









Abstract
作者研究了visual transformer在给定的网络中挖掘冗余计算的效率问题。transformers在最近的研究中在一系列cv任务上表现优异。与cnn相同,巨大的计算成本是一个严重的问题。提出了一种新的精简patchs的方法。该方法能有效降低计算成本,且不会影响性能。 在imagnet数据集上,超过45%的ViT-Ti模型的FLOP可以减少,在top-1上却只有0.2%的正确率下降了。
1.Introduction
Transformer已经被应用于cv中并取得了很好的效果。与cnn比,Trtansformer引入的偏置更少。 为了减少计算成本,提出了很多模型压缩算法,如量化算法、知识蒸馏。此外,剪枝技术通过去除一些网络中的无用组件来减少神经结构。CNN中通道剪枝(或过滤器剪枝)是一种具有代表性的做法。但似乎用在Transformer上的研究很少。
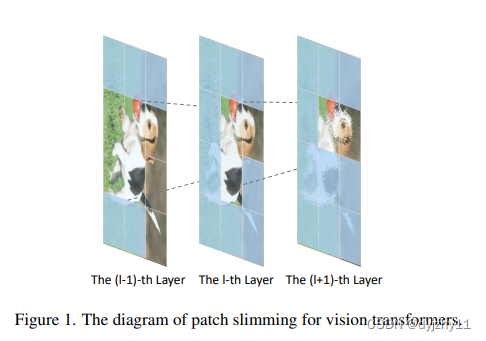
Transformer与CNN不同的是讲图像分割成多个块,并行计算块的特征。注意力机制将所有的patch嵌入到特征中作为输出。注意力图反映了任意patch间的关系和相似性。作者提到要在修剪后还能保持其特征性能,这在CNN中很难做到。此外并非所有的信息都是值得保存的。所以作者开发了一种识别能够有效识别和删除冗余patch的patch剪枝方法。
作者的重点在于寻找到冗余patch,提出了一种自顶向下的方法。具体来说,patch剪枝从最后一层执行到第一层,冗余patch会用类标记法来计算出重要性分数。patch会被较深的层保留。分数低的patch会被丢弃。所以剪枝可以保存原始的性能。
2.Related work
描述了cnn剪枝的结构,并列举了部分研究者的操作和方法。
描述transformer剪枝的结构,并列举了部分研究者的操作和方法,如:减少(MSA)模型的头、分析了transformer中每个头的作用并评估了对模型性能的影响、(MLP)模型中的神经员也被剪枝、引入了控制参数来去除小系数的神经元。作者最后提到减少patch也可以与其他与其他维度的剪枝相结合,以实现更高的加速。
3. Patch Slimming for Vision Transformer
开始介绍剪枝的方案。
回顾了transformer,并表示MSA和MLP占据了大量计算成本。
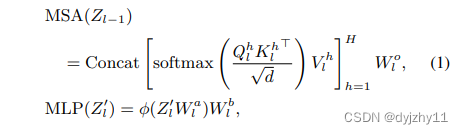
(d为嵌入的维度,h为头的数目)
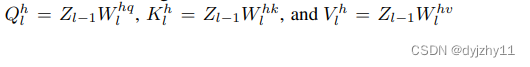
(W为线性变换的权重,![]() 为非线性激活函数)
为非线性激活函数)
大多数vision transformer都是通过交替堆叠MSA和MLP构建的。
block被定义为![]()
![]()
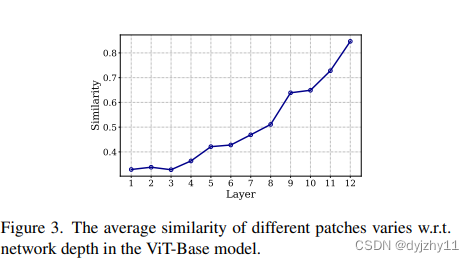
综上,transformer中存在大量的冗余信息。作者通过计算patch之间的平均余弦相似性来验证。下图为层间相似性的变化。随着层增加,相似性也随之迅速增加。高相似度意味patch为冗余的。
用了一个二进制向量![]() N表示是否保留patch,并公式化为
N表示是否保留patch,并公式化为
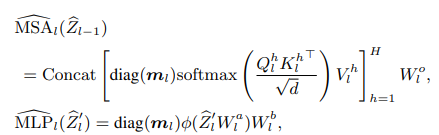
![]() 为对角矩阵,
为对角矩阵,![]() 表示第l层中的第i个补丁被剪枝。
表示第l层中的第i个补丁被剪枝。
![]() ,
,![]() 为第l层输入和中间特征。
为第l层输入和中间特征。
剪枝block定义为![]()
原来的block和现在的剪枝block相比减少了大量计算成本。作者对比了原本的方法,列举了能减少的FLOP数量。
4. Excavating Redundancy via Inverse Pruning
本节作者介绍自顶向下的框架,以及评估每个patch的重要性分数的方法。

4.1. Top-Down Pruning
选择自顶向下有两个原因。
如图二所示,CNN相邻间层通过学习权重完全连接,每个通道包含图像的完整信息 。然而在transformer中,不同的patch间通过注意力图进行交互,这反映了不同patch之间的相似性。如果patch之间更相似,则![]() 值更大。对角线元素
值更大。对角线元素![]() 起主导作用,就是说patch对其自身位置输入给予了最高关注。此外shortcut会直接将特征复制到下一层对应的patch中。这种一对一的模式让我们在不同层中相同的空间位置都能保留重要的patch。
起主导作用,就是说patch对其自身位置输入给予了最高关注。此外shortcut会直接将特征复制到下一层对应的patch中。这种一对一的模式让我们在不同层中相同的空间位置都能保留重要的patch。
transformer中更深的层往往有更多的冗余。这意味在更深的层中应安全地移除更多的冗余,而较浅的层中应安全地移除更少的冗余。
综上,先从输出层开始剪枝,然后通过选出的有效patch来剪枝前一层。特别的保存在第(l+1)的patch同样也会保存在第1层中。
剩下就是识别冗余补丁,即在每层找到![]() 。实际上,只有最后一层的一部分patch用于解决给定的任务。比如,在图像分类中,只有一个与分类相关的patch(即类标记)被用来预测标签。所以输出层中其他patch可以安全删除。假设第一个patch为类标记,则可以得到最后一层的
。实际上,只有最后一层的一部分patch用于解决给定的任务。比如,在图像分类中,只有一个与分类相关的patch(即类标记)被用来预测标签。所以输出层中其他patch可以安全删除。假设第一个patch为类标记,则可以得到最后一层的![]()
及![]() 其他层的,优化公式为:
其他层的,优化公式为:
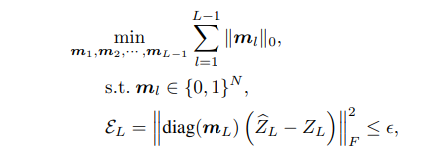

















 1974
1974

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









