






 本文介绍了如何在生产环境中,利用程序摄像头Trace Profiling工具,以1-5-10分钟的时效性标准快速定位和解决CPU飙高问题。通过模拟大对象序列化场景,展示了从找关键Trace、查Span信息到分析线程事件的标准化排障步骤,强调了Trace Profiling在精准还原执行现场、降低排障门槛方面的作用。
本文介绍了如何在生产环境中,利用程序摄像头Trace Profiling工具,以1-5-10分钟的时效性标准快速定位和解决CPU飙高问题。通过模拟大对象序列化场景,展示了从找关键Trace、查Span信息到分析线程事件的标准化排障步骤,强调了Trace Profiling在精准还原执行现场、降低排障门槛方面的作用。
“ 1分钟发现-5分钟响应-10分钟恢复,是定义故障处理的时效性目标。在阿里巴巴内部经过多年的实践,这也早已成为各个业务稳定性、基础设施稳定性以及大促保障的重要牵引指标。对于故障,最难的往往不是排查解决,而是保证上述1-5-10时效性。程序摄像头Trace Profiling直击排障痛点,期望帮助用户在分钟级以标准化步骤定位全资源种类的故障根因。”
1. 常规排障痛点
当生产环境CPU使用率过高时,我们的常规思路是,登录上机器:
-
排查占用CPU的进程
-
找出实际占用最高CPU的线程
-
用jstack获取对应线程的堆栈信息,找出耗CPU的代码位置对应修复
此举易行,但是这一套操作下来,很花时间,而且如果CPU一会高,一会正常该怎么排查?比如:对象序列化、反序列化是开发的超高频操作,但是很多小伙伴可能不知道,这是很费CPU的。尤其在对象很大的时候,在生产环境就容易引起CPU飙高,但持续时间又很短,难以捕捉的情况,这种无法稳定复现的该怎么排查?
2.案例说明
我们模拟了上述场景,对一个6M大小的对象用不同的序列化框架进行序列化操作,并捕捉了请求Trace,耗时如下:
-
Fastjson:285.00ms
-
Jackson:255.29ms
-
Gson :283.08ms
-
net.sf.json:655.06ms
我们来看下程序摄像头是如何通过标准化排障步骤,实现10分钟内快速排查这个因大对象序列化导致Trace异常耗时问题的:
3. 程序摄像头Trace Profiling标准化步骤排障
3.1 找关键Trace
通过Trace系统,结合时间点,找出相关可能存在问题的关键Trace,并在程序摄像头系统上找到需要排查的Trace的profile记录。

3.2 查Span信息
选择好profile之后,本页面会展示该Trace的span执行消耗分析,如下图。但是我们只能看到Span耗时很长,但不知道时间消耗在哪里。

3.3 分析Trace执行线程事件
点击Span展开,查看对应的详细信息,通过线程事件详情来分析CPU异常原因。
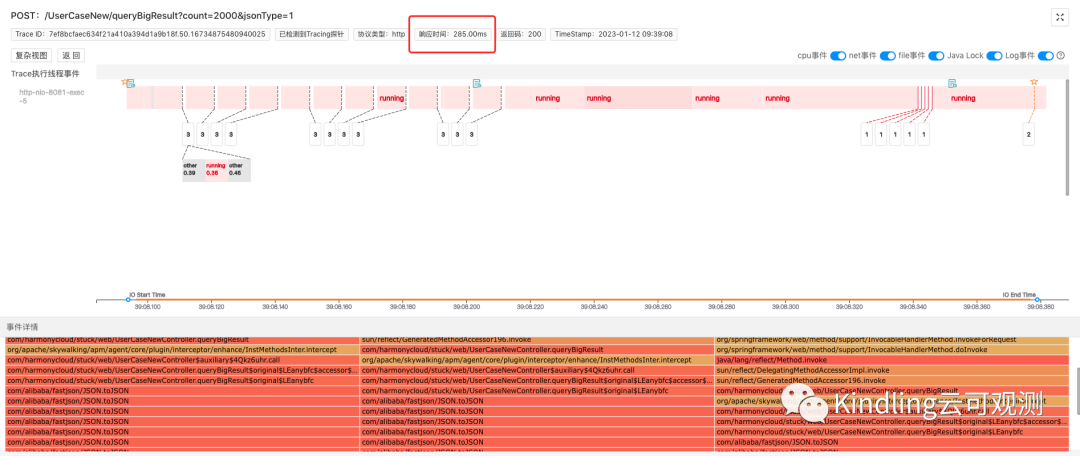
我们可以看到,本次Trace的执行主线程花了大部分时间在做running(即cpu逻辑计算)事件,点击running事件,可查看堆栈信息。堆栈显示,这是系统在执行JSON.toJSON操作,从这里我们可以推断出,本次Trace是因为执行了大对象的序列化操作,导致CPU耗时异常。
4. 精准还原执行现场,10分钟黄金时间排障
CPU问题的关键是找到问题代码堆栈,我们普遍的排查方式是“事后诸葛”:出现问题了,再去打堆栈,费时不说,有些难复现的会比较棘手。而程序摄像头Trace Profiling像监控一样,在系统请求执行过程中完整记录了我们需要的高CPU耗时堆栈,它通过捕捉一次请求下所有的系统调用事件、整合metric数据,精准还原现场。颠覆我们以往的排障思路:不再是从问题现象,反查、排除和推理,而是从问题发生现场过程,快速定位根因。以此实现10分钟黄金时间快速排障,降低排障门槛,降低对专家经验的依赖。
更多生产环境常见案例以及相应的demo试用环境,大家可前往我们的官网查看体验:
http://kindling.harmonycloud.cn/blogs/use-cases/trace-profiling-menu/introduction-menu/
-
应用与网络问题如何快速定位?
-
如何高效排查生产环境文件IO问题?
-
如何快速排查生产环境多线程问题?
-
业务问题案例:通过报文判断生产环境Spring事务是否生效
5. 关于程序摄像头 Trace Profiling
官网地址:http://kindling.harmonycloud.cn
GitHub:https://github.com/kindlingproject/kindling
6. 序列化知识点拓展
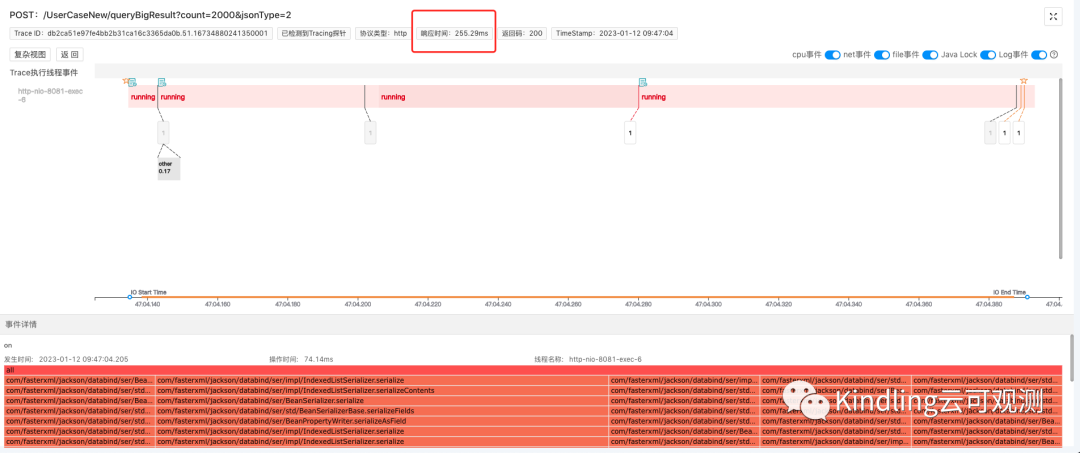
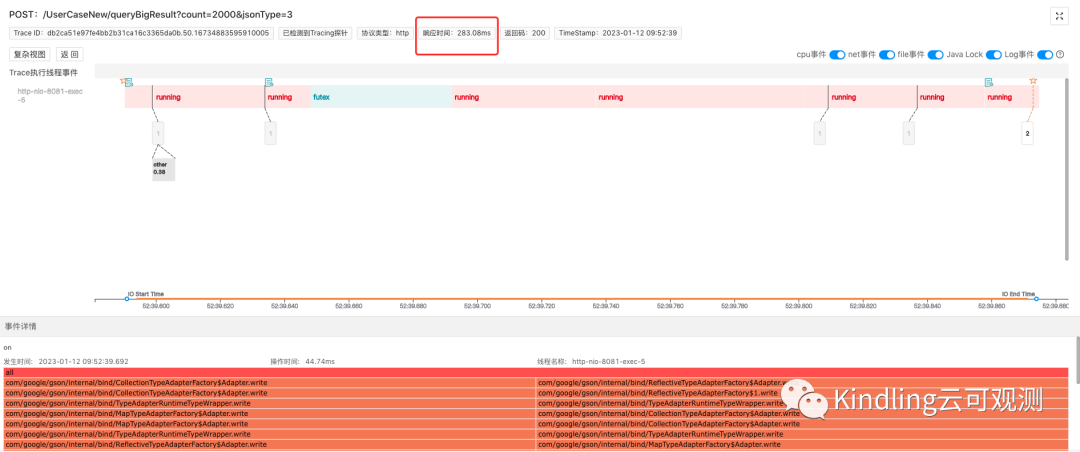
上面的demo中我们用的是Fastjson框架,其他3种序列化框架,Trace捕捉记录如下:
6.1 Jackson 255.29ms
6.2 Gson 283.08ms
6.3 net.sf.json 655.06ms
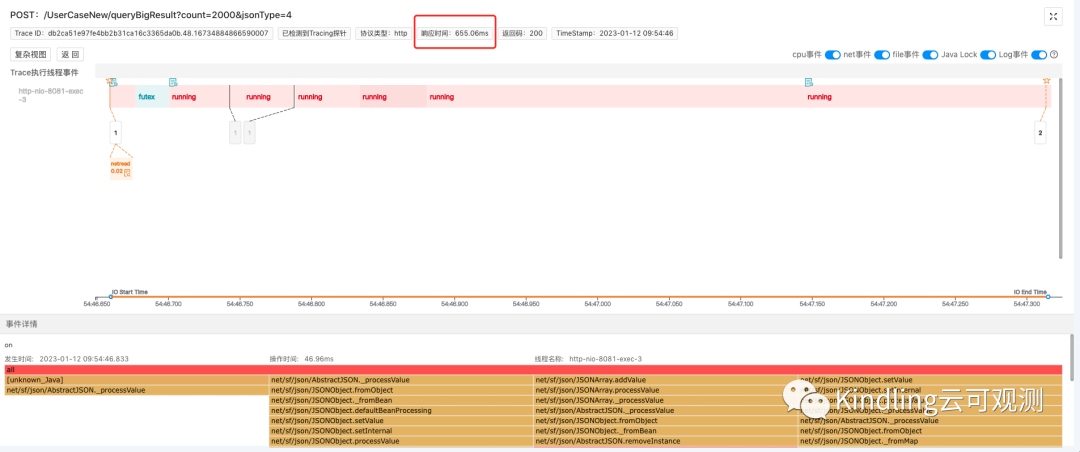
我们可以看到,4种序列化框架工具效率存在差异,尤其是net.sf.json框架,效率很低,我们在开发过程中应该慎用。由此可见,相对其他排障工具,程序摄像头Trace Profiling“更人性化”地帮你捕捉了高CPU耗时的堆栈信息。
以标准化流程,分钟级定位全资源种类故障的根因
kindling 开源团队,公众号:Kindling 云可观测程序摄像头Trace Profiling:生产环境10分钟黄金时间快速排障手册
对本次实验感兴趣或想了解更多程序摄像头 Trace Profiling 的小伙伴可以添加小编wx:Xieyun-kindling


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









