFilter</filter-name> <filter-class>com.alibaba.druid.support.http.WebStatFilter</filter-class> <init-param> <param-name>exclusions</param-name> <param-value>*.js,*.gif,*.jpg,*.png,*.css,*.ico,/druid/*</param-value> </init-param> </filter> <filter-mapping> <filter-name>DruidWebStatFilter</filter-name> <url-pattern>/*</url-pattern> </filter-mapping> |
4.5.2 exclusions配置
经常需要排除一些不必要的url,比如*.js,/jslib/*等等。配置在init-param中。比如:
<init-param> <param-name>exclusions</param-name> <param-value>*.js,*.gif,*.jpg,*.png,*.css,*.ico,/druid/*</param-value> </init-param> |
4.5.3 sessionStatMaxCount配置
缺省sessionStatMaxCount是1000个。你可以按需要进行配置,比如:
<init-param> <param-name>sessionStatMaxCount</param-name> <param-value>1000</param-value> </init-param> |
4.5.4 sessionStatEnable配置
你可以关闭session统计功能,比如:
<init-param> <param-name>sessionStatEnable</param-name> <param-value>false</param-value> </init-param> |
4.5.5 principalSessionName配置
你可以配置principalSessionName,使得druid能够知道当前的session的用户是谁。比如:
<init-param> <param-name>principalSessionName</param-name> <param-value>xxx.user</param-value> </init-param> |
根据需要,把其中的xxx.user修改为你user信息保存在session中的sessionName。
注意:如果你session中保存的是非string类型的对象,需要重载toString方法。
4.5.6 principalCookieName配置
如果你的user信息保存在cookie中,你可以配置principalCookieName,使得druid知道当前的user是谁。
<init-param> <param-name>principalCookieName</param-name> <param-value>xxx.user</param-value> </init-param> |
根据需要,把其中的xxx.user修改为你user信息保存在cookie中的cookieName。
4.5.7 profileEnable配置
druid 0.2.7版本开始支持profile,配置profileEnable能够监控单个url调用的sql列表。
<init-param> <param-name>profileEnable</param-name> <param-value>true</param-value> </init-param> |
4.5.8 结果展示
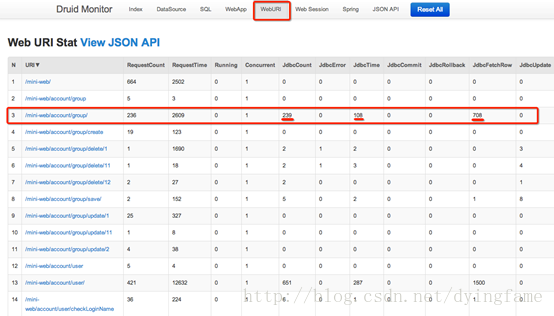
4.6 配置ConfigFilter
ConfigFilter的作用包括:
l 从配置文件中读取配置
l 从远程http文件中读取配置
l 为数据库密码提供加密功能
4.6.1 配置ConfigFilter
4.6.1.1 配置文件从本地文件系统中读取
<bean id="dataSource" class="com.alibaba.druid.pool.DruidDataSource" init-method="init" destroy-method="close"> <property name="filters" value="config" /> <property name="connectionProperties" value="config.file=file:///home/admin/druid-pool.properties" /> </bean> |
4.6.1.2 配置文件从远程http服务器中读取
<bean id="dataSource" class="com.alibaba.druid.pool.DruidDataSource" init-method="init" destroy-method="close"> <property name="filters" value="config" /> <property name="connectionProperties" value="config.file=http://127.0.0.1/druid-pool.properties" /> </bean> |
这种配置方式,使得一个应用集群中,多个实例可以从同一个地方读取配置,集中配置,集中修改,部署更简单。
4.6.1.3 通过jvm启动参数来使用ConfigFilter
DruidDataSource支持jvm启动参数配置filters,所以你可以:
java -Ddruid.filters=config .... |
4.6.2 数据库密码加密
数据库密码直接写在配置中,对运维安全来说,是一个很大的挑战。Druid为此提供一种数据库密码加密的手段ConfigFilter。
4.6.2.1 执行命令加密数据库密码
在命令行中执行如下命令:
java -cp druid-1.0.16.jar com.alibaba.druid.filter.config.ConfigTools you_password |
输出:
privateKey:MIIBVgIBADANBgkqhkiG9w0BAQEFAASCAUAwggE8AgEAAkEA6+4avFnQKP+O7bu5YnxWoOZjv3no4aFV558HTPDoXs6EGD0HP7RzzhGPOKmpLQ1BbA5viSht+aDdaxXp6SvtMQIDAQABAkAeQt4fBo4SlCTrDUcMANLDtIlax/I87oqsONOg5M2JS0jNSbZuAXDv7/YEGEtMKuIESBZh7pvVG8FV531/fyOZAiEA+POkE+QwVbUfGyeugR6IGvnt4yeOwkC3bUoATScsN98CIQDynBXC8YngDNwZ62QPX+ONpqCel6g8NO9VKC+ETaS87wIhAKRouxZL38PqfqV/WlZ5ZGd0YS9gA360IK8zbOmHEkO/AiEAsES3iuvzQNYXFL3x9Tm2GzT1fkSx9wx+12BbJcVD7AECIQCD3Tv9S+AgRhQoNcuaSDNluVrL/B/wOmJRLqaOVJLQGg== publicKey:MFwwDQYJKoZIhvcNAQEBBQADSwAwSAJBAOvuGrxZ0Cj/ju27uWJ8VqDmY7956OGhVeefB0zw6F7OhBg9Bz+0c84RjzipqS0NQWwOb4kobfmg3WsV6ekr7TECAwEAAQ== password:PNak4Yui0+2Ft6JSoKBsgNPl+A033rdLhFw+L0np1o+HDRrCo9VkCuiiXviEMYwUgpHZUFxb2FpE0YmSguuRww== |
输入你的数据库密码,输出的是加密后的结果。
4.6.2.2 配置数据源,提示Druid数据源需要对数据库密码进行解密
<bean id="dataSource" class="com.alibaba.druid.pool.DruidDataSource" init-method="init" destroy-method="close"> <property name="url" value="jdbc:derby:memory:spring-test;create=true" /> <property name="username" value="sa" /> <property name="password" value="${password}" /> <property name="filters" value="config" /> <property name="connectionProperties" value="config.decrypt=true;config.decrypt.key=${publickey}" /> </bean> |
4.6.2.3 配置参数,让ConfigFilter解密密码
有三种方式配置:
l 可以在配置文件my.properties中指定config.decrypt=true
l 也可以在DruidDataSource的ConnectionProperties中指定config.decrypt=true
l 也可以在jvm启动参数中指定-Ddruid.config.decrypt=true
5. 其他配置说明
5.1 连接泄漏监测
当程序存在缺陷时,申请的连接忘记关闭,这时候,就存在连接泄漏了。Druid提供了RemoveAbandanded相关配置,用来关闭长时间不使用的连接。
5.1.1 配置RemoveAbandanded
<bean id="dataSource" class="com.alibaba.druid.pool.DruidDataSource" destroy-method="close"> ... ... <property name="removeAbandoned" value="true" /> <!-- 打开removeAbandoned功能 --> <property name="removeAbandonedTimeout" value="1800" /> <!-- 1800秒,也就是30分钟 --> <property name="logAbandoned" value="true" /> <!-- 关闭abanded连接时输出错误日志 --> ... ... </bean> |
配置removeAbandoned对性能会有一些影响,建议怀疑存在泄漏之后再打开。在上面的配置中,如果连接超过30分钟未关闭,就会被强行回收,并且日志记录连接申请时的调用堆栈。
5.1.2 内置监控页面查看未关闭连接堆栈信息
当removeAbandoned=true之后,可以在内置监控界面datasource.html中的查看ActiveConnectionStackTrace属性的,可以看到未关闭连接的具体堆栈信息,从而方便查出哪些连接泄漏了。
5.1.3 web应用
如果你的应用配置了WebStatFilter,在内置监控页面weburi-detail.html中,查看JdbcPoolConnectionOpenCount和JdbcPoolConnectionCloseCount属性,如果不相等,就是泄漏了。

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









