







 本文介绍了一种处理富文本RTF格式中中文乱码的方法,重点讲解了如何利用Java Swing组件解析RTF,并针对ISO8859-1编码未覆盖的字节进行特殊处理,确保中文字符的完整性和准确性。
本文介绍了一种处理富文本RTF格式中中文乱码的方法,重点讲解了如何利用Java Swing组件解析RTF,并针对ISO8859-1编码未覆盖的字节进行特殊处理,确保中文字符的完整性和准确性。
最近做个项目,数据库存储了别的项目获取的含有中文的富文本格式字符串,这边要求转成中文进行处理,所以研究了一下,项目实施后也遇到了几个问题,在这里分享一下,本文主要关注如何将富文本中的中文正确解析出来:
主要解决问题:
1 如何解析富文本中的中文;
2 特殊的富文本格式怎么处理;
3 解析出现中文乱码怎么应对(不是编码格式原因造成的);
问题3参考https://www.dazhuanlan.com/2019/08/16/5d55fcd632b0f/
富文本:缩写问rtf,是一种标准。会以特定的符号代表样式。通过富文本组件加载富文本时,会直接显示成相应的样式。
常见富文本格式如下:
{\rtf1\ansi\ansicpg936\deff0{\fonttbl{\f0\fnil\fcharset134 \'cb\'ce\'cc\'e5;}{\f1\fnil\fcharset134 \'ba\'da\'cc\'e5;}}
{\colortbl ;\red0\green0\blue0;}
\viewkind4\uc1\pard\cf1\lang2052\ul\f0\fs22 2020\'c4\'ea07\'d4\'c219\'c8\'d506\'ca\'b100\'b7\'d6\'d6\'c1\'c1\'ed\'d3\'d0\'c3\'fc\'c1\'ee\'ca\'b1\'a3\'ac\b\f1\'b3\'c9\'d3\'e5\'cf\'df\'c4\'da\'bd\'ad\'d5\'be\'d6\'c1\'97\'c0\'c4\'be\'d5\'f2\'d5\'be\'bc\'e4220km432m\'d6\'c1230km897m\'b4\'a6\b0\f0\'b0\'b4\'d5\'d5\'a1\'b6\'b3\'c9\'b6\'bc\'be\'d6\'bc\'af\'cd\'c5\'b9\'ab\'cb\'be\'b9\'d8\'d3\'da\'b9\'ab\'b2\'bc\'d1\'b4\'c6\'da\'b7\'c0\'ba\'e9\'cf\'de\'cb\'d9\'cf\'e0\'b9\'d8LKJ\'bb\'f9\'b4\'a1\'ca\'fd\'be\'dd\'b5\'c4\'cd\'a8\'d6\'aa\'a1\'b7\'b3\'c9\'cc\'fa\'bf\'c6\'d0\'c5\'b5\'e7\'a1\'be2020\'a1\'bf231\'ba\'c5\'ce\'c4\'bc\'fe\'d2\'aa\'c7\'f3\'a3\'ac\b\f1\'bf\'cd\'b3\'b5\'cf\'de\'cb\'d960km/h\ulnone\b0\f0\'a1\'a3\'d7\'d42020\'c4\'ea07\'d4\'c219\'c8\'d506\'ca\'b100\'b7\'d6\'c6\'f0\'c7\'b0\'b7\'a22020\'c4\'ea07\'d4\'c215\'c8\'d552089\'ba\'c5\'d4\'cb\'d0\'d0\'bd\'d2\'ca\'be\'c3\'fc\'c1\'ee\'b7\'cf\'d6\'b9\'a1\'a3
\par
\par }
方法一:手动解析
将富文本中的格式去掉,只留文本内容,然后将文本内容转成中文。该方法可以用,但是有两个问题,一个是去掉格式很繁琐,还容易漏,不易维护,另一个时方法不标准,容易因为文本格式变动出一些问题。
方法二:使用swing的富文本自建辅助解析,代码如下:
public static String parseRtf(String rtfJieshi) {
String result = "";
try {
System.out.println(rtfJieshi);
//替换特殊样式符号
//rtfJieshi = transSpecialCharactersToGBK(rtfJieshi);
//替换特殊字节
//rtfJieshi = transSpecialISO(rtfJieshi);
byte[] b = rtfJieshi .getBytes();
DefaultStyledDocument styledDoc = new DefaultStyledDocument();
new RTFEditorKit().read(new ByteArrayInputStream(b), styledDoc, 0);
byte[] data = styledDoc.getText(0,styledDoc.getLength()).getBytes("ISO8859_1");
//data = inverseSpecial(data);
//注意这边加上GBK
result = new String(data,"GBK");
} catch (Exception e) {
e.printStackTrace();
}
return result;
}
该方法使用Java swing自带组件,可以处理绝大部分情况。
中间发现部分字符,swing的富文本组件不识别,于是做了个样式符转换成GBK编码的转换器(其实就转换了四个符号,其他符号预留,转成GBK也是我这边时GBK编码才这样转):
import java.util.Dictionary;
import java.util.Hashtable;
/**
* rtf转换时,部分Special Characters无法转义成正确的gbk编码,这里在使用RTFReader解析前,先将这些Special Characters转换成相应的gkb编码
*
*/
public class ZZCTQTransKey {
static Dictionary<String, String> textKeywords = null;
static {
textKeywords = new Hashtable<String, String>();
//textKeywords.put("\\", "\\");
//textKeywords.put("{", "{");
//textKeywords.put("}", "}");
//textKeywords.put(" ", "\u00A0"); /* not in the spec... */
//textKeywords.put("~", "\u00A0"); /* nonbreaking space */
//textKeywords.put("_", "\u2011"); /* nonbreaking hyphen */
//textKeywords.put("bullet", "\u2022");
//textKeywords.put("emdash", "\u2014");
//textKeywords.put("emspace", "\u2003");
//textKeywords.put("endash", "\u2013");
//textKeywords.put("enspace", "\u2002");
textKeywords.put("\\\\ldblquote", "\\\\'a1\\\\'b0");//
textKeywords.put("\\\\lquote", "\\\\'a1\\\\'ae");//
//textKeywords.put("ltrmark", "\u200E");
textKeywords.put("\\\\rdblquote", "\\\\'a1\\\\'b1");//
textKeywords.put("\\\\rquote", "\\\\'a1\\\\'af");//
//textKeywords.put("rtlmark", "\u200F");
//textKeywords.put("tab", "\u0009");
//textKeywords.put("zwj", "\u200D");
//textKeywords.put("zwnj", "\u200C");
/* There is no Unicode equivalent to an optional hyphen, as far as
I can tell. */
//textKeywords.put("-", "\u2027");
}
}后面使用时,又遇到了乱码,大部分文本是正确的,有时候会是乱码,仔细研究发现,在转成中文之前,byte[]数组的内容,跟开头少了字节。后来发现,是ISO5589-1的原因,ISO5589-1有部分区域是没有编码的,遇到这一部分字节是,会丢弃掉:
https://de.wikipedia.org/wiki/ISO_8859-1,它的编码区域如下图:
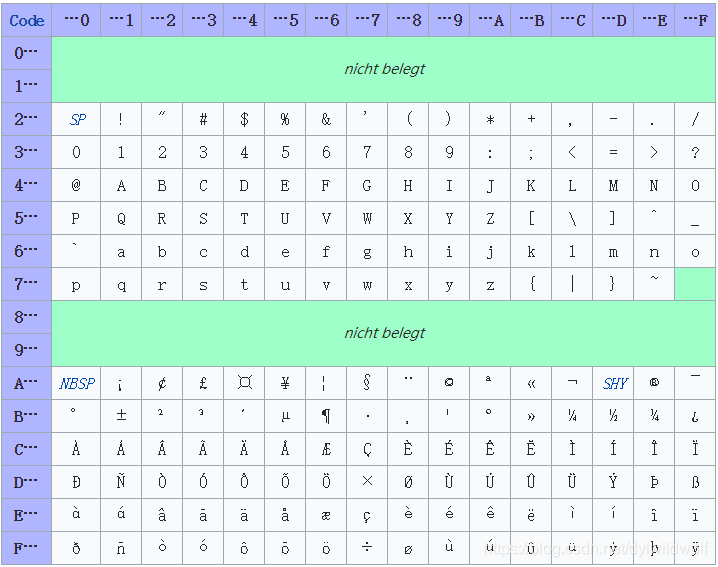
可以看到,在00-1F 7F-9F这两个区域,它都没有对应的字符,遇到这些字节时,ISO8859-1会将他们丢弃。我的情况是遇到了椑木镇三个字,问题出在椑字上,他的GBK编码是97C0,第一个字节97刚好落在了上面的空白区域,于是转出来以后,椑就只剩下C0了,然后C0又被自动和后面一个字节结合,就出现了一串乱码或者生僻字杂文。
解决办法:遇到00-1F和7F-9F的字节时,进行手工替换,替换成ISO8859-1能够识别的字节,然后在转回中文之前,换回来。
我的具体办法:遇到01的话,我会将01往下移动三行(这个自己定,我看编码图时,觉得下移三行好用),将01变成31,然后将31前面加上fbfcfdfeff的前缀,成为fbfcfdfeff31(这个纯属个人思路,不喜欢可以喷)。转换之后,通过swing组件将内容解析,只剩下文本内容。这时候,fbfcfdfeff31的每个字节都能被ISO8859-1识别出来,会保留下来,将它转回01,就保证了字节的完整性。最后转成中文即可。
全部代码如下:
import javax.swing.text.DefaultStyledDocument;
import javax.swing.text.rtf.RTFEditorKit;
import java.io.ByteArrayInputStream;
import java.util.Enumeration;
public class RtfToZh {
public static String parseRtf(String rtfJieshi) {
String result = "";
try {
System.out.println(rtfJieshi);
//替换特殊样式符号
//rtfJieshi = transSpecialCharactersToGBK(rtfJieshi);
//替换特殊字节
//rtfJieshi = transSpecialISO(rtfJieshi);
byte[] b = rtfJieshi .getBytes();
DefaultStyledDocument styledDoc = new DefaultStyledDocument();
new RTFEditorKit().read(new ByteArrayInputStream(b), styledDoc, 0);
byte[] data = styledDoc.getText(0,styledDoc.getLength()).getBytes("ISO8859_1");
//data = inverseSpecial(data);
//注意这边加上GBK
result = new String(data,"GBK");
} catch (Exception e) {
e.printStackTrace();
}
return result;
}
/**
* 将Special Characters转换成gbk编码
* @return
*/
private static String transSpecialCharactersToGBK(String rtfStr) {
if (rtfStr != null && rtfStr.length() > 0) {
for(Enumeration e = TransKey.textKeywords.keys(); e.hasMoreElements();){
String thisName=e.nextElement().toString();
String thisValue= TransKey.textKeywords.get(thisName);
rtfStr = rtfStr.replaceAll(thisName, thisValue);
}
return rtfStr;
} else {
return "";
}
}
/**
* 将ISO8859-1没有定义的字节进行转义
* @return
*/
private static String transSpecialISO(String rtfStr) {
return ISO8859ISpecialByte.conversionStr(rtfStr);
}
/**
* 将ISO8859-1没有定义的字节进行反转义
* @return
*/
private static byte[] inverseSpecial(byte[] data) {
return ISO8859ISpecialByte.inverseStr(data);
}
public static void main(String[] args) throws Exception{
String rtfStr = "{\\rtf1\\ansi\\ansicpg936\\deff0{\\fonttbl{\\f0\\fnil\\fcharset134 \\'cb\\'ce\\'cc\\'e5;}{\\f1\\fnil\\fcharset134 \\'ba\\'da\\'cc\\'e5;}}\n" +
"{\\colortbl ;\\red0\\green0\\blue0;}\n" +
"\\viewkind4\\uc1\\pard\\cf1\\lang2052\\ul\\f0\\fs22 2020\\'c4\\'ea07\\'d4\\'c219\\'c8\\'d506\\'ca\\'b100\\'b7\\'d6\\'d6\\'c1\\'c1\\'ed\\'d3\\'d0\\'c3\\'fc\\'c1\\'ee\\'ca\\'b1\\'a3\\'ac\\b\\f1\\'b3\\'c9\\'d3\\'e5\\'cf\\'df\\'c4\\'da\\'bd\\'ad\\'d5\\'be\\'d6\\'c1\\'97\\'c0\\'c4\\'be\\'d5\\'f2\\'d5\\'be\\'bc\\'e4220km432m\\'d6\\'c1230km897m\\'b4\\'a6\\b0\\f0\\'b0\\'b4\\'d5\\'d5\\'a1\\'b6\\'b3\\'c9\\'b6\\'bc\\'be\\'d6\\'bc\\'af\\'cd\\'c5\\'b9\\'ab\\'cb\\'be\\'b9\\'d8\\'d3\\'da\\'b9\\'ab\\'b2\\'bc\\'d1\\'b4\\'c6\\'da\\'b7\\'c0\\'ba\\'e9\\'cf\\'de\\'cb\\'d9\\'cf\\'e0\\'b9\\'d8LKJ\\'bb\\'f9\\'b4\\'a1\\'ca\\'fd\\'be\\'dd\\'b5\\'c4\\'cd\\'a8\\'d6\\'aa\\'a1\\'b7\\'b3\\'c9\\'cc\\'fa\\'bf\\'c6\\'d0\\'c5\\'b5\\'e7\\'a1\\'be2020\\'a1\\'bf231\\'ba\\'c5\\'ce\\'c4\\'bc\\'fe\\'d2\\'aa\\'c7\\'f3\\'a3\\'ac\\b\\f1\\'bf\\'cd\\'b3\\'b5\\'cf\\'de\\'cb\\'d960km/h\\ulnone\\b0\\f0\\'a1\\'a3\\'d7\\'d42020\\'c4\\'ea07\\'d4\\'c219\\'c8\\'d506\\'ca\\'b100\\'b7\\'d6\\'c6\\'f0\\'c7\\'b0\\'b7\\'a22020\\'c4\\'ea07\\'d4\\'c215\\'c8\\'d552089\\'ba\\'c5\\'d4\\'cb\\'d0\\'d0\\'bd\\'d2\\'ca\\'be\\'c3\\'fc\\'c1\\'ee\\'b7\\'cf\\'d6\\'b9\\'a1\\'a3\n" +
"\\par \n" +
"\\par }";
System.out.println(parseRtf(rtfStr));
}
}
import java.util.ArrayList;
import java.util.List;
/**
* 在将富文本指令解析成中文时,借助了ISO8859-1编码格式,该编码格式是单字节编码格式,不会丢失字节。
* 后来发现该编码没有对00-FF全覆盖,部分字节没有定义,这就导致转成ISO8859-1之后,部分字节会丢失。
*
* 本类处理该问题,在遇到这种字节时,转成特定的内容,然后在转中文之前,再转回来。
* 具体处理办法:
* 1 根据ISO8859-1字符集确定特殊字符范围:00-1F,7F-9F,一共65个。
* 2 遇到这些字节时,先添加前缀,然后将字节+24,形成”前缀+转移后字节“的形式比如,遇到0x01,就转成前缀+0x31。
* (这个方法一方面为了规范,另一方面,根据ISO8859-1标准,加24之后,刚好等于下移三行,不超FF,也能落到有效字节范围内)
* 3 转换成中文之前,将”前缀+转移后字节“恢复成原字节。
*/
public class ISO8859ISpecialByte {
//特殊字符,来自ISO8859-1字符集
private static String[] specialByteStrsA = {
"00", "01", "02", "03", "04", "05", "06", "07", "08", "09", "0a", "0b", "0c", "0d", "0e", "0f",
"10", "11", "12", "13", "14", "15", "16", "17", "18", "19", "1a", "1b", "1c", "1d", "1e", "1f",
"7f",
"80", "81", "82", "83", "84", "85", "86", "87", "88", "89", "8a", "8b", "8c", "8d", "8e", "8f",
"90", "91", "92", "93", "94", "95", "96", "97", "98", "99", "9a", "9b", "9c", "9d", "9e", "9f"
};
//字节转换之后的内容,这个在ISO8859-1中都有定义
private static String[] specialByteStrsB = {
"30", "31", "32", "33", "34", "35", "36", "37", "38", "39", "3a", "3b", "3c", "3d", "3e", "3f",
"40", "41", "42", "43", "44", "45", "46", "47", "48", "49", "4a", "4b", "4c", "4d", "4e", "4f",
"af",
"b0", "b1", "b2", "b3", "b4", "b5", "b6", "b7", "b8", "b9", "ba", "bb", "bc", "bd", "be", "bf",
"c0", "c1", "c2", "c3", "c4", "c5", "c6", "c7", "c8", "c9", "ca", "cb", "cc", "cd", "ce", "cf"
};
//字节前缀,来自rtf标准格式
private static String sep = "\\\\'";
//转成iso8859-1之前,添加前缀,搞复杂一些避免后面去除前缀时,误去除
private static String conversionSuxBeforeToISO = sep + "fb" + sep + "fc" + sep + "fd" + sep + "fe" + sep + "ff";
//byte内容的前缀,和 conversionSuxBeforeToISO 保持一致
private static byte[] inverseSuxBeforeToZh = {(byte) 0xfb, (byte) 0xfc, (byte) 0xfd, (byte) 0xfe, (byte) 0xff};
/**
*
* @param rtfStr rtf标准字符串
* @return 转移后字符串,已经转义了iso8859-1未定义的字节
*/
public static String conversionStr(String rtfStr) {
if (rtfStr == null) {
return null;
}
for (int i = 0; i < specialByteStrsA.length; i++) {
String a = sep + specialByteStrsA[i];
String b = conversionSuxBeforeToISO + sep + specialByteStrsB[i];
rtfStr = rtfStr.replaceAll(a, b);
}
return rtfStr;
}
/**
*
* @param data
* @return
*/
public static byte[] inverseStr(byte[] data) {
if (data == null || data.length <= inverseSuxBeforeToZh.length) {
return data;
}
List<Byte> result = new ArrayList<Byte>();
int i = 0;
boolean flag = true;
while (flag) {
if (i > data.length - 1 - inverseSuxBeforeToZh.length) {
break;
}
if (data[i] == inverseSuxBeforeToZh[0]) {
//开始匹配conversionStr转义之后的内容
boolean find = true;
for (int j = 1; j < inverseSuxBeforeToZh.length - 1; j++) {
if (data[i + j] != inverseSuxBeforeToZh[j]) {
find = false;
break;
}
}
if (find) {
boolean match = false;
//匹配成功,准备恢复字节
for (int j = 0; j < specialByteStrsA.length; j++) {
if (specialByteStrsB[j].equalsIgnoreCase(byteToHexStr(data[i + inverseSuxBeforeToZh.length]))) {
int val = Integer.valueOf(specialByteStrsA[j], 16);
result.add((byte) val);
match = true;
break;
}
}
if (match) {
i++;
i = i + inverseSuxBeforeToZh.length;
} else {
//匹配上了前缀,但是最后的字节不满足要求,按照没匹配上继续
result.add(data[i]);
i++;
}
} else {
result.add(data[i]);
i++;
}
} else {
result.add(data[i]);
i++;
}
}
//处理最后几个字节
if (data[data.length - 1 - inverseSuxBeforeToZh.length] != inverseSuxBeforeToZh[0]) {
for (int j = inverseSuxBeforeToZh.length; j >= 1 ; j--) {
result.add(data[data.length - j]);
}
}
if (result == null || result.size() == 0) {
return new byte[]{};
} else {
byte[] resultBytes = new byte[result.size()];
for (int j = 0; j < result.size(); j++) {
resultBytes[j] = result.get(j);
}
return resultBytes;
}
}
public static String byteToHexStr(byte c) {
int byteValue = c & 0XFF;
if (c == 0) {
return "00";
} else if (c < 16 && c > 0) {
return "0" + Integer.toHexString(byteValue);
}
return Integer.toHexString(byteValue);
};
}
import java.util.Dictionary;
import java.util.Hashtable;
/**
* rtf转换时,部分Special Characters无法转义成正确的gbk编码,这里在使用RTFReader解析前,先将这些Special Characters转换成相应的gkb编码
*
*/
public class TransKey {
static Dictionary<String, String> textKeywords = null;
static {
textKeywords = new Hashtable<String, String>();
//textKeywords.put("\\", "\\");
//textKeywords.put("{", "{");
//textKeywords.put("}", "}");
//textKeywords.put(" ", "\u00A0"); /* not in the spec... */
//textKeywords.put("~", "\u00A0"); /* nonbreaking space */
//textKeywords.put("_", "\u2011"); /* nonbreaking hyphen */
//textKeywords.put("bullet", "\u2022");
//textKeywords.put("emdash", "\u2014");
//textKeywords.put("emspace", "\u2003");
//textKeywords.put("endash", "\u2013");
//textKeywords.put("enspace", "\u2002");
textKeywords.put("\\\\ldblquote", "\\\\'a1\\\\'b0");//
textKeywords.put("\\\\lquote", "\\\\'a1\\\\'ae");//
//textKeywords.put("ltrmark", "\u200E");
textKeywords.put("\\\\rdblquote", "\\\\'a1\\\\'b1");//
textKeywords.put("\\\\rquote", "\\\\'a1\\\\'af");//
//textKeywords.put("rtlmark", "\u200F");
//textKeywords.put("tab", "\u0009");
//textKeywords.put("zwj", "\u200D");
//textKeywords.put("zwnj", "\u200C");
/* There is no Unicode equivalent to an optional hyphen, as far as
I can tell. */
//textKeywords.put("-", "\u2027");
}
}

















 661
661

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









