







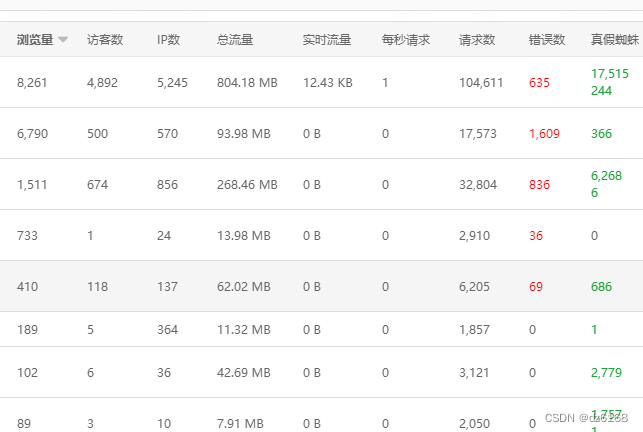
宝塔会员的 网站统计里面看蜘蛛数量 不方便
当站点多的时候不方便,,蜘蛛多少那列不能排序,不能按多少排序
写了个代码 半自动统计 蜘蛛数量
当站点多的时候,只更新诱蜘蛛来的站点,没有蜘蛛的站点不显示!
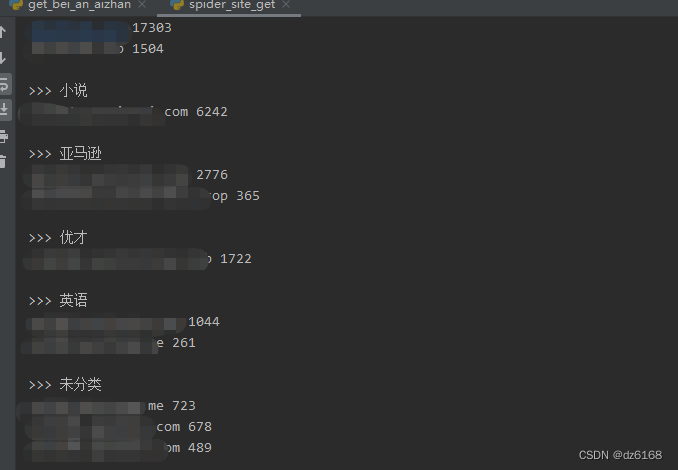
总共三个文件:
1)spider_file.txt 统计的的txt文本文件,直接全选复制页面的文本 ,放到txt ,
2) fenlei.txt 文件,用于配置如果你的服务器的网站有各种类型的站点要分类的时候,当然不分类也可以用
3)spider_site_get.py 文本处理与分类 提取脚本,主要就是处理和现实
使用方法
1)将三个文件放到一个文件夹
2)装好引用
3)配置好站点分类,不配置也可以,配置格式是,井号加分类名字,下面一行一个站点域名
#分类一
站点1
站点2
站点3
站点4
#分类2
站点5
站点6
站点7
spider_site_get.py
↓
import os
import re
def get_spider_site(site_str_list):
"""
:param site_str_list: 要处理的包含的站点
:return: 返回一个 元组list
"""
site_line_temp = []
for site_str in site_str_list:
if len(site_str) < 8:
pass
else:
site_str = site_str.strip()
site_str = re.sub(r" .* ", "**", site_str)
site_spider_num = site_str.split("**")
site_spider_num[1] = site_spider_num[1].replace(",", "")
site_line_temp.append(site_spider_num)
site_line_temp = sorted(site_line_temp, key=lambda x: int(x[1]), reverse=True)
# print(site_line_temp)
return site_line_temp
def get_file_read(filepath):
"""
:param filepath: 读取文件路径
:return: 读取的文本内容,去除换行符,返回行list
"""
if os.path.exists(filepath):
pass
else:
with open(filepath, "a+", encoding="utf-8") as fw:
fw.write("")
with open 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 555
555











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









