







这篇文章仅仅记录我在学习中所遇到的平时工作中没有遇见的知识。
《从实践中学习Oracle SQL》:
1.转义字符:escape.
select * from dept where dname like 'IT\_%' escape '\';3.SQL*PLUS 命令:使用L(List)查看上条SQL语句,之后可以使用:2 from emp,这样的语句来修改上条语句并执行,2代表行号。"/"命令用来执行上条语句。
4.Oracle substr与Java substring有着完全不一样的用法,Oracle substr(str,m,[n])表示从str中返回从m开始的n个长度的字符串,而Java中的string.substring(int start,int end),是返回string中从start开始到end-1的字符串。
5.Oracle 9i新增单值函数,NVL2(A,B,C)表示表达式A不为空则返回表达式B,为空则返回表达式C;NULLIF(A,B)如果表达式A与B相等则返回NULL否则返回1;COALESCE(A,B,C..)表示表达式A如果为空则返回表达式B,如果表达式A,B为空则返回表达式C.
6.使用数据字典:
SQL> select instance_name,host_name,version,archiver from v$instance;
INSTANCE_NAME HOST_NAME VERSION ARCHIVE
---------------- ---------------------------------------------------------------- ----------------- -------
orcl SAMSUNG-PC 11.2.0.1.0 STOPPED
SQL> select instance_name,host_name,version,archiver from v$instance;
INSTANCE_NAME HOST_NAME VERSION ARCHIVE
---------------- ---------------------------------------------------------------- ----------------- -------
orcl SAMSUNG-PC 11.2.0.1.0 STOPPED
SQL> select name,created,log_mode from v$database;
NAME CREATED LOG_MODE
--------- -------------- ------------
ORCL 20-10月-14 NOARCHIVELOG
SQL> select * from cat;
TABLE_NAME TABLE_TYPE
------------------------------ -----------
BONUS TABLE
DEPT TABLE
EMP TABLE
EMP_T TABLE
SALGRADE TABLE
V_CLERK VIEW
已选择6行。
SQL> select * from user_catalog;
TABLE_NAME TABLE_TYPE
------------------------------ -----------
BONUS TABLE
DEPT TABLE
EMP TABLE
EMP_T TABLE
SALGRADE TABLE
V_CLERK VIEW
已选择6行。
SQL> select table_name from user_tables;
TABLE_NAME
------------------------------
EMP_T
SALGRADE
BONUS
EMP
DEPT
SQL> spool off;
7.使用变量,使用&来读取屏幕输入变量,使用&&来获取已经读取的变量而无需再次提示输入,使用define v_col="Clerk"定义一个变量。
总结:《从实践中学习Oracle SQL》这本书太浅显,有种堆砌代码的感觉,作者也许仅仅是为了写书挣Money.看到后半不想再继续浪费实践看下去了,完全没有任何技术含量的书籍。
---临时搜索学习
Oracle三范式:
第一范式,即有主键数据不能重复。
第二范式,如果一个关系属于1NF,且所有的非关键字段都完全的依赖于主关键字。
目的,消除表中存在不完全依赖主键/关键字的列,将其分离出去。
第三范式,如果一个关系属于2NF,且所有非关键字不传递依赖于主关键字。
目的,消除表设计中存在传递依赖主关键字的列。
执行计划的执行顺序:
并列的缩进块,从上往下执行,非并列的缩进块,从下往上执行:
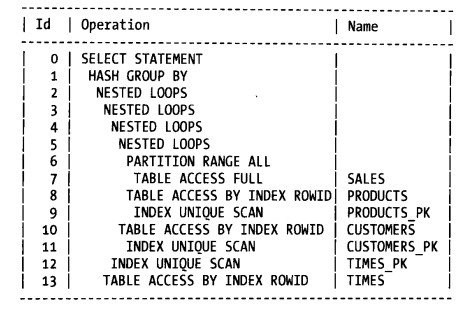
执行顺序:7-->6-->9-->8-->11-->10-->5-->4-->12-->13-->3-->2-->1-->0
《Oracle索引技术》:
1.首先学到的一点:DML(Database Manipulation Language),DCL(Database Control Language),DDL(Database Definition Language),这三种语句是Oracle的所有语句的分类。
2.首先要明白一点索引不是越多越好,一张表中的索引如果建立的越多,将会导致我们再进行增删改的时候,Oracle自己维护索引的开销增加。
3.建立索引的一个基本原则:根据查询表时使用的列制定索引策略。
4.可以为多个列创建多个索引,也可以一个索引包含多个列(组合索引)。当where子句中经常会有多个列时,可以考虑是用组合索引将会非常有效。
5.明白索引是如何提高查询效率的:索引就像一本书的索引一样,书索引关联的是章节和页码,而数据库索引关联的是ROWID和列值,所以索引就像是一个列值得快捷方式,索引的存在主要目的是为了提高查询效率。
6.索引是一种可选对象,它是在一个表的一个或者多个列上定义的,索引要消耗资源,B树索引是Oracle默认的索引类型,在表中最独特的列上创建B树索引最有效,合适的索引才能提高性能,并不是有所有的情况下都能被使用,查询优化器会根据使用索引和全表扫描的开销对比,如果使用索引的开销大于全表扫描,索引肯定不会被使用。
7.B树索引:适用于高基数(不同值成都高的)列值。
8.位图索引:适用于低基数列值,在数据仓库环境下。不适合在线事务处理仓库(OLTP),因为低基数列值中会存在列值相同的情况,当使用DML语句时,会锁定多行,这将导致面向高事务的OLTP系统中锁定问题。
9.索引类型较多,常见的有全局分区索引,本地分区索引等。
10.创建虚拟列值表:
create table (
inv_id number
,inv_count number
,inv_status generated always as(
case when inv_count<=100 then 'GETTING LOW'
when inv_count>100 then 'OKAY'
end )
);11.创建虚拟列索引:
create index inv_idx1 on inv(inv_status);12.查询当前表中有哪些索引都是在哪个列上的:
select t.index_name,t.table_name,t.column_name,i.index_type from
user_ind_columns t,user_indexes i
where t.index_name = i.index_name
and t.table_name = 'INV';1)不要添加不必要的索引,索引的使用时会消耗次磁盘空间和处理资源。
2)所创建的索引应该保证其是最大限度的提升性能
3)考虑使用SQL调优顾问和SQL访问顾问获得索引的建议
4)使用正确的索引类型
5)数据仓库环境中存在非在线联机事务处理考虑使用位图索引
6)检测索引,并删除不被使用的索引
7)删除索引之前,考虑将它标记为不可用或者不可见
8)考虑为索引使用单独的表空间
14.打开执行计划:
set autotrace on;INDEX_NAME TABLE_NAME INDEX_TYPE
--------------- ------------------------------ ----------------------
INV_IDX1 INV FUNCTION-BASED NORMAL
SQL> alter index inv_idx1 invisible;/*索引不可见时,只是对查询优化器不可见但是在数据进行增删的时候Oracle还是要维护它*/
索引已更改。
SQL> alter index inv_idx1 visible;
索引已更改。
SQL> alter index inv_idx1 unusable;/*索引不可用时,Oracle不需要维护它*/
索引已更改。
SQL> alter index inv_idx1 rebuild;
索引已更改。
SQL> drop index inv_idx1;/*删除索引*/16.考虑使用压缩索引来减少索引存储:
SQL> create index job_sal_idx on emp_t(job,sal) compress;--默认是全部列都进行压缩
索引已创建。
SQL> validate index job_sal_idx;
索引已分析
SQL> select opt_cmpr_count,opt_cmpr_pctsave from index_stats;
OPT_CMPR_COUNT OPT_CMPR_PCTSAVE
-------------- ----------------
1 24
--OPT_CMPR_COUNT可以分析出当前的最佳压缩长度,OPT_CMPR_PCTSAVE为节省的存储比例17.用于测试优化器是否会使用该列上的索引时,可以考虑是用无段索引,no segment index,也称假索引,它并不占用存储空间,测试完毕可以删除它。
SQL> create index virtual_idx
2 on emp_t(ename) nosegment;
索引已创建。
SQL> set autotrace on explain;
SQL> alter session set "_use_nosegment_indexes"=true;
会话已更改。
SQL> /
会话已更改。
SQL> select ename from emp_t where ename='KING';
ENAME
----------
KING
执行计划
----------------------------------------------------------
Plan hash value: 1211807338
--------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 7 | 1 (0)| 00:00:01 |
|* 1 | INDEX RANGE SCAN| VIRTUAL_IDX | 1 | 7 | 1 (0)| 00:00:01 |
--------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - access("ENAME"='KING')
Note
-----
- dynamic sampling used for this statement (level=2)
18.全局分区索引分为范围分区索引和散列分区索引。全局索引是异于表分区的而建立的全局表的索引,不去关注表分区和它索引分区段所在哪个分区,它是基于全局表概念的。
19.用的最多的实际是本地分区索引。主要原因是本地分区索引减少了在执行表级分区操作时,整体需要维护的索引分区数量。
20.避免使用索引:
虽然索引大部分时间能够提高查询效率,但是也在一定范围内会没有全表扫描更为有效。以下有几种方法用于不适用索引的方法:
第一种:/*+NO_INDEX(表名 索引名) */
SQL> select /*+ NO_INDEX(f_sales F_SALES_FK1) */ * from f_sales where d_date_id >902; SALES_AMT D_DATE_ID D_PRODUCT_ID D_CUSTOMER_ID ---------- ---------- ------------ ------------- 126 903 5505 4405 执行计划 ---------------------------------------------------------- Plan hash value: 614406235 ----------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | ----------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 1 | 52 | 3 (0)| 00:00:01 | |* 1 | TABLE ACCESS FULL| F_SALES | 1 | 52 | 3 (0)| 00:00:01 | ----------------------------------------------------------------------------- Predicate Information (identified by operation id): --------------------------------------------------- 1 - filter("D_DATE_ID">902) Note ----- - dynamic sampling used for this statement (level=2) 统计信息 ---------------------------------------------------------- 0 recursive calls 0 db block gets 7 consistent gets 0 physical reads 0 redo size 633 bytes sent via SQL*Net to client 416 bytes received via SQL*Net from client 2 SQL*Net roundtrips to/from client 0 sorts (memory) 0 sorts (disk) 1 rows processed SQL> select * from f_sales where d_date_id >902; SALES_AMT D_DATE_ID D_PRODUCT_ID D_CUSTOMER_ID ---------- ---------- ------------ ------------- 126 903 5505 4405 执行计划 ---------------------------------------------------------- Plan hash value: 830240891 -------------------------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | -------------------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 1 | 52 | 2 (0)| 00:00:01 | | 1 | TABLE ACCESS BY INDEX ROWID | F_SALES | 1 | 52 | 2 (0)| 00:00:01 | | 2 | BITMAP CONVERSION TO ROWIDS| | | | | | |* 3 | BITMAP INDEX RANGE SCAN | F_SALES_FK1 | | | | | -------------------------------------------------------------------------------------------- Predicate Information (identified by operation id): --------------------------------------------------- 3 - access("D_DATE_ID">902) filter("D_DATE_ID">902) Note ----- - dynamic sampling used for this statement (level=2) 统计信息 ---------------------------------------------------------- 8 recursive calls 0 db block gets 12 consistent gets 0 physical reads 0 redo size 637 bytes sent via SQL*Net to client 416 bytes received via SQL*Net from client 2 SQL*Net roundtrips to/from client 0 sorts (memory) 0 sorts (disk) 1 rows processed
第二种即是直接指定其使用全表扫描:
使用方式/*+full(表别名)*/
SQL> select * from f_sales e where d_date_id>901; SALES_AMT D_DATE_ID D_PRODUCT_ID D_CUSTOMER_ID ---------- ---------- ------------ ------------- 125 902 5504 4404 126 903 5505 4405 执行计划 ---------------------------------------------------------- Plan hash value: 830240891 -------------------------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | -------------------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 2 | 104 | 2 (0)| 00:00:01 | | 1 | TABLE ACCESS BY INDEX ROWID | F_SALES | 2 | 104 | 2 (0)| 00:00:01 | | 2 | BITMAP CONVERSION TO ROWIDS| | | | | | |* 3 | BITMAP INDEX RANGE SCAN | F_SALES_FK1 | | | | | -------------------------------------------------------------------------------------------- Predicate Information (identified by operation id): --------------------------------------------------- 3 - access("D_DATE_ID">901) filter("D_DATE_ID">901) Note ----- - dynamic sampling used for this statement (level=2) 统计信息 ---------------------------------------------------------- 7 recursive calls 0 db block gets 14 consistent gets 0 physical reads 0 redo size 692 bytes sent via SQL*Net to client 415 bytes received via SQL*Net from client 2 SQL*Net roundtrips to/from client 0 sorts (memory) 0 sorts (disk) 2 rows processed SQL> select /*+full(e)*/ * from f_sales e where d_date_id>901; SALES_AMT D_DATE_ID D_PRODUCT_ID D_CUSTOMER_ID ---------- ---------- ------------ ------------- 125 902 5504 4404 126 903 5505 4405 执行计划 ---------------------------------------------------------- Plan hash value: 614406235 ----------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | ----------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 2 | 104 | 3 (0)| 00:00:01 | |* 1 | TABLE ACCESS FULL| F_SALES | 2 | 104 | 3 (0)| 00:00:01 | ----------------------------------------------------------------------------- Predicate Information (identified by operation id): --------------------------------------------------- 1 - filter("D_DATE_ID">901) Note ----- - dynamic sampling used for this statement (level=2) 统计信息 ---------------------------------------------------------- 0 recursive calls 0 db block gets 8 consistent gets 0 physical reads 0 redo size 684 bytes sent via SQL*Net to client 415 bytes received via SQL*Net from client 2 SQL*Net roundtrips to/from client 0 sorts (memory) 0 sorts (disk) 2 rows processed
21.选择索引or全表扫描:
首先,oracle有两种优化器,RBO(Rule Based Optimizer 基于规则),CBO(Cost Based Optimizer 基于成本,或者讲统计信息),前者是Oracle早期版本的产物,现在Oracle10以后的版本默认都使用了CBO,当然也可以手动去切换到RBO优化器。现在针对CBO讨论下为何Oracle优化器会在我们认为要使用索引扫描的时候却使用全表扫描,
基于成本的优化器的任务是从一组可能的计划中选择最佳或者最优的执行计划。
22.优化成本的构成:表行数,索引行数,每列不同值的数量,索引聚簇因子(即表中索引列的聚集情况),数据分布,表和叶块数量,表块中行的平均数量,索引叶块中叶条目的平均数量,多块读取计数的大小(muti_block_read_count).
23.索引聚簇因子:
CLUSTERING_FACTOR即是索引聚簇因子的值.
SQL> get d:\plsql\index_search
1 select t.index_name,t.table_name,i.index_type,t.column_name from
2 user_ind_columns t,user_indexes i
3 where t.index_name = i.index_name
4* and t.table_name = 'F_SALES'
SQL> select * from f_sales;
SALES_AMT D_DATE_ID D_PRODUCT_ID D_CUSTOMER_ID
---------- ---------- ------------ -------------
123 900 5501 4401
123 901 5502 4402
124 901 5503 4403
125 902 5504 4404
126 903 5505 4405
SQL> col column_name format a10;
SQL> /
INDEX_NAME TABLE_NAME INDEX_TYPE COLUMN_NAM
------------------------------ ------------------------------ --------------------------- ----------
F_SALES_FK1 F_SALES BITMAP D_DATE_ID
SQL> select index_name,clustering_factor from dba_indexes where index_name='F_SALES_FK1';/**CLUSTERING_FACTOR即是索引聚簇因子的值**/
INDEX_NAME CLUSTERING_FACTOR
------------------------------ -----------------
F_SALES_FK1 0/************************************************以下是SQL优化问题********************************************************/
24.使用不等于条件
SQL> select /*+index(F_SALES_FK1)*/ d_date_id from f_sales where d_date_id<>901;
D_DATE_ID
----------
900
902
903
执行计划
----------------------------------------------------------
Plan hash value: 4243678829
--------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 3 | 39 | 1 (0)| 00:00:01 |
| 1 | BITMAP CONVERSION TO ROWIDS | | 3 | 39 | 1 (0)| 00:00:01 |
|* 2 | BITMAP INDEX FAST FULL SCAN| F_SALES_FK1 | | | | |
--------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - filter("D_DATE_ID"<>901)
Note
-----
- dynamic sampling used for this statement (level=2)
统计信息
----------------------------------------------------------
4 recursive calls
0 db block gets
14 consistent gets
2 physical reads
0 redo size
472 bytes sent via SQL*Net to client
415 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
3 rows processed
SQL> select * from f_sales where d_date_id<>901;
SALES_AMT D_DATE_ID D_PRODUCT_ID D_CUSTOMER_ID
---------- ---------- ------------ -------------
123 900 5501 4401
125 902 5504 4404
126 903 5505 4405
执行计划
----------------------------------------------------------
Plan hash value: 614406235
-----------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-----------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 3 | 156 | 3 (0)| 00:00:01 |
|* 1 | TABLE ACCESS FULL| F_SALES | 3 | 156 | 3 (0)| 00:00:01 |
-----------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter("D_DATE_ID"<>901)
Note
-----
- dynamic sampling used for this statement (level=2)
统计信息
----------------------------------------------------------
4 recursive calls
0 db block gets
16 consistent gets
0 physical reads
0 redo size
704 bytes sent via SQL*Net to client
415 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
3 rows processed25.Oracle在Where子句中,可以对datetime、char、varchar字段类型的列用Like子句配合通配符选取那些“很像...”的数据记录,以下是可使用的通配符:
_ 单一任何字符(下划线)
\ 特殊字符
对于查询优化器而言,如果使用通配符进行模糊匹配查询,Oracle优化器更有可能会去进行全表扫描,而不是使用索引。因为使用通配符'%'或者'_'意味着数据库可能必须读取表中的大部分行。如果使用索引,则也需要访问每个索引块,对索引读取完后,可能还需要读取大部分的表块。在这种情况下全表扫描可能会更有效。当然有种情况,使用'%ABC'与使用'ABC%'可能会产生截然不同的优化方式,前者可能会去使用全表扫描,而后者会使用索引扫描,在后导通配符情况下,优化器会事先计算好了,数据库列中匹配ABC前缀的列值,如果不是大部分,那么它会优先去选择该列上的索引。
26.很重要的一点,索引中是不会包含列为空的行的,所以假如执行:
alter table A add( CFYJSNR varchar2(20));/**在test_id列上创建索引**/
INDEX_NAME TABLE_NAME INDEX_TYPE COLUMN_NAM
------------------------------ ------------------------------ --------------------------- ----------
F_SALES_FK1 F_SALES BITMAP D_DATE_ID
F_SALES_TESTID F_SALES NORMAL TEST_ID
SQL> insert into f_sales values(1101,1102,1103,8709,'9001');SQL> select * from f_sales where test_id is null;
SALES_AMT D_DATE_ID D_PRODUCT_ID D_CUSTOMER_ID TEST_ID
---------- ---------- ------------ ------------- --------------------
123 900 5501 4401
123 901 5502 4402
124 901 5503 4403
125 902 5504 4404
126 903 5505 4405
执行计划
----------------------------------------------------------
Plan hash value: 614406235
-----------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-----------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 5 | 320 | 3 (0)| 00:00:01 |
|* 1 | TABLE ACCESS FULL| F_SALES | 5 | 320 | 3 (0)| 00:00:01 |
-----------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter("TEST_ID" IS NULL)
Note
-----
- dynamic sampling used for this statement (level=2)
统计信息
----------------------------------------------------------
0 recursive calls
0 db block gets
8 consistent gets
0 physical reads
0 redo size
805 bytes sent via SQL*Net to client
415 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
5 rows processedSQL> select * from f_sales where test_id is not null;
SALES_AMT D_DATE_ID D_PRODUCT_ID D_CUSTOMER_ID TEST_ID
---------- ---------- ------------ ------------- --------------------
1101 1102 1103 8709 9001
执行计划
----------------------------------------------------------
Plan hash value: 3075927261
----------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
----------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 64 | 0 (0)| 00:00:01 |
| 1 | TABLE ACCESS BY INDEX ROWID| F_SALES | 1 | 64 | 0 (0)| 00:00:01 |
|* 2 | INDEX FULL SCAN | F_SALES_TESTID | 6 | | 0 (0)| 00:00:01 |
----------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - filter("TEST_ID" IS NOT NULL)
Note
-----
- dynamic sampling used for this statement (level=2)
统计信息
----------------------------------------------------------
0 recursive calls
0 db block gets
2 consistent gets
0 physical reads
0 redo size
703 bytes sent via SQL*Net to client
415 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
1 rows processedSQL> create index f_sales_testid on f_sales(test_id,'1');
索引已创建。
SQL> set autotrace on;
SQL> select * from f_sales where test_id is null;
SALES_AMT D_DATE_ID D_PRODUCT_ID D_CUSTOMER_ID TEST_ID
---------- ---------- ------------ ------------- --------------------
123 900 5501 4401
123 901 5502 4402
124 901 5503 4403
125 902 5504 4404
126 903 5505 4405
执行计划
----------------------------------------------------------
Plan hash value: 3124672274
----------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
----------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 5 | 320 | 2 (0)| 00:00:01 |
| 1 | TABLE ACCESS BY INDEX ROWID| F_SALES | 5 | 320 | 2 (0)| 00:00:01 |
|* 2 | INDEX RANGE SCAN | F_SALES_TESTID | 1 | | 1 (0)| 00:00:01 |
----------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("TEST_ID" IS NULL)
Note
-----
- dynamic sampling used for this statement (level=2)
统计信息
----------------------------------------------------------
40 recursive calls
0 db block gets
16 consistent gets
0 physical reads
0 redo size
805 bytes sent via SQL*Net to client
415 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
5 rows processed如果我们再查询中使用了函数例如:
SQL> select * from f_sales where upper(d_date_id) =to_number('901');
SALES_AMT D_DATE_ID D_PRODUCT_ID D_CUSTOMER_ID TEST_ID
---------- ---------- ------------ ------------- --------------------
123 901 5502 4402
124 901 5503 4403
执行计划
----------------------------------------------------------
Plan hash value: 614406235
-----------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-----------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 2 | 128 | 3 (0)| 00:00:01 |
|* 1 | TABLE ACCESS FULL| F_SALES | 2 | 128 | 3 (0)| 00:00:01 |
-----------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter(TO_NUMBER(UPPER(TO_CHAR("D_DATE_ID")))=901)
Note
-----
- dynamic sampling used for this statement (level=2)
统计信息
----------------------------------------------------------
5 recursive calls
0 db block gets
16 consistent gets
0 physical reads
0 redo size
747 bytes sent via SQL*Net to client
415 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
2 rows processed
SQL> select /*+index(f_sales_fk1) */ * from f_sales where upper(d_date_id)='901';
SALES_AMT D_DATE_ID D_PRODUCT_ID D_CUSTOMER_ID TEST_ID
---------- ---------- ------------ ------------- --------------------
123 901 5502 4402
124 901 5503 4403
执行计划
----------------------------------------------------------
Plan hash value: 614406235
-----------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-----------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 2 | 128 | 3 (0)| 00:00:01 |
|* 1 | TABLE ACCESS FULL| F_SALES | 2 | 128 | 3 (0)| 00:00:01 |
-----------------------------------------------------------------------------很显然优化器此时也不会接受你的建议,使用全索引扫描,因为全索引扫描相比于唯一索引扫描慢的多,请注意这条SQL优化问题,我们是在d_date_id列上使用了函数upper(),如果是d_date_id=upper('901');这种写法并不会干扰到优化器使用唯一索引进行扫描。
28.跳过索引前导部分
如果我们创建了一个复合索引包含A,B两列,那么我们再查询的时候只使用了B列,那么此时优化器会执行全表扫描:
SQL> create index f_sales_salesamt_product on f_sales(sales_amt,d_product_id);
索引已创建。
SQL> set autotrace on;
SQL> select * from f_sales;
SALES_AMT D_DATE_ID D_PRODUCT_ID D_CUSTOMER_ID TEST_ID
---------- ---------- ------------ ------------- --------------------
123 900 5501 4401
123 901 5502 4402
124 901 5503 4403
125 902 5504 4404
126 903 5505 4405
1101 1102 1103 8709 9001
已选择6行。
执行计划
----------------------------------------------------------
Plan hash value: 614406235
-----------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-----------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 6 | 384 | 3 (0)| 00:00:01 |
| 1 | TABLE ACCESS FULL| F_SALES | 6 | 384 | 3 (0)| 00:00:01 |
-----------------------------------------------------------------------------
Note
-----
- dynamic sampling used for this statement (level=2)
统计信息
----------------------------------------------------------
5 recursive calls
0 db block gets
16 consistent gets
0 physical reads
0 redo size
841 bytes sent via SQL*Net to client
415 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
6 rows processed
SQL> select * from f_sales where d_product_id=5501;
SALES_AMT D_DATE_ID D_PRODUCT_ID D_CUSTOMER_ID TEST_ID
---------- ---------- ------------ ------------- --------------------
123 900 5501 4401
执行计划
----------------------------------------------------------
Plan hash value: 614406235
-----------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-----------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 64 | 3 (0)| 00:00:01 |
|* 1 | TABLE ACCESS FULL| F_SALES | 1 | 64 | 3 (0)| 00:00:01 |
-----------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter("D_PRODUCT_ID"=5501)
Note
-----
- dynamic sampling used for this statement (level=2)
统计信息
----------------------------------------------------------
5 recursive calls
0 db block gets
16 consistent gets
0 physical reads
0 redo size
694 bytes sent via SQL*Net to client
415 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
1 rows processed
SQL> select * from f_sales where sales_amt=123 and d_product_id=5501 ;
SALES_AMT D_DATE_ID D_PRODUCT_ID D_CUSTOMER_ID TEST_ID
---------- ---------- ------------ ------------- --------------------
123 900 5501 4401
执行计划
----------------------------------------------------------
Plan hash value: 1170520544
--------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 64 | 2 (0)| 00:00:01 |
| 1 | TABLE ACCESS BY INDEX ROWID| F_SALES | 1 | 64 | 2 (0)| 00:00:01 |
|* 2 | INDEX RANGE SCAN | F_SALES_SALESAMT_PRODUCT | 1 | | 1 (0)| 00:00:01 |
--------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("SALES_AMT"=123 AND "D_PRODUCT_ID"=5501)
Note
-----
- dynamic sampling used for this statement (level=2)
统计信息
----------------------------------------------------------
9 recursive calls
0 db block gets
13 consistent gets
0 physical reads
0 redo size
697 bytes sent via SQL*Net to client
415 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
1 rows processed
在这个优化方法中,有一个参数值得我们去注意:optimizer_index_cost_adj,这个参数是oracle优化器选择使用索引开销值和全表扫描开销值得分界线,小于这个值就使用索引扫描,大于这个值就是用全表扫描。
SQL> show parameter optimizer_index_cost_adj;
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
optimizer_index_cost_adj integer 100
SQL> alter session set optimizer_index_cost_adj=90;
会话已更改。
30.使用Index提示:
这里只说明一点,如果我们使用如下的:
SQL> select /*+index()*/ * from f_sales where d_date_id=901;当然了,如果在你所查询的多列中,有多个索引,此时我们可以是用select /*+index_combine(A_index,B_index)*/ * from tb where A=1 and B=2;此时oracle会使用这两个索引最佳的组合,不一定两列索引都使用,是使用最佳的方案,也许是A索引+全表扫描。
31.相关提示说明:
oracle索引有快速全扫描和正常情况下的索引范围扫描,索引范围扫描需要既访问索引又要访问表,而快速全扫描只访问索引。当然还有索引全扫描,相比之下,索引快速扫描比索引全扫描要快的多。
这里有个参数:
SQL> show parameter db_file_multiblock_read_count;
NAME TYPE VALUE
------------------------------------ ----------- -----------
db_file_multiblock_read_count integer 128INDEX_ASC:执行升序的范围索引扫描.
INDEX_DESC:执行降序的范围索引扫描.
INDEX_JOIN:如果索引列包含了查询结果所要求的所有列,即需要查询A,B两列,正好A,B两列上都有索引,那么我们使用INDEX_JOIN(A_INDEX B_INDEX)可以让优化器不用再去查表,而只需要在这两列的索引上进行查找并返回就行.
INDEX_FSS:告诉优化器执行快速全扫描,而不是全索引扫描.
INDEX_SS:告诉优化器执行索引跳跃式扫描,而不是全索引扫描.
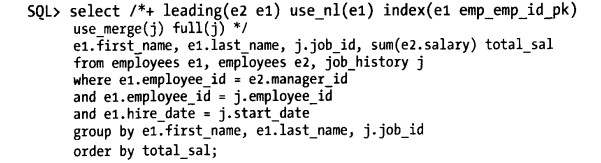
当然了,我们告诉优化器让它使用我们指定的索引,然而优化器有时也不会听话而是直接选择全表扫描,这时候我们就可以使用更为严格的提示来限制优化器只能使用索引扫描,以下提示中使用到了leading,use_nl,use_merge,full这些其他的提示进一步限制优化器的选择。
32.致使索引UNUSABLE的操作:
1)移动表或者表分区(alter table move 和 alter table move partition)
2)对表执行在线重定义
3)截断表分区(alter table truncate partition)
4)导入分区
5)删除表分区
6)拆分表的分区或子分区(alter table split partition)
7)分区索引的维护操作(alter index split partition)
一般的,我们会在执行批量DML语句时候,将索引置为UNUSABLE,执行完操作后,再将索引rebuild或者删除后再次创建
33.Oracle优化器如何处理不可用的索引参数:
SQL> show parameters SKIP_UNUSABLE_INDEXES;
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
skip_unusable_indexes boolean TRUE34.对于Oracle而言我们会经常对表执行删除操作,那么对于索引而言,就会产生大量的碎片,为了优化索引的空间利用率,oracle提供了三种处理方式:
rebuild,coalesec(合并),shrink(收缩),而每种方法分别用于不同目的,对于重建索引,Oracle还提供了一种在线重建索引,也就是在索引重建的过程中还可以执行其他DML操作,而不会有锁表问题,oracle还提供的后两种方式合并和收缩,都是通过重新排列现有的索引条目,减少索引结构中的块数,最终实现碎片整理,但是使用两个命令的目的是不同的。是否合并或收缩取决于索引正处于什么状况。如果认为该索引不可能增长多少,并有很多的空闲空间,那么可以收缩索引以回收空闲空间。然而,如果认为该索引以后可能会再次使用这些空间,那么只需要合并索引,合并索引比收缩索引有优势,因为数据库在索引合并操作期间从来不会锁定索引(合并始终是一种在线操作),而收缩操作在释放空闲空间的过程中确实需要锁定表。而这三种技术中,相比较能用合并不要用收缩,能用合并不要用重建,开销最小是合并,而且合并不会产生锁表问题,但是对于有大量数据删除操作的表,那么这个索引最好是去重建,相比于合并,重建的开销反而会更少些。
35.请注意,在将表移动到其他表空间后,依赖于此表的所有索引都将成为UNUSABLE状态。
36.在有大数据的表中, 为了快速创建索引,建议在使用parallel 12这样的并行机制来完成,会节省时间,但是这样创建完的索引有个问题就是,我们使用user_indexes查看当前索引的dgree时,会发现并行度不是默认值1,而是创建时候使用的数值,这时我们可以关闭parallel,alter index f_sales_fk1 noparallel.
37.还有一个种针对大数据表中的创建索引的优化是不把创建索引写入重做日志。nologging选项,在创建索引的时候加在语句的后门就行。
38.本书到此算是告一段落,再往后就是SQL调优顾问和SQL访问顾问两章,我认为它属于DBA研究范畴,内容也比较繁杂,就算花费很大功夫去学,也记不住,反正明白Oracle为了能让大家写出更为优化的SQL语句和更为合理的优化策略它提供了这两种建议。从这本书中能掌握到的是理解Oracle的内部执行顺序和结构,能够明白Oracle的设计思维和方法,再以后遇到问题的时候就能很好的运用起来,这是种哲学,Oracle的设计哲学,这篇文章发出来只为能跟着大家一起共勉。















 857
857

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









