




目录
一、复习前端加解密绕过方法,重点是针对有签名验证的情况如何处理
下载:https://github.com/f0ng/autoDecoder/releases/tag/0.55
二、复习bs4库的常见用法,如何通过bs4库查找网页中的特定标签
安装库:python -m pip install beautifulsoup4
三、复习httpx工具、指纹识别工具的具体用法,识别出magedu.com采用的建站模板
下载:https://github.com/projectdiscovery/httpx/releases
用法:见https://github.com/projectdiscovery/httpx
下载源码(python3版本):https://github.com/TideSec/TideFinger
安装依赖包:python -m pip install -r requirements.txt
一、复习前端加解密绕过方法,重点是针对有签名验证的情况如何处理
-
encrypt-labs靶场
-
简介
- 列出了常⻅的8种加密⽅式,包含⾮对称加密、对称加密、加签以及禁⽌重放的测试场景
- ⽐如AES、DES、RSA,⽤于渗透测试加解密练习
-
安装
- 下载源码:https://github.com/SwagXz/encrypt-labs
- 搭建网站
- 解压并使⽤phpstudy搭建⽹站,域名设置为encrypt.com
- 导⼊根⽬录下的sql⽂件
- 访问域名下的easy.php即可
- 登陆后页面截图
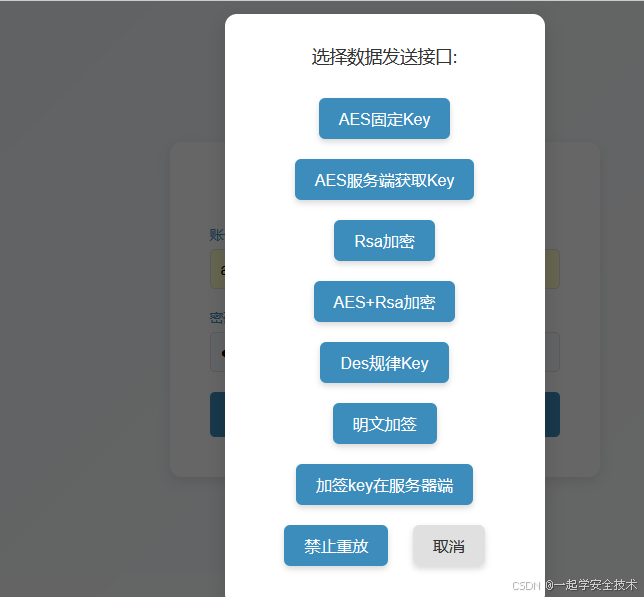
-
-
安装burp插件autoDecoder
-
加密绕过示例(逻辑:分析加密规则+让burp请求自动加密)
-
AES固定key
-
浏览器
- 访问:http://encrypt.com/easy.php
- 浏览器调试器配置(目的:看加密相关代码)
- 登陆点击此按钮
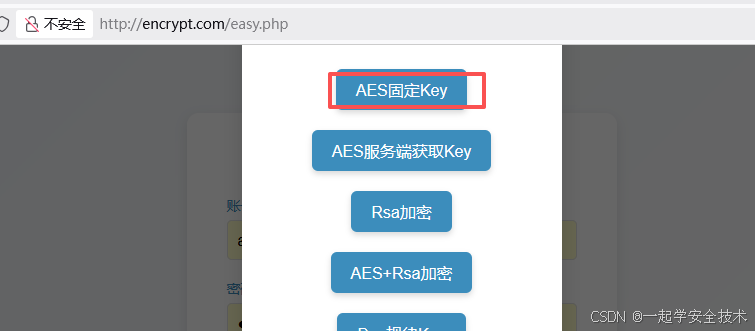
- 调试器中查看加密相关参数
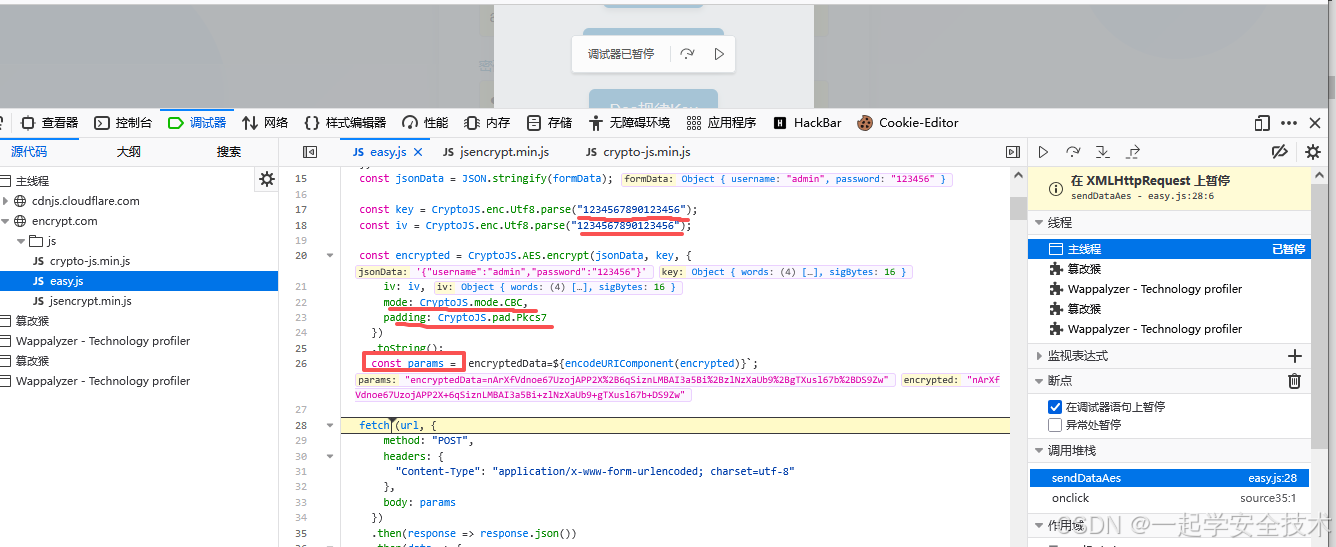
-
burp
- 跳过调试,burp抓包,查看加密后的请求参数
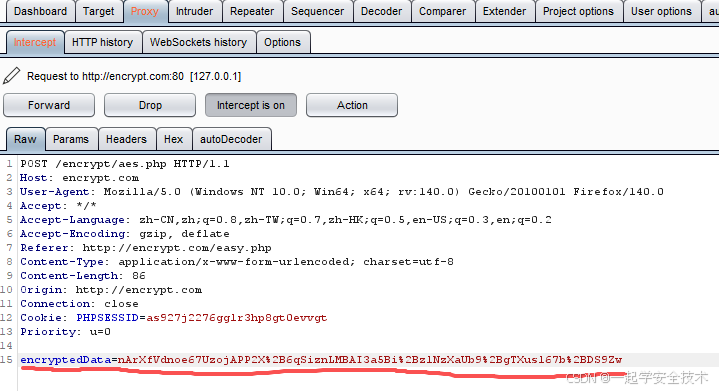
- 配置autoDecoder
- Options页
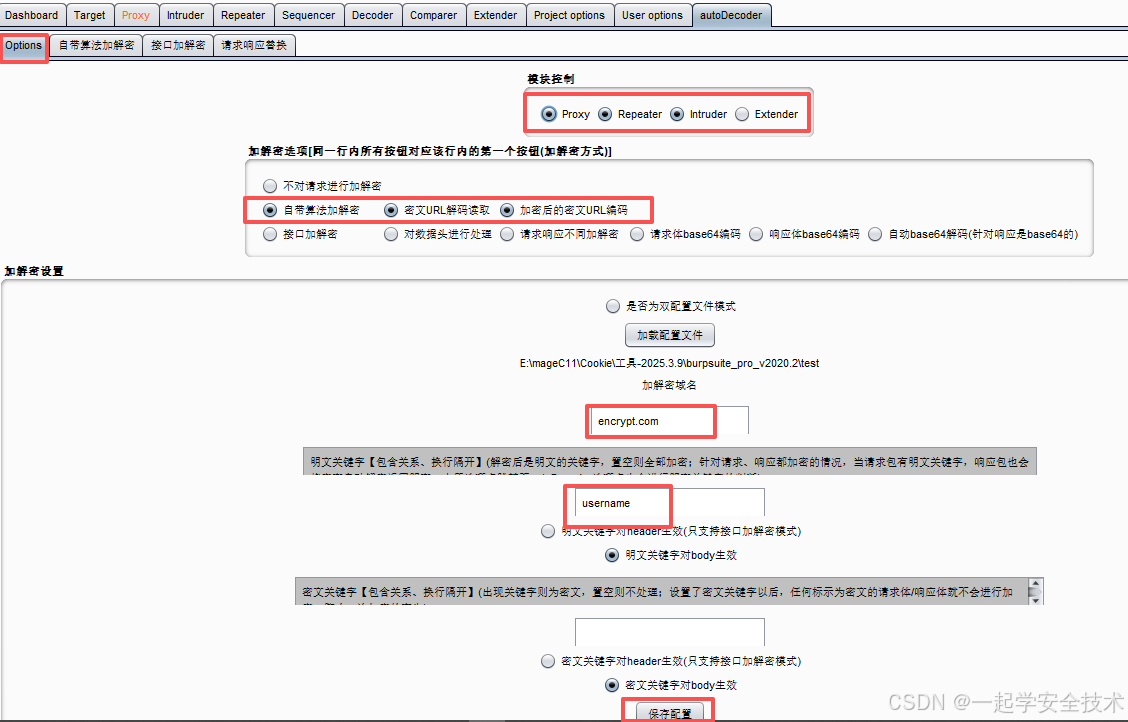
- 自带加解密算法配置页
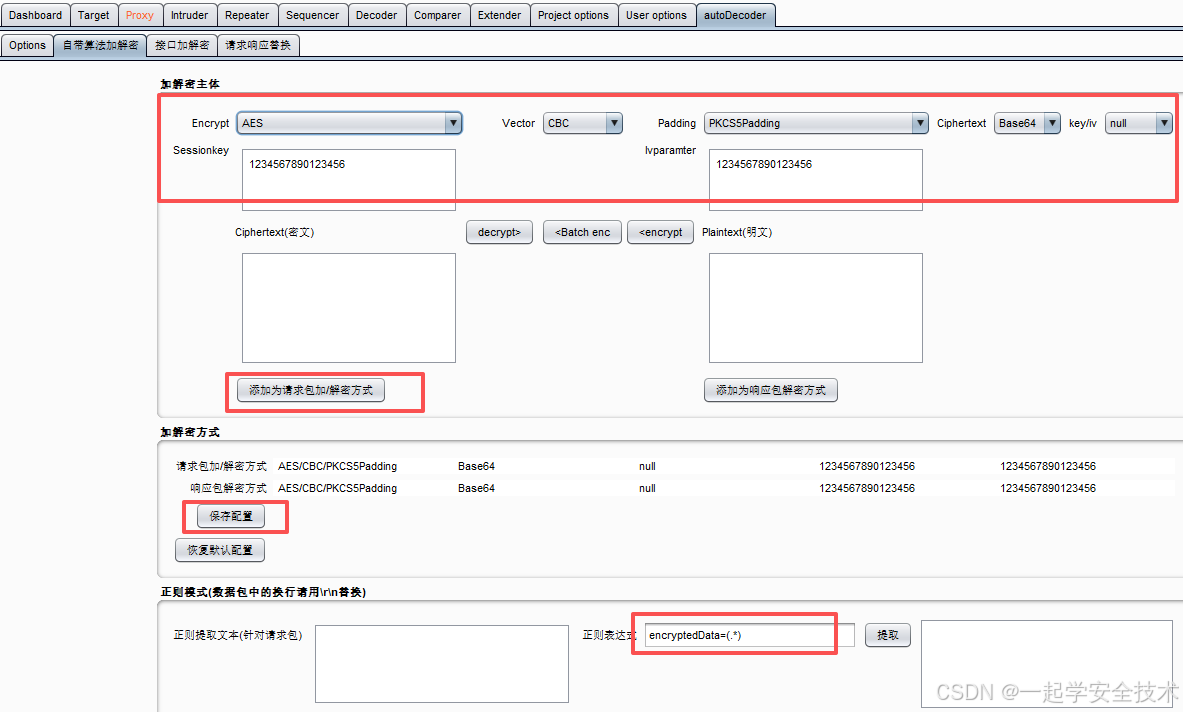
- Options页
- Repeater
- 发送请求包到Repeater
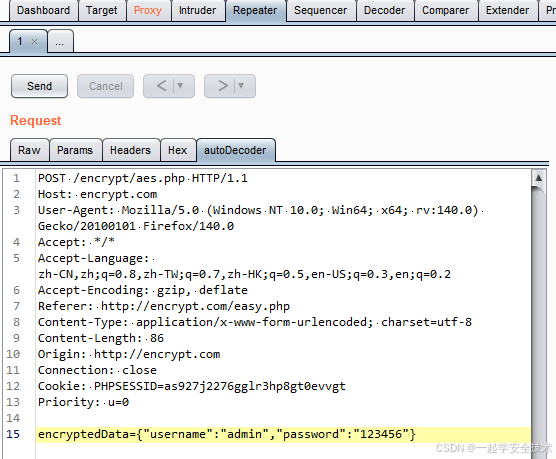
- 复制autoDecoder页代码到Raw页,发送请求,请求成功
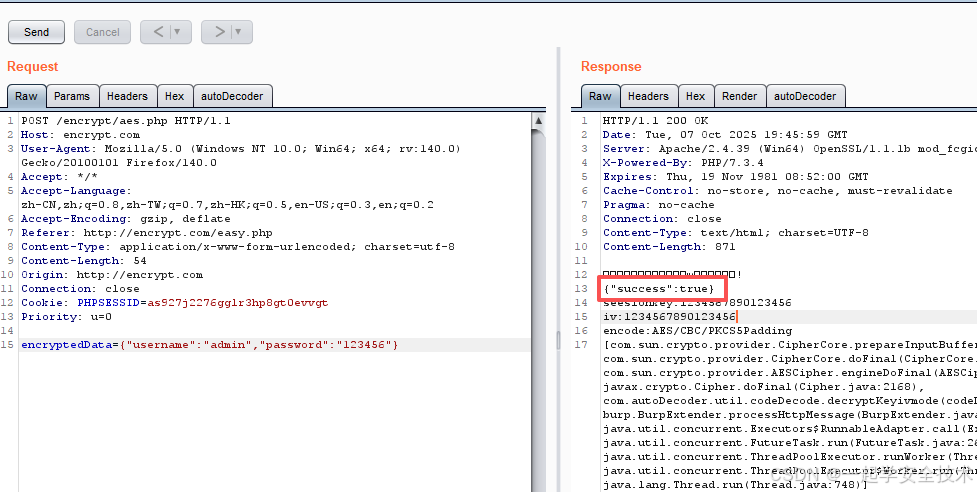
- 发送请求包到Repeater
- Intruder:在Repeater模块发包到Intruder,后续操作同Intruder的使用
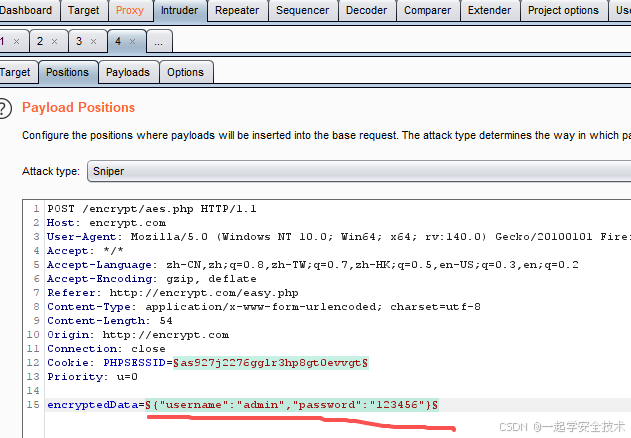
- 跳过调试,burp抓包,查看加密后的请求参数
-
-
明⽂加签(python)
-
浏览器
- 登陆后,点击此按钮
- 调试:看加密规则
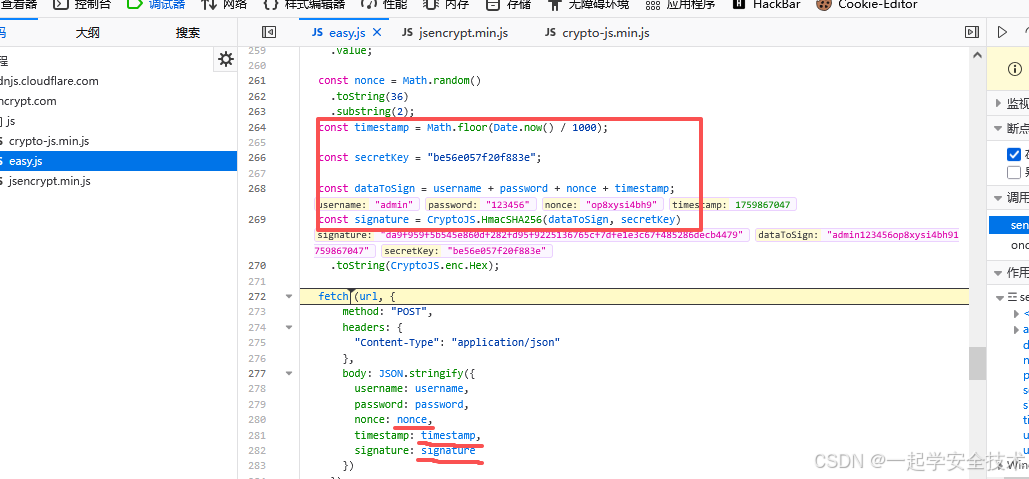
- 登陆后,点击此按钮
-
burp:抓包看请求参数
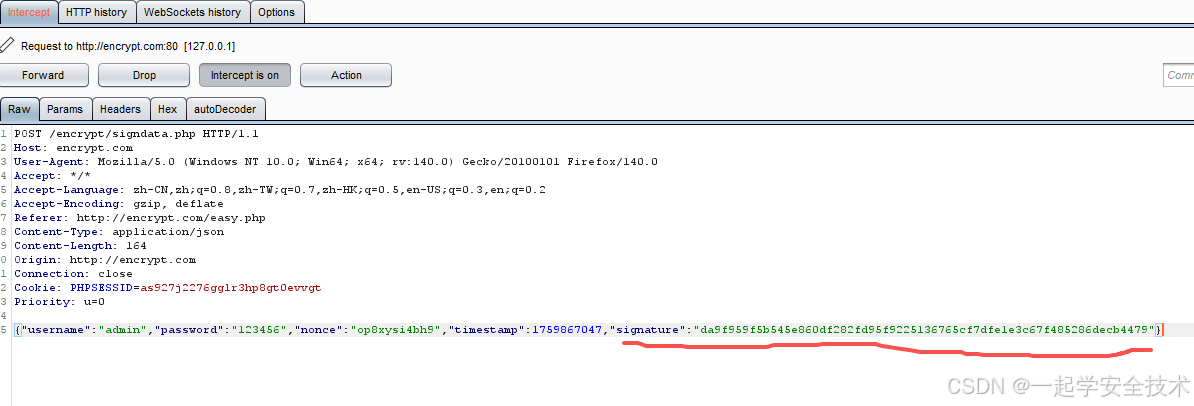
-
python
- 安装库:python -m pip install flask
- 编写同上述一致的加解密代码
from flask import Flask, request import re import hashlib import hmac app = Flask(__name__) secret_key = "be56e057f20f883e" @app.route('/encode',methods=["POST"]) # base64加密 def encrypt(): param = request.form.get('dataBody') re_name = r'"username":"(.*?)",' re_pass = r'"password":"(.*?)",' re_sign = r'"signature":"(.*?)"' re_nonce = r'"nonce":"(.*?)",' re_timestamp = r'"timestamp":(.*?),' username = re.search(re_name, param).group(1) password = re.search(re_pass, param).group(1) nonce = re.search(re_nonce, param).group(1) timestamp = re.search(re_timestamp, param).group(1) data_to_sign = f"{username}{password}{nonce}{timestamp}" print(data_to_sign) new_signature = hmac.new(secret_key.encode('utf-8'), data_to_sign.encode('utf-8'), hashlib.sha256).hexdigest() new_param = re.sub(re_sign, f'"signature":"{new_signature}"', param) return new_param @app.route('/decode',methods=["POST"]) def decrypt(): param = request.form.get('dataBody') return param if __name__ == '__main__': app.run(host="0.0.0.0",port="5000") - 运行代码,启动服务
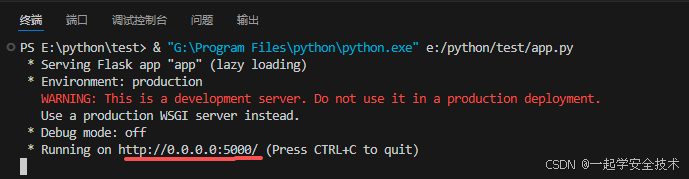
-
burp
- 配置autoDecoer
- Options页
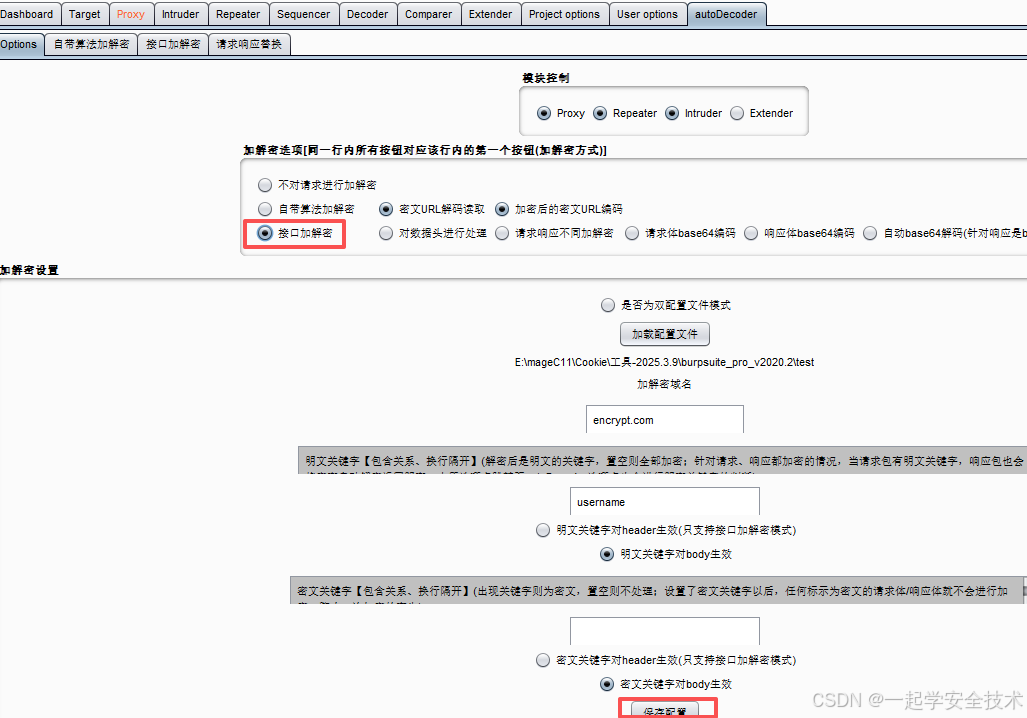
- 接口加解密页
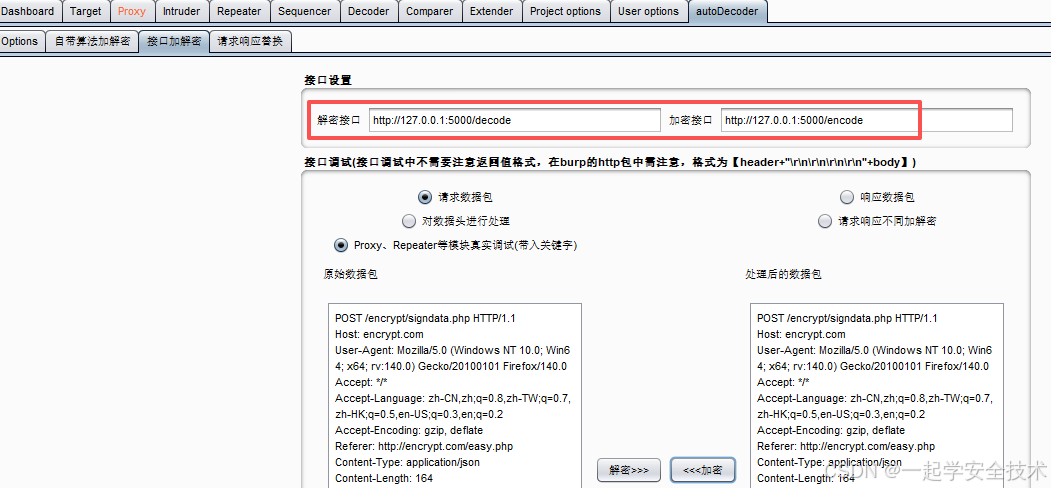
- Options页
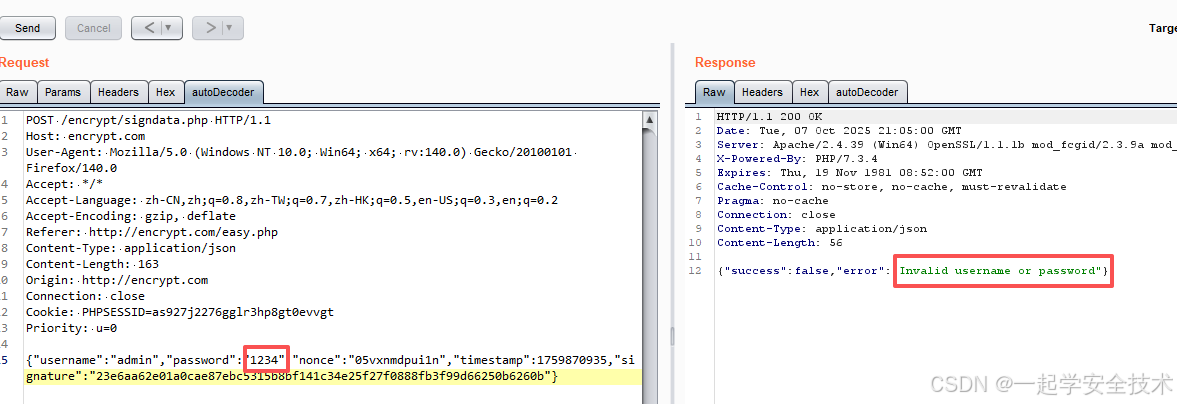
- 重新抓包(输入错误密码1234),发送到repeat测试(因为参数有时间戳,太久的包会有问题)
- 错误密码
- 正确密码
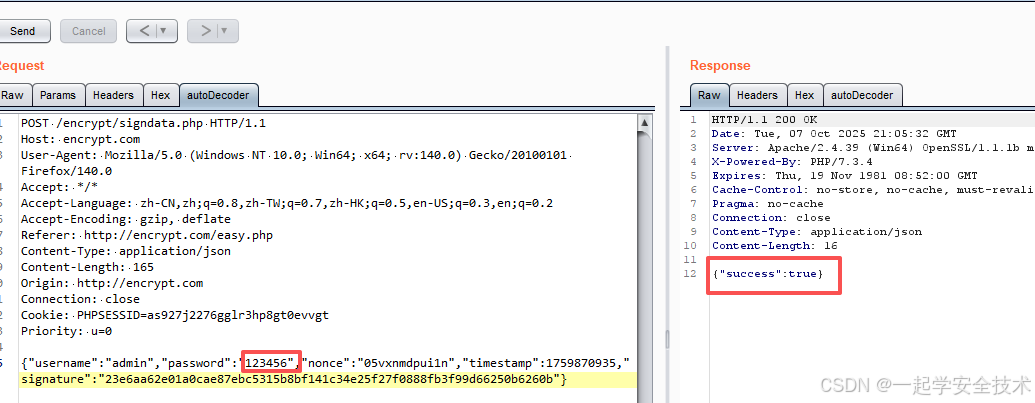
- 错误密码
- 配置autoDecoer
-
-
二、复习bs4库的常见用法,如何通过bs4库查找网页中的特定标签
-
安装库:python -m pip install beautifulsoup4
-
代码示例
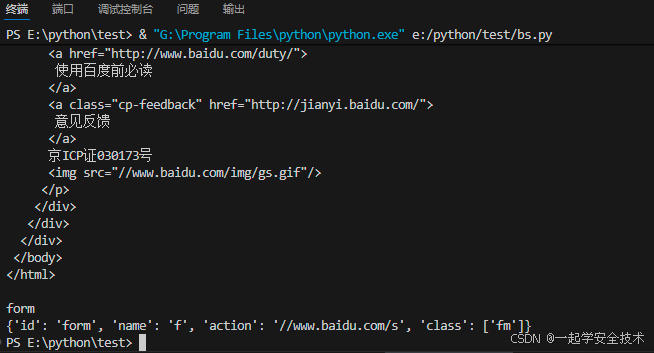
from bs4 import BeautifulSoup import requests url = "https://www.baidu.com" r1 = requests.get(url) r1.encoding='utf-8' bs_1=BeautifulSoup(r1.content,'html.parser') # 获取格式化的源码 print(bs_1.prettify()) # 1.获取tag:Tag对象与 xml 或 html 原⽣⽂档中的 tag 相同 tag = bs_1.form print(tag.name) # 获取tag名称 print(tag.attrs) # 获取tag属性 -
执行结果
三、复习httpx工具、指纹识别工具的具体用法,识别出magedu.com采用的建站模板
-
httpx
-
简介
- httpx 是⼀个快速且多⽤途的 HTTP ⼯具包
- 旨在⽀持使⽤公共库运⾏多个探针。 探测是特定的测试或检查,⽤于收集有关 Web 服务器、URL 或其他 HTTP 元素的信息
-
下载:https://github.com/projectdiscovery/httpx/releases
-
用法:见https://github.com/projectdiscovery/httpx
-
示例:对magedu.com的基本探测
httpx.exe -u https://www.magedu.com/ -title -status-code -td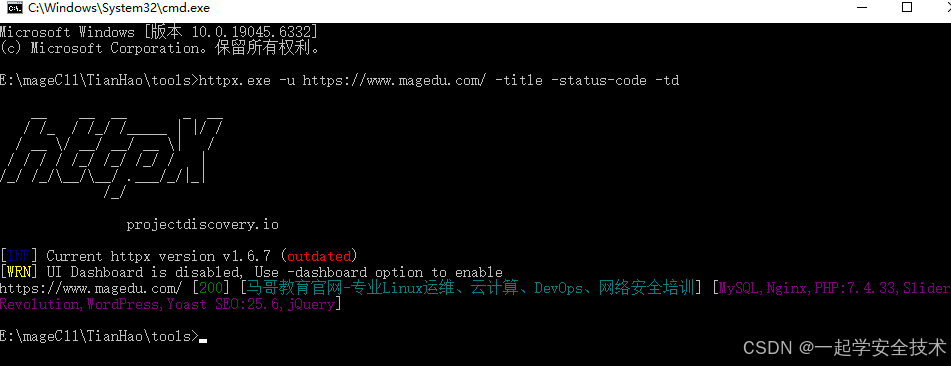
-
-
指纹识别工具TideFinger
-
简介
- ⼀个开源的指纹识别⼩⼯具
- 使⽤了传统和现代检测技术相结合的指纹检测⽅法,让指纹检测更快捷、准确
-
下载源码(python3版本):https://github.com/TideSec/TideFinger
-
使用示例:解压后,进入目录
-
安装依赖包:python -m pip install -r requirements.txt
-
使用:获取magedu.com的指纹信息
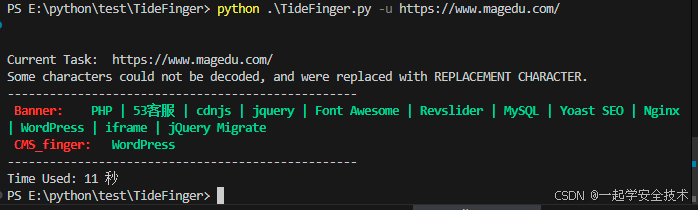
-
-
四、复习使用python调用awvs的方法及代码实现
-
awvs
-
搭建环境。见awvs搭建

-
创建apiKey
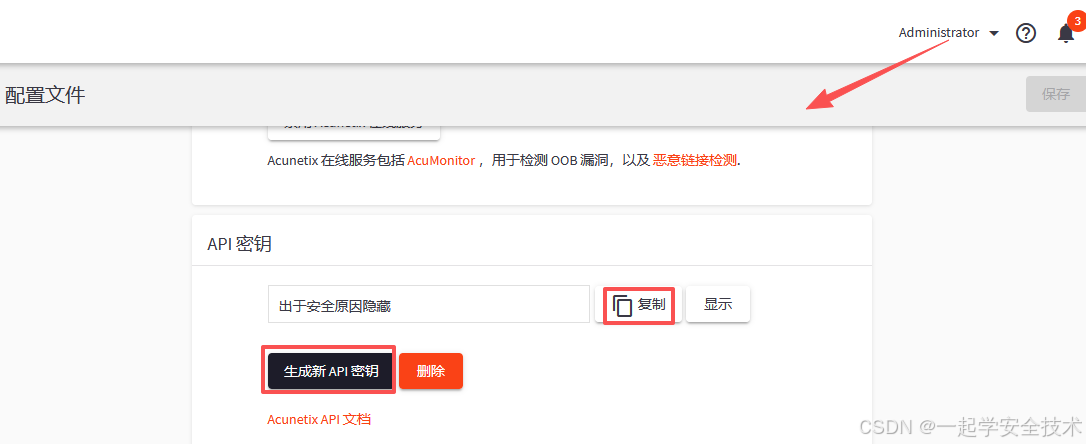
-
-
python
-
代码示例(通过api请求awvs;注意替换实际配置信息)
import requests import sys import json import time # 替换第6-8行 import urllib3 urllib3.disable_warnings(urllib3.exceptions.InsecureRequestWarning) # AWVS 默认配置信息【需替换实际信息】 api_key = "dvwa中生成的密钥" awvs_url = "dvwa的ip和端口" awvs_email = "admin@admin.com" # AWVS 扫描配置信息 scan_speed = "fast" scan_id_type = "11111111-1111-1111-1111-111111111112" scan_number = 2 proxy_address = "127.0.0.1" proxy_port = 8080 # 脚本发包配置信息 awvs_headers = { "Content-Type": "application/json; charset=utf8", "X-Auth": api_key } def get_url(starturl): if starturl.endswith("/"): url = starturl[:-1] else: url = starturl return url def check_api(aurl, aheaders, email): try: # 获取所有目标信息 checkreq = requests.get(url=get_url(aurl) + "/api/v1/me", headers=aheaders, timeout=30, verify=False) except Exception as e: print("exception:", e) if checkreq and checkreq.status_code == 200: checkme = checkreq.json() if email == checkme['email']: return True else: return False def add_tasks(aurl, aheaders, urlfile): tatgets_add_list = [] try: with open(urlfile) as all_url: for url in all_url.readlines(): if url in ['\n', '\r\n'] or url.strip() == "": pass else: if "://" in url.strip(): add_url = url.strip() else: add_url = "http://" + url.strip() add_data = {'address': add_url, 'description': 'awvsScan add', 'criticality': '10'} try: addreq = requests.post(url=get_url(aurl) + "/api/v1/targets", headers=aheaders, data=json.dumps(add_data), timeout=30, verify=False) if addreq and addreq.status_code == 201: print("已成功添加目标:", add_url) tatgets_add_list.append(addreq.json()['target_id']) except Exception as e: print(e) except OSError as reason: print("发生错误!!! 请输入正确的文件绝对路径") return tatgets_add_list def del_tasks(aurl, aheaders): try: # 获取所有目标信息 delreq = requests.get(url=get_url(aurl) + "/api/v1/targets", headers=aheaders, timeout=30, verify=False) except Exception as e: print(get_url(awvs_url) + "/api/v1/targets", e) if delreq and delreq.status_code == 200: now_targets = delreq.json() if now_targets['pagination']['count'] == 0: print("已经全部清除") else: for tid in range(now_targets['pagination']['count']): targets_id = now_targets['targets'][tid]['target_id'] try: del_target = requests.delete(url=get_url(aurl) + "/api/v1/targets/" + targets_id, headers=aheaders, timeout=30, verify=False) if del_target and del_target.status_code == 204: print("正在删除 ", now_targets['targets'][tid]['address']) except Exception as e: print(get_url(awvs_url) + "/api/v1/targets/" + targets_id, e) delreq_check_number = requests.get(url=get_url(aurl) + "/api/v1/targets", headers=aheaders, timeout=30, verify=False) check_now_targets = delreq_check_number.text if len(check_now_targets) < 200: print("已经全部清除") else: print("请稍等...") time.sleep(20) def get_all_targets_address(aurl, aheaders): all_targets = [] try: # 获取所有目标信息 setreq = requests.get(url=get_url(aurl) + "/api/v1/targets", headers=aheaders, timeout=30, verify=False) except Exception as e: print(get_url(awvs_url) + "/api/v1/targets", e) setreq_json = setreq.json() for tid in range(setreq_json['pagination']['count']): all_targets.append(setreq_json['targets'][tid]['address']) return all_targets def scan_targets(aurl, aheaders, scan_speed, scan_id_type, input_file, scan_number): tatgets_scan_list = add_tasks(aurl, aheaders, input_file) for scan_target in tatgets_scan_list: scan_speed_data = { "scan_speed": scan_speed } try: scan_speed_req = requests.patch( url=get_url(awvs_url) + "/api/v1/targets/{0}/configuration".format(scan_target), headers=awvs_headers, data=json.dumps(scan_speed_data), timeout=30, verify=False) except Exception as e: print(e) if len(tatgets_scan_list) <= scan_number: for add_scan_target in tatgets_scan_list: add_scan_target_data = { "target_id": add_scan_target, "profile_id": scan_id_type, "incremental": False, "schedule": { "disable": False, "start_date": None, "time_sensitive": False } } try: add_scan_req = requests.post(url=get_url(aurl) + "/api/v1/scans", headers=aheaders, data=json.dumps(add_scan_target_data), timeout=30, verify=False) if add_scan_req and add_scan_req.status_code == 201: get_add_scan_info_json = get_all_scan_info(aurl, aheaders, add_scan_target) print(get_add_scan_info_json['scans'][0]['profile_name'], "模式启动扫描,", "开始扫描:", get_add_scan_info_json['scans'][0]['target']['address']) except Exception as e: print(e) print("正在添加任务,请稍等...") time.sleep(3) print("正在扫描任务数为:", get_dashboard_info(aurl, aheaders)['scans_running_count']) else: flag = 0 while flag < len(tatgets_scan_list): now_scan_number = get_dashboard_info(aurl, aheaders)['scans_running_count'] print("now_scan_number", now_scan_number) if now_scan_number < scan_number: add_scan_target_data = { "target_id": tatgets_scan_list[flag], "profile_id": scan_id_type, "incremental": False, "schedule": { "disable": False, "start_date": None, "time_sensitive": False } } try: add_scan_req = requests.post(url=get_url(aurl) + "/api/v1/scans", headers=aheaders, data=json.dumps(add_scan_target_data), timeout=30, verify=False) except Exception as e: print(e) if add_scan_req and add_scan_req.status_code == 201: get_add_scan_info_json = get_all_scan_info(aurl, aheaders, tatgets_scan_list[flag]) print(get_add_scan_info_json['scans'][0]['profile_name'], "模式启动扫描,", "开始扫描:", get_add_scan_info_json['scans'][0]['target']['address']) print("正在添加任务,请稍等...") time.sleep(3) print("正在扫描任务数为:", get_dashboard_info(aurl, aheaders)['scans_running_count']) flag += 1 elif now_scan_number > scan_number + 2 and now_scan_number > 6: print("程序bug,扫描任务过多,为保护内存,现删除所有目标并退出程序") del_tasks(aurl, aheaders) sys.exit() else: time.sleep(30) while True: now_scan_number_final = get_dashboard_info(aurl, aheaders)['scans_running_count'] if now_scan_number_final == 0: print("已全部扫描完成") else: time.sleep(30) def get_dashboard_info(aurl, aheaders): get_info = requests.get(url=get_url(aurl) + "/api/v1/me/stats", headers=aheaders, timeout=30, verify=False) get_info_json = get_info.json() return get_info_json def get_all_scan_info(aurl, aheaders, targetid): try: # 获取所有目标信息 delreq = requests.get(url=get_url(aurl) + "/api/v1/scans?l=20&q=target_id:{0}".format(targetid), headers=aheaders, timeout=30, verify=False) return delreq.json() except Exception as e: print(e) def crawl_scan(aurl, aheaders, proxy_address, proxy_port, scan_speed, scan_number, input_file): crawl_scan_list = add_tasks(aurl, aheaders, input_file) for crawl_targetid in crawl_scan_list: crawl_scan_speed_data = { "scan_speed": scan_speed } crawl_config = { "user_agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) " "AppleWebKit/537.21 (KHTML, like Gecko) " "Chrome/41.0.2228.0 Safari/537.21", "limit_crawler_scope": True, "excluded_paths": [], } proxy_config = { "proxy": {"enabled": True, "protocol": "http", "address": proxy_address, "port": proxy_port } } try: # 调整速度 scan_speed_req = requests.patch( url=get_url(awvs_url) + "/api/v1/targets/{0}/configuration".format(crawl_targetid), headers=awvs_headers, data=json.dumps(crawl_scan_speed_data), timeout=30, verify=False) # 设置爬虫 crawl_config_req = requests.patch( url=get_url(awvs_url) + "/api/v1/targets/{0}/configuration".format(crawl_targetid), headers=awvs_headers, data=json.dumps(crawl_config), timeout=30, verify=False) # 设置 http 代理 http_config_req = requests.patch( url=get_url(awvs_url) + "/api/v1/targets/{0}/configuration".format(crawl_targetid), headers=awvs_headers, data=json.dumps(proxy_config), timeout=30, verify=False) except Exception as e: print(e) if len(crawl_scan_list) <= scan_number: for add_scan_target in crawl_scan_list: add_scan_target_data = { "target_id": add_scan_target, "profile_id": "11111111-1111-1111-1111-111111111117", "incremental": False, "schedule": { "disable": False, "start_date": None, "time_sensitive": False } } try: add_scan_req = requests.post(url=get_url(aurl) + "/api/v1/scans", headers=aheaders, data=json.dumps(add_scan_target_data), timeout=30, verify=False) if add_scan_req and add_scan_req.status_code == 201: time.sleep(30) get_add_scan_info_json = get_all_scan_info(aurl, aheaders, add_scan_target) print(get_add_scan_info_json['scans'][0]['profile_name'], "模式启动扫描,", "开始扫描:", get_add_scan_info_json['scans'][0]['target']['address']) except Exception as e: print(e) print("正在添加任务,请稍等...") time.sleep(3) print("正在扫描任务数为:", get_dashboard_info(aurl, aheaders)['scans_running_count']) else: flag = 0 while flag < len(crawl_scan_list): now_scan_number = get_dashboard_info(aurl, aheaders)['scans_running_count'] print("now_scan_number", now_scan_number) if now_scan_number < scan_number: add_scan_target_data = { "target_id": crawl_scan_list[flag], "profile_id": scan_id_type, "incremental": False, "schedule": { "disable": False, "start_date": None, "time_sensitive": False } } try: add_scan_req = requests.post(url=get_url(aurl) + "/api/v1/scans", headers=aheaders, data=json.dumps(add_scan_target_data), timeout=30, verify=False) except Exception as e: print(e) if add_scan_req and add_scan_req.status_code == 201: get_add_scan_info_json = get_all_scan_info(aurl, aheaders, crawl_scan_list[flag]) print(get_add_scan_info_json['scans'][0]['profile_name'], "模式启动扫描,", "开始扫描:", get_add_scan_info_json['scans'][0]['target']['address']) print("正在添加任务,请稍等...") time.sleep(3) print("正在扫描任务数为:", get_dashboard_info(aurl, aheaders)['scans_running_count']) flag += 1 elif now_scan_number > scan_number + 2 and now_scan_number > 6: print("程序bug,扫描任务过多,为保护内存,现删除所有目标并退出程序") del_tasks(aurl, aheaders) sys.exit() else: time.sleep(30) while True: now_scan_number_final = get_dashboard_info(aurl, aheaders)['scans_running_count'] if now_scan_number_final == 0: print("已全部扫描完成") else: time.sleep(30) def main(): if check_api(awvs_url, awvs_headers, awvs_email): print("AWVS API 认证成功") print(""" 1. 清空 AWVS Targets 列表所有目标 2. 列出 AWVS Targets 列表所有目标 3. 批量添加 url 至 AWVS Targets 列表,但不进行扫描 4. 批量添加 url 至 AWVS Targets 列表,并进行主动扫描(可控制同时扫描的任务数量) 5. 批量添加 url 至 AWVS Targets 列表,仅爬虫模式,联动 Xray 进行扫描(可控制同时扫描的任务数量) """) while True: try: choose = int(input("请选择运行的模式:")) break except ValueError: print("请选择数字编号作为运行的模式,如:2") if choose == 1: del_tasks(awvs_url, awvs_headers) elif choose == 2: get_address = get_all_targets_address(awvs_url, awvs_headers) if len(get_address) == 0: print("AWVS Targets 列表为空, 请先传入 target") else: for _ in get_address: print(_.strip()) elif choose == 3: input_file_a = input("请输出传入文件绝对路径:") add_tasks(awvs_url, awvs_headers, input_file_a.strip()) elif choose == 4: input_file_b = input("请输出传入文件绝对路径:") scan_targets(awvs_url, awvs_headers, scan_speed, scan_id_type, input_file_b.strip(), scan_number) elif choose == 5: input_file_c = input("请输出传入文件绝对路径:") crawl_scan(awvs_url, awvs_headers, proxy_address, proxy_port, scan_speed, scan_number, input_file_c) else: print("您的选项有误,请选择正确的选项") sys.exit() else: print("api 认证失败,请检查 api_key") sys.exit() if __name__ == '__main__': main() -
执行示例
-
运行awvs_scan.py:清空所有目标
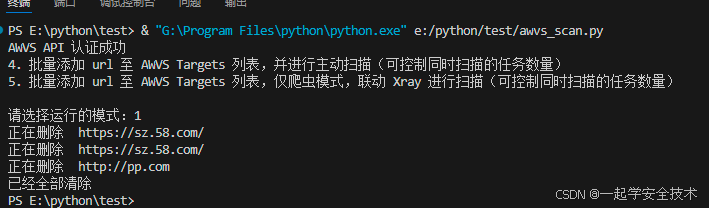
-
运行awvs_scan.py:添加url并扫描
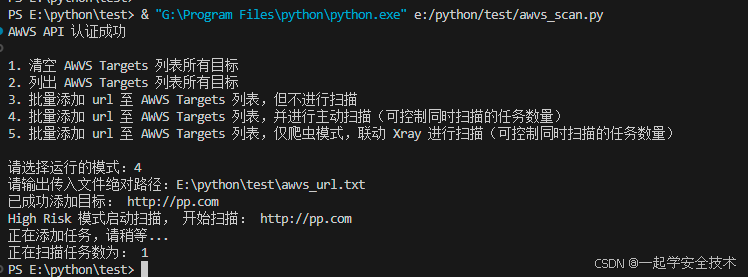



-
运行awvs_scan.py:查看所有目标

-
-
五、熟悉nuclei工具使用和模板编写
-
下载安装
-
安装nuclei
-
下载/更新模版
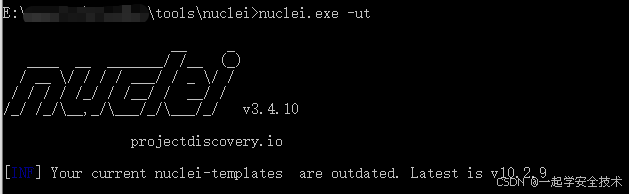
- 方式一(命令行):nuclei.exe -ut
- 方式二(适用于网络原因命令行失败的情况)
- 下载模版文件:https://github.com/projectdiscovery/nuclei-templates
- 解压后重命名为templates,放到nuclei同目录下
- 可能问题:提示模版文件过期,但能正常使用,原因未知
-
-
使用示例
-
在fofa上查找一个wordPress的站点
-
执行命令
nuclei.exe -u https://www.test.com -t http\vulnerabilities\wordpress\ -u:指定目标 -t:指定模版(可为具体模版文件或者目录)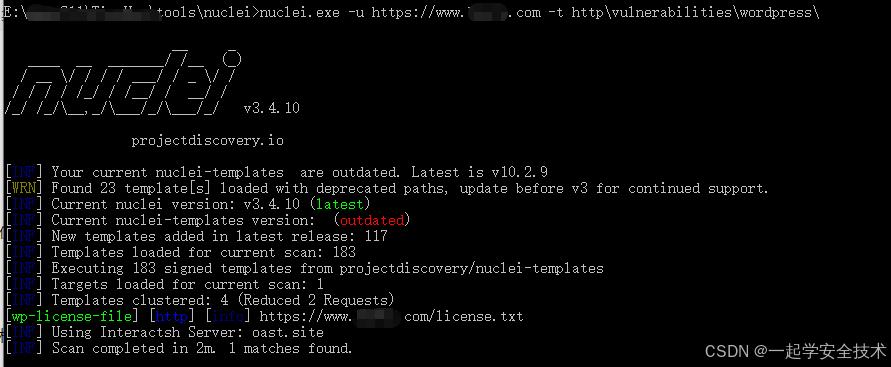
-
-
模版编写
-
Nuclei PoC 的结构主要由以下组成
- 漏洞描述(必须:主要包括漏洞名称、漏洞描述、漏洞编号、搜索语法等组成,便于直观了解漏洞基本信息。
- 变量定义(⾮必须|常⽤):定义变量
- 数据包(必须):携带 payload 的数据包
- 攻击设置(⾮必须|不常⽤):模仿burp的intruder模块
- 请求设置(⾮必须|常⽤):例如开启重定向或 cookie 维持等,仅在当前 PoC ⽣效
- 匹配器(必须):设置命中漏洞的匹配规则
- 提取器(⾮必须|常⽤):提取返回包中数据的⼯具
-
编写技巧:可参考某个模版编写,也可借助ai编写
-

















 1152
1152

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









