






非生产环境,就使用一个新一点的版本,提前先踩踩坑,版本的选型真是一个头疼的问题,先看一下apache的官网的测试图:

伪分布式看这里:
配置之前:若是用伪分布式时,在本机必须生成key-gen 与ssh-copy-id到本机,且hosts中必须加入127.0.0.1 本机名并关闭防火墙这几步才可以,否则会报
ryan.pub: ssh: connect to host ryan.pub port 22: No route to host
ryan.pub: Warning: Permanently added 'ryan.pub' (ECDSA) to the list of known hosts.
先选好Spark:3.0.1
对应的Hadoop:3.2和2.7中选一个,综合上面的图,2.7无法使用HBase,只能选3.2了
#hadoop软件:
http://mirror.bit.edu.cn/apache/hadoop/common/hadoop-3.2.1/hadoop-3.2.1-src.tar.gz
#spark软件:
http://archive.apache.org/dist/spark/spark-3.0.1/spark-3.0.1-bin-hadoop3.2.tgz
#spark源码
http://archive.apache.org/dist/spark/spark-3.0.1/spark-3.0.1.tgz
#hadoop源码
http://mirror.bit.edu.cn/apache/hadoop/common/hadoop-3.2.1/hadoop-3.2.1.tar.gz
HBase:2.3.3
http://archive.apache.org/dist/hbase/2.3.3/hbase-2.3.3-bin.tar.gz
Hive: 3.1.2
http://archive.apache.org/dist/hive/hive-3.1.2/apache-hive-3.1.2-bin.tar.gz
ZooKeeper: 3.5.5
http://archive.apache.org/dist/zookeeper/zookeeper-3.5.5/apache-zookeeper-3.5.5-bin.tar.gz
Kafka:2.6-scala2.12
http://mirror.bit.edu.cn/apache/kafka/2.6.0/kafka_2.12-2.6.0.tgz
Flume:1.9
http://mirror.bit.edu.cn/apache/flume/1.9.0/apache-flume-1.9.0-bin.tar.gz
一次性将所有安装包全部传到linux01中,开始配置

集群环境配置:
| 主机名称/IP | spark | hadoop | mysql | hbase | hive | zookeeper | flume | kafka | redis |
| linux01.pub/192.168.10.10 | 1 | 1 | 1 | 1 | 1 | ||||
| linux02.pub/192.168.10.11 | 1 | 1 | 1 | ||||||
| linux03.pub/192.168.10.12 | 1 | 1 | 1 | ||||||
| linux04.pub/192.168.10.13 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | ||
| linux05.pub/192.168.10.14 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | ||
| linux06.pub/192.168.10.15 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
1、先在linux01上安装mysql
千万记住,安装前一定要删除本机所有的Mysql或Mariadb
-
#!/bin/bash -
service mysql stop 2>/dev/null -
service mysqld stop 2>/dev/null -
rpm -qa | grep -i mysql | xargs -n1 rpm -e --nodeps 2>/dev/null -
rpm -qa | grep -i mariadb | xargs -n1 rpm -e --nodeps 2>/dev/null -
rm -rf /var/lib/mysql -
rm -rf /usr/lib64/mysql -
rm -rf /etc/my.cnf -
rm -rf /usr/my.cnf
直接参照此前写过的这篇,不再重复
my-sql centos7下安装_pub.ryan的博客-CSDN博客
检查,mysql是否安装成功,可以用netstat, 如果没有可以用以下命令安装
# 安装网络工具
yum install -y net-tools
# 查看端口或程序
netstat -nltp |grep mysqld #或 3306

2、开始安装Spark:3.0.1与Hadoop3.2.1生态
之前写过一篇Hadoop3.1.1的:快速搭建Hadoop集群环境_windows部署hadoop hbase_pub.ryan的博客-CSDN博客
为了保险还是重新再来一遍
2.1 开始安装Hadoop3.2.1
hdfs是一切的基础,所以在所有机器上配置:namenode:linux01.pub secondary namenode:linux02.pub datanade:linux01~06.pub
#解压
tar -zxf hadoop-3.2.1.tar.gz -C /opt/apps/
2.1.1 配置环境变量,增加路径与登录用户:
vim /etc/profile
-
# hadoop 3.2.1配置 -
export HADOOP_HOME=/opt/apps/hadoop-3.2.1/ -
export HADOOP_HDFS_HOME=$HADOOP_HOME -
export HADOOP_YARN_HOME=$HADOOP_HOME -
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop -
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin -
export HDFS_DATANODE_USER=root -
export HDFS_DATANODE_SECURE_USER=root -
export HDFS_NAMENODE_USER=root -
export HDFS_SECONDARYNAMENODE_USER=root -
export YARN_RESOURCEMANAGER_USER=root -
export YARN_NODEMANAGER_USER=root
source /etc/profile
hadoop version

创建目录:临时文件目录、HDFS 元数据目录、HDFS数据存放目录,以后opt下的所有目录要全部分发到1-6台主机上去,所以统一在opt下创建
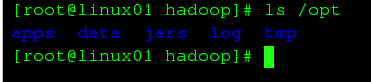
mkdir -p /opt/data/hdfs/name /opt/data/hdfs/data /opt/log/hdfs /opt/tmp
切换到配置文件目录下,开始配置hadoop
cd /opt/apps/hadoop-3.2.1/etc/hadoop
| core-site.xml | 核心配置文件 |
| dfs-site.xml | hdfs存储相关配置 |
| apred-site.xml | MapReduce相关的配置 |
| arn-site.xml | yarn相关的一些配置 |
| workers | 用来指定从节点,文件中默认是localhost |
| hadoop-env.sh | 配置hadoop相关变量 |
先修改hadoop-env.sh,加入java_home的变量,防止出错:
export JAVA_HOME=/home/apps/jdk1.8.0_212
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
2.1.2 开始配置core: core-site.xml
-
<configuration> -
<property> -
<name>fs.defaultFS</name> -
<value>hdfs://linux01.pub:9000</value> -
<description>指定HDFS默认使用的文件系统</description> -
</property> -
<property> -
<name>hadoop.tmp.dir</name> -
<value>/opt/tmp/hdfs</value> -
<description>指定HDFS临时文件位置</description> -
</property> -
</configuration>
2.1.3 配置HDFS:hdfs-site.xml
指定备用地址,副本数,元数据,数据位置,以及web网络访问
-
<configuration> -
<property> -
<name>dfs.namenode.secondary.http-address</name> -
<value>linux02.pub:50090</value> -
<description>HDFS备用namenode位置</description> -
</property> -
<property> -
<name>dfs.replication</name> -
<value>3</value> -
<description>HDFS数据副本数</description> -
</property> -
<property> -
<name>dfs.namenode.name.dir</name> -
<value>/opt/data/hdfs/name</value> -
<final>true</final> -
<description>namenode元数据存储位置</description> -
</property> -
<property> -
<name>dfs.datanode.data.dir</name> -
<value>/opt/data/hdfs/data</value> -
<final>true</final> -
<description>数据存储位置</description> -
</property> -
<property> -
<name>dfs.webhdfs.enabled</name> -
<value>true</value> -
<description>访问namenode的hdfs使用50070端口,访问datanode的webhdfs使用50075端口。访问文件、文件夹信息使用namenode的IP和50070端口,访问文件内>容或者进行打开、上传、修改、下载等操作使用datanode的IP和50075端口。要想不区分端口,直接使用namenode的IP和端口进行所有的webhdfs操作,就需要在所有的datanode上都设置hefs-site.xml中的dfs.webhdfs.enabled为true</description> -
</property> -
<property> -
<name>dfs.permissions.enabled</name> -
<value>false</value> -
<description>文件操作时的权限检查标识, 直接关闭</description> -
</property> -
</configuration>

2.1.4 配置YARN: yarn-site.xml
yarn统一使用linux01.pub
-
<configuration> -
<property> -
<name>yarn.nodemanager.aux-services</name> -
<value>mapreduce_shuffle</value> -
</property> -
<property> -
<name>yarn.resourcemanager.address</name> -
<value>linux01.pub:8032</value> -
</property> -
<property> -
<name>yarn.resourcemanager.scheduler.address</name> -
<value>linux01.pub:8030</value> -
</property> -
<property> -
<name>yarn.log-aggregation-enable</name> -
<value>true</value> -
</property> -
<property> -
<name>yarn.resourcemanager.resource-tracker.address</name> -
<value>linux01.pub:8031</value> -
</property> -
<property> -
<name>yarn.resourcemanager.admin.address</name> -
<value>linux01.pub:8033</value> -
</property> -
<property> -
<name>yarn.resourcemanager.webapp.address</name> -
<value>linux01.pub:8088</value> -
</property> -
<property> -
<name>yarn.nodemanager.env-whitelist</name> -
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value> -
</property> -
</configuration>

2.1.5 配置MapReduce:mapred-site.xml
指定mr使用的yarn模式,节点linux01.pub和类路径
-
<configuration> -
<property> -
<name>mapreduce.framework.name</name> -
<value>yarn</value> -
</property> -
<property> -
<name>mapreduce.jobhistory.address</name> -
<value>linux01.pub:10020</value> -
</property> -
<property> -
<name>mapreduce.jobhistory.webapp.address</name> -
<value>linux01.pub:19888</value> -
</property> -
<property> -
<name>mapreduce.application.classpath</name> -
<value> -
/opt/apps/hadoop-3.2.1/etc/hadoop, -
/opt/apps/hadoop-3.2.1/share/hadoop/common/*, -
/opt/apps/hadoop-3.2.1/share/hadoop/common/lib/*, -
/opt/apps/hadoop-3.2.1/share/hadoop/hdfs/*, -
/opt/apps/hadoop-3.2.1/share/hadoop/hdfs/lib/*, -
/opt/apps/hadoop-3.2.1/share/hadoop/mapreduce/*, -
/opt/apps/hadoop-3.2.1/share/hadoop/mapreduce/lib/*, -
/opt/apps/hadoop-3.2.1/share/hadoop/yarn/*, -
/opt/apps/hadoop-3.2.1/share/hadoop/yarn/lib/* -
</value> -
</property> -
</configuration>
2.1.6 指定所有的datanode: workders
linux01.pub
linux02.pub
linux03.pub
linux04.pub
linux05.pub
linux06.pub
2.1.7 集群分发
将linux01中/opt下的所有文件分发到其它主机,并将/etc/profile也一起分发下去
scp -r /opt linux02.pub:$PWD
scp -r /opt linux03.pub:$PWD
scp -r /opt linux04.pub:$PWD
scp -r /opt linux05.pub:$PWD
scp -r /opt linux06.pub:$PWD
2.1.8 集群一键启动与一键停止
在start-dfs.sh 和stop-dfs.sh中加入以下启动配置
HDFS_DATANODE_USER=root
HADOOP_SECURE_DN_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root

2.1.9 在linux01.pub上初始化namenode:-format
hadoop namenode -format
出现这个信息时,表示已经初始化成功:
2020-11-26 21:03:07,909 INFO common.Storage: Storage directory /opt/data/hdfs/name has been successfully formatted.

2.1.10 启动hadoop并进行测试
主节点上启动HDFS:
start-dfs.sh
namenode上的进程:

datanode上的进程:
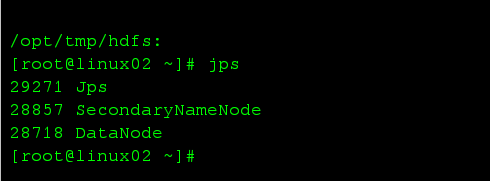
HDFS测试namenode:

start-all.sh
启动HDFS和yarn:


上传一个文件到HDFS:
hdfs dfs -put ./hadoop-3.2.1.tar.gz /

可以看到文件已经被分块存放到不同的服务器上了:


第六台上的数据信息:

主节点上的元数据信息:

2.2 开始安装Spark3.0.1
上传解压到指定文件夹
2.2.1 配置系统变量:
# spark 3.0.1配置
export SPARK_HOME=/opt/apps/spark-3.0.1-bin-hadoop3.2
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
2.2.2 修改配置文件
将所有.template文件复制一份出来,去掉后缀名:
for i in *.template; do cp ${i} ${i%.*}; done
再建立一个目录将原文件移到里面

修改spark-env.sh 加入:
vim spark-env.sh
#加入以下配置
export JAVA_HOME=/home/apps/jdk1.8.0_212
export HADOOP_CONF_DIR=/opt/apps/hadoop-3.2.1/etc/hadoop
export SPARK_MASTER_HOST=linux01.pub
export SPARK_MASTER_PORT=7077
export SPARK_LOCAL_DIRS=/opt/apps/spark-3.0.1-bin-hadoop3.2
在slaves中加入:
linux01.pub
linux02.pub
linux03.pub
linux04.pub
linux05.pub
linux06.pub
2.2.3 分发到其它5台电脑上
scp -r /opt/apps/spark-3.0.1-bin-hadoop3.2/ linux02.pub:$PWD
scp -r /opt/apps/spark-3.0.1-bin-hadoop3.2/ linux03.pub:$PWD
scp -r /opt/apps/spark-3.0.1-bin-hadoop3.2/ linux04.pub:$PWD
scp -r /opt/apps/spark-3.0.1-bin-hadoop3.2/ linux05.pub:$PWD
scp -r /opt/apps/spark-3.0.1-bin-hadoop3.2/ linux06.pub:$PWD
scp -r /opt/apps/spark-3.0.1-bin-hadoop3.2/ linux06.pub:$PWD
2.2.4 运行spark:
进入spark目录下的sbin下,
./start-all.sh
为了区分开hadoop 中的start-all.sh 可以将此名改个名称,以后用这个名称来启动就不会和hadoop相互冲突了,但实际也很少同时都启动,平时hadoop也只是启动其中的hdfs,即start-dfs.sh而已
cp start-all.sh spark-start-all.sh

此时每一台分机上都启动了一个worker进程
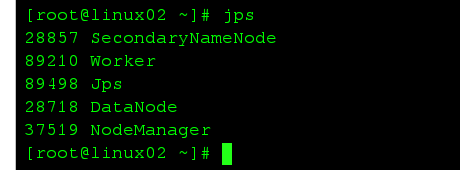

至此,spark搭建就已经完成了,相对比较简单。
3、安装ZooKeeper
安装到:linux04; linux05; linux06;
3.1 解压、添加环境变量
tar -zxf apache-zookeeper-3.5.5-bin.tar.gz -C /opt/apps/
mv apache-zookeeper-3.5.5-bin/ zookeeper3.5.5
cd /opt/apps/zookeeper3.5.5
vim /etc/profile
# Zookeeper配置
export ZK_HOME=/opt/apps/zookeeper3.5.5
export PATH=$PATH:$ZK_HOME/bin
source /etc/profile
3.2 配置文件
在linux04\05\06.pub上各新建一个目录来存放zk的数据:
mkdir -p /opt/data/zkdata
并配置id:
在linux04.pub上: echo 1 > /opt/data/zkdata/myid
在linux05.pub上: echo 2 > /opt/data/zkdata/myid
在linux06.pub上: echo 3 > /opt/data/zkdata/myid
此处id与下面zoo.cfg中的server.1/2/3要相对应
cp zoo_sample.cfg zoo.cfg
vim zoo.cfg
-
dataDir=/opt/data/zkdata -
# the port at which the clients will connect -
clientPort=2181 -
# the maximum number of client connections. -
# increase this if you need to handle more clients -
#maxClientCnxns=60 -
# -
# Be sure to read the maintenance section of the -
# administrator guide before turning on autopurge. -
# -
# http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance -
# -
# The number of snapshots to retain in dataDir -
#autopurge.snapRetainCount=3 -
# Purge task interval in hours -
# Set to "0" to disable auto purge feature -
#autopurge.purgeInterval=1i -
server.1=linux04.pub:2888:3888 -
server.2=linux05.pub:2888:3888 -
server.3=linux06.pub:2888:3888

3.3 启动脚本纺编写
bin/zk-startall.sh
-
#!/bin/bash -
if [ $# -eq 0 ] -
then -
echo "please input param: start stop" -
else -
for i in {4..6} -
do -
echo "${i}ing linux0${i}.pub" -
ssh linux0${i}.pub "source /etc/profile;/opt/apps/zookeeper3.5.5/bin/zkServer.sh ${1}" -
done -
if [ $1 = start ] -
then -
sleep 3 -
for i in {4..6} -
do -
echo "checking linux0${i}.pub" -
ssh linux0${i}.pub "source /etc/profile;/opt/apps/zookeeper3.5.5/bin/zkServer.sh status" -
done fi -
fi

授权执行:chmod +x ./zk-startall.sh
3.4 分发到linux05、06.pub上
scp -r ./zookeeper3.5.5/ linux05.pub:$PWD
scp -r ./zookeeper3.5.5/ linux06.pub:$PWD
3.5 运行与测试
zk-startall.sh

4、开始安装HBase
4.1 环境变量
-
# hbase 配置 -
export HBASE_HOME=/opt/apps/hbase-2.3.3 -
export PATH=$PATH:$HBASE_HOME/bin
4.2 配置hbase
先安装scala2.12.12
https://downloads.lightbend.com/scala/2.12.12/scala-2.12.12.tgz
解压后并配置scala与hbase系统变量
-
# java scala mysql 配置 -
export JAVA_HOME=/home/apps/jdk1.8.0_212 -
export SCALA_HOME=/home/apps/scala-2.12.12 -
export PATH=$PATH:$JAVA_HOME/bin:/usr/local/mysql/bin:$SCALA_HOME/bin -
# hbase配置 -
export HBASE_HOME=/opt/apps/hbase-2.3.3 -
export PATH=$PATH:$HBASE_HOME/bin
4.2.1 将hadoop下的core-site.xml和hdfs-site.xml复制到hbase/conf/下
cp /opt/apps/hadoop-3.2.1/etc/hadoop/core-site.xml /opt/apps/hadoop-3.2.1/etc/hadoop/hdfs-site.xml /opt/apps/hbase-2.3.3/conf
4.2.2 配置hbase-env.sh
export HBASE_MANAGES_ZK=false
export JAVA_HOME=/home/apps/jdk1.8.0_212
4.2.3 配置hbase-site.xml
-
<configuration> -
<property> -
<name>hbase.rootdir</name> -
<value>hdfs://linux01.pub:9000/hbase</value> -
</property> -
<property> -
<name>hbase.cluster.distributed</name> -
<value>true</value> -
</property> -
<property> -
<name>hbase.master</name> -
<value>linux01.pub:60000</value> -
</property> -
<property> -
<name>hbase.zookeeper.quorum</name> -
<value>linux04.pub,linux05.pub,linux06.pub</value> -
</property> -
<property> -
<name>hbase.zookeeper.property.dataDir</name> -
<value>/opt/data/hbase</value> -
</property> -
<property> -
<name>hbase.unsafe.stream.capability.enforce</name> -
<value>false</value> -
</property> -
</configuration>

4.2.4 regionservers配置
-
linux01.pub -
linux02.pub -
linux03.pub -
linux04.pub -
linux05.pub -
linux06.pub
4.2.5 解决日志冲突
#在hbase/lib/client-facing-thirdparty 下
mv /opt/apps/hbase-2.3.3/lib/client-facing-thirdparty/slf4j-log4j12-1.7.30.jar slf4j-log4j12-1.7.30.jar.bak
#将hbase的slf4j文件改名但不删除,作备份作用,以免和hadoop的日志冲突
4.3 分发软件包
分发目录、分发profile、分发hbase目录到linux02.pub~linux06.pub上,已经做过多次,省略
4.4 启动并测试
启动:start-hbase.sh 停止:stop-hbase.sh
#测试进入shell: hbase shell
create 't1', {NAME => 'f1', VERSIONS => 5}
增加网页访问:vim hbase-site.xml
<!-- 新增的web访问配置 -->
<property>
<name>hbase.master.info.port</name>
<value>60010</value>
</property>
访问:http://linux01.pub:60010

检查与zk的集成:

检查与hadoop的集成:

5、开始安装Hive
上传解压
5.1 下载mysql connector

5.2 检查mysql是否启动

5.3、将connector放到hive安装目录下的lib中

[root@linux01 home]# tar -zxf mysql-connector-java-5.1.49.tar.gz -C /opt/apps/hive3.1.2/lib/
[root@linux01 home]# cd /opt/apps/hive3.1.2/lib/[root@linux01 lib]# mv mysql-connector-java-5.1.49/*.jar ./
[root@linux01 lib]# rm -rf mysql-connector-java-5.1.49

5.4 将Hadoop下lib中的guava-27.0-jre.jar 复制到lib下,将原guava-19.0.jar直接删除
[root@linux01 lib]# ls /opt/apps/hadoop-3.2.1/share/hadoop/common/lib/guava-*
/opt/apps/hadoop-3.2.1/share/hadoop/common/lib/guava-27.0-jre.jar[root@linux01 lib]# cp /opt/apps/hadoop-3.2.1/share/hadoop/common/lib/guava-27.0-jre.jar ./
[root@linux01 lib]# rm -rf ./guava-19.0.jar
5.5 配置hive
5.5.1 配置环境变量
# hive配置
export HIVE_BASE=/opt/apps/hive3.1.2
export PATH=$PATH:$HIVE_BASE/bin
5.5.2 配置hive-env.sh
创建hive-env.sh 文件,复制hive-env.sh.template并更名为hive-env.sh:
# hadoop安装目录
export HADOOP_HOME=/opt/apps/hadoop-3.2.1
# Hive 配置文件目录
export HIVE_CONF_DIR=/opt/apps/hive3.1.2/conf
# Hive 信赖jar包目录
export HIVE_AUX_JARS_PATH=/opt/apps/hive3.1.2/lib
5.5.3 配置hive-site.xml
hive-site.xml 文件,复制hive-default.xml.template并更名为hive-site.xml:
删除3210行处的特殊字符:
启动HADOOP:start-all.sh

创建两个hdfs文件夹:
[root@linux01 ~]# hdfs dfs -mkdir -p /user/hive/warehouse; hdfs dfs -mkdir -p /tmp/hive
[root@linux01 ~]# hdfs dfs -chmod -R 777 /user/hive/warehouse; hdfs dfs -chmod -R 777 /tmp/hive
[root@linux01 ~]# hdfs dfs -ls /
Found 3 items
drwxr-xr-x - root supergroup 0 2020-11-27 00:58 /hbase
drwxr-xr-x - root supergroup 0 2020-11-27 11:57 /tmp
drwxr-xr-x - root supergroup 0 2020-11-27 11:57 /user
修改system:java.io.tmp.dir与system:user.name,改为自己创建的临时文件夹与自己的帐号
143、149、1848、4407行

快捷修改VIM:
:%s#${system:java.io.tmpdir}#/opt/tmp/hive#g
:%s#${system:user.name}#root#g
配置数据库:
585行:javax.jdo.option.ConnectionURL value改为:jdbc:mysql://linux01.pub:3306/hive?createDatabaseIfNotExist=true&characterEncoding=UTF-8
1104行:javax.jdo.option.ConnectionDriverName values改为:com.mysql.jdbc.Driver (如果是8.0的com.mysql.cj.jdbc.Driver
1131:javax.jdo.option.ConnectionUserName value改为:你的数据库用户名称
571行:javax.jdo.option.ConnectionPassword value改变:你的密码
800行:hive.metastore.schema.verification value改为:false
5.5.4 创建日志配置文件:hive-log4j2.properties
#将template去掉:
[root@linux01 conf]# cp hive-log4j2.properties.template hive-log4j2.properties
[root@linux01 conf]# vim hive-log4j2.properties# 创建日志目录:
property.hive.log.dir = /opt/log/hive
大坑:hive中的日志jar包与hadoop中的日志jar包冲突,而出现SLF4J: Class path contains multiple SLF4J bindings.
解决方法也很简单:它下面会有提示是哪一个jar,这个必须给开发一个鸡腿,直接把hive中的jar删除就解决了。

5.6 启动hive并测试
初始化:schematool -initSchema -dbType mysql
启动:hive
测试:show tables;

6、安装Flume
6.1、利用模板文件创建conf下的env与conf文件
6.2、在env中加入export java_home
6.3、i测试:进入bin下:.\flume-ng version

6.4、分发到5、6机器上即完成
7、安装Kafka
7.1 启动zookeeper
使用我们自己的脚本:zk-startall.sh start

7.2 修改conf下的server.properties
修改brokerid:
linux04.pub: brokerid-->0
linux05.pub: brokerid-->1
linux06.pub: brokerid-->2
修改绑定的IP:listeners=PLAINTEXT://linux04.pub:9092
修改日志目录:新建一个目录:log.dirs=/opt/log/kafka
修改zk集群:zookeeper.connect=linux04.pub:2181,linux05.pub:2181,linux06.pub:2181
7.3 分发到其它分机:
改brokerid, 改IP, 建目录并改日志目录、配置环境
# Kafka配置
export KAFKA_HOME=/opt/apps/kafka_2in.12-2.6.0
export PATH=$PATH:$KAFKA_HOME/bin
修改id ip
7.4 编写一键启动脚本
-
#!/bin/bash -
if [ $# -eq 0 ] -
then -
echo "please input param: start stop" -
else -
if [ $1 = start ] -
then -
for i in {4..6} -
do -
echo "${1}ing linux0${i}.pub" -
ssh linux0${i}.pub "source /etc/profile;/opt/apps/kafka_2.12-2.6.0/bin/kafka-server-start.sh -daemon /opt/apps/kafka_2.12-2.6.0/config/server.properties" -
done -
fi -
if [ $1 = stop ] -
then -
for i in {4..6} -
do -
ssh linux0${i}.pub "source /etc/profile;/opt/apps/kafka_2.12-2.6.0/bin/kafka-server-stop.sh" -
done -
fi -
fi

启动并测试:

8、安装Redis
8.1 下载解压编译
下载最新版本

unstable就不考虑了
安装gcc:
yum -y install centos-release-scl
yum -y install devtoolset-9-gcc devtoolset-9-gcc-c++ devtoolset-9-binutils
scl enable devtoolset-9 bash
echo "source /opt/rh/devtoolset-9/enable" >> /etc/profile
source /etc/profile
编译:
make && make install PREFIX=/opt/apps/redis6
8.2 配置环境变量
#redis配置
export REDIS_HOME=/opt/apps/redis6
export PATH=$PATH:$REDIS_HOME/bin
8.3 配置redis
将源码包中的redis.conf复制到安装目录下:
cp /opt/jars/redis-6.0.9/redis.conf ./
修改bind为本机名称:bind linux04.pub
修改后台运行:daemonize yes
8.4 启动测试
redis-server ./redis.conf

客户端连接:
redis-cli -h linux04.pub -p 6379

8.5 分发到5和6,并修改绑定主机名称与环境变量
9 Redis集群搭建
(暂时不搭了,抄一下别人的,用到时再来搭)
9.1、Redis Cluster(Redis集群)简介
-
redis是一个开源的key value存储系统,受到了广大互联网公司的青睐。redis3.0版本之前只支持单例模式,在3.0版本及以后才支持集群,我这里用的是redis3.0.0版本;
-
redis集群采用P2P模式,是完全去中心化的,不存在中心节点或者代理节点;
-
redis集群是没有统一的入口的,客户端(client)连接集群的时候连接集群中的任意节点(node)即可,集群内部的节点是相互通信的(PING-PONG机制),每个节点都是一个redis实例;
-
为了实现集群的高可用,即判断节点是否健康(能否正常使用),redis-cluster有这么一个投票容错机制:如果集群中超过半数的节点投票认为某个节点挂了,那么这个节点就挂了(fail)。这是判断节点是否挂了的方法;
-
那么如何判断集群是否挂了呢? -> 如果集群中任意一个节点挂了,而且该节点没有从节点(备份节点),那么这个集群就挂了。这是判断集群是否挂了的方法;
-
那么为什么任意一个节点挂了(没有从节点)这个集群就挂了呢? -> 因为集群内置了16384个slot(哈希槽),并且把所有的物理节点映射到了这16384[0-16383]个slot上,或者说把这些slot均等的分配给了各个节点。当需要在Redis集群存放一个数据(key-value)时,redis会先对这个key进行crc16算法,然后得到一个结果。再把这个结果对16384进行求余,这个余数会对应[0-16383]其中一个槽,进而决定key-value存储到哪个节点中。所以一旦某个节点挂了,该节点对应的slot就无法使用,那么就会导致集群无法正常工作。
-
综上所述,每个Redis集群理论上最多可以有16384个节点。
9.2、集群搭建需要的环境
2.1 Redis集群至少需要3个节点,因为投票容错机制要求超过半数节点认为某个节点挂了该节点才是挂了,所以2个节点无法构成集群。
2.2 要保证集群的高可用,需要每个节点都有从节点,也就是备份节点,所以Redis集群至少需要6台服务器。因为我没有那么多服务器,也启动不了那么多虚拟机,所在这里搭建的是伪分布式集群,即一台服务器虚拟运行6个redis实例,修改端口号为(7001-7006),当然实际生产环境的Redis集群搭建和这里是一样的。
2.3 安装ruby
9.3、集群搭建具体步骤如下(注意要关闭防火墙)
3.1 在usr/local目录下新建redis-cluster目录,用于存放集群节点
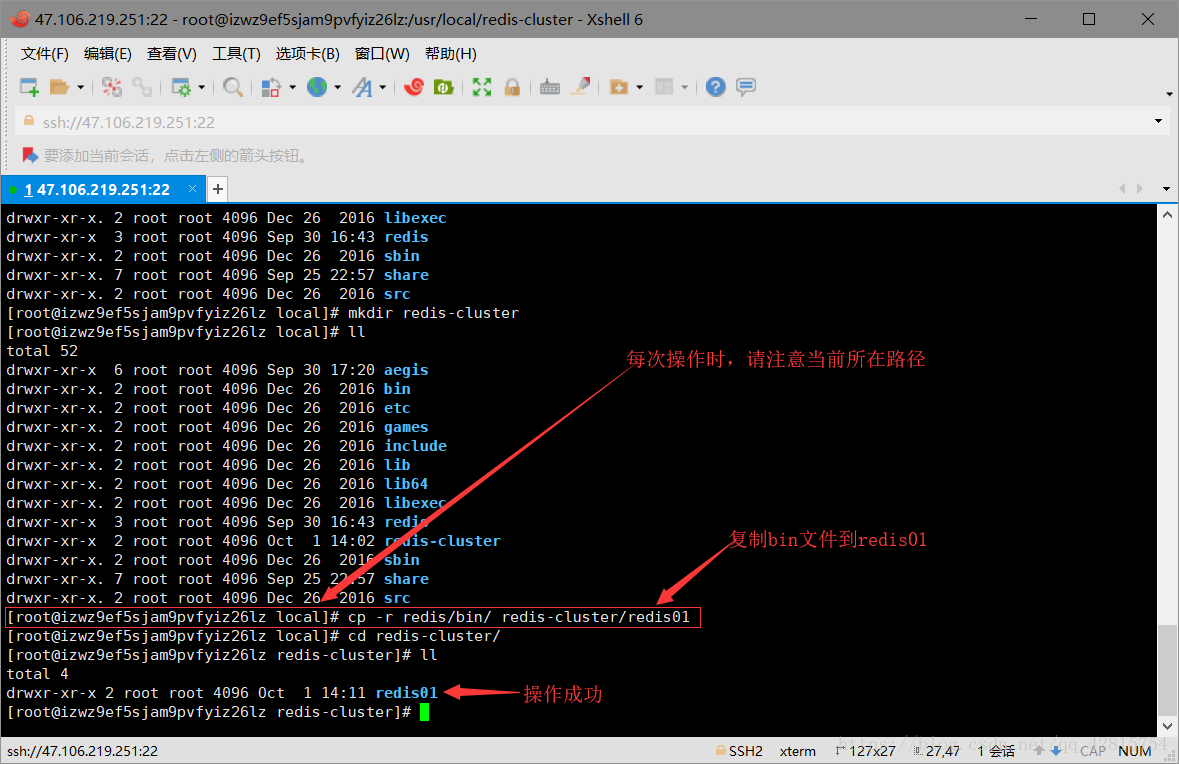
3.2 把redis目录下的bin目录下的所有文件复制到/usr/local/redis-cluster/redis01目录下,不用担心这里没有redis01目录,会自动创建的。操作命令如下(注意当前所在路径):
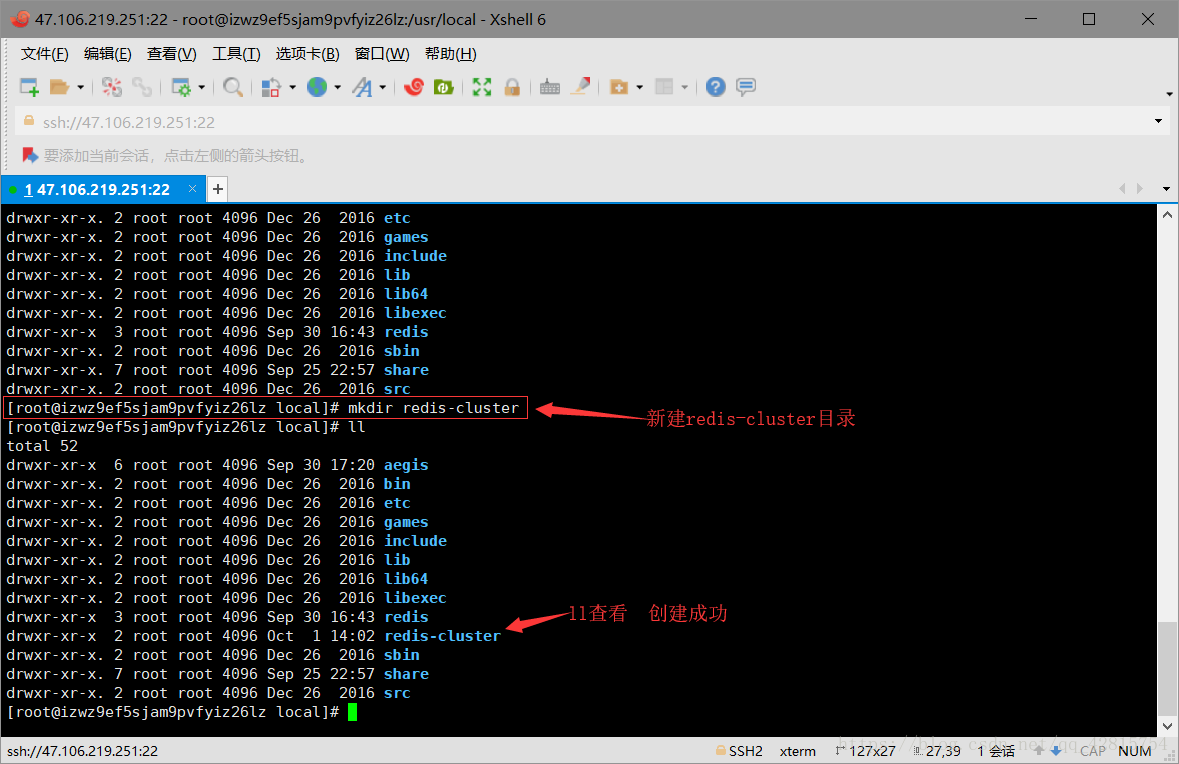
cp -r redis/bin/ redis-cluster/redis01
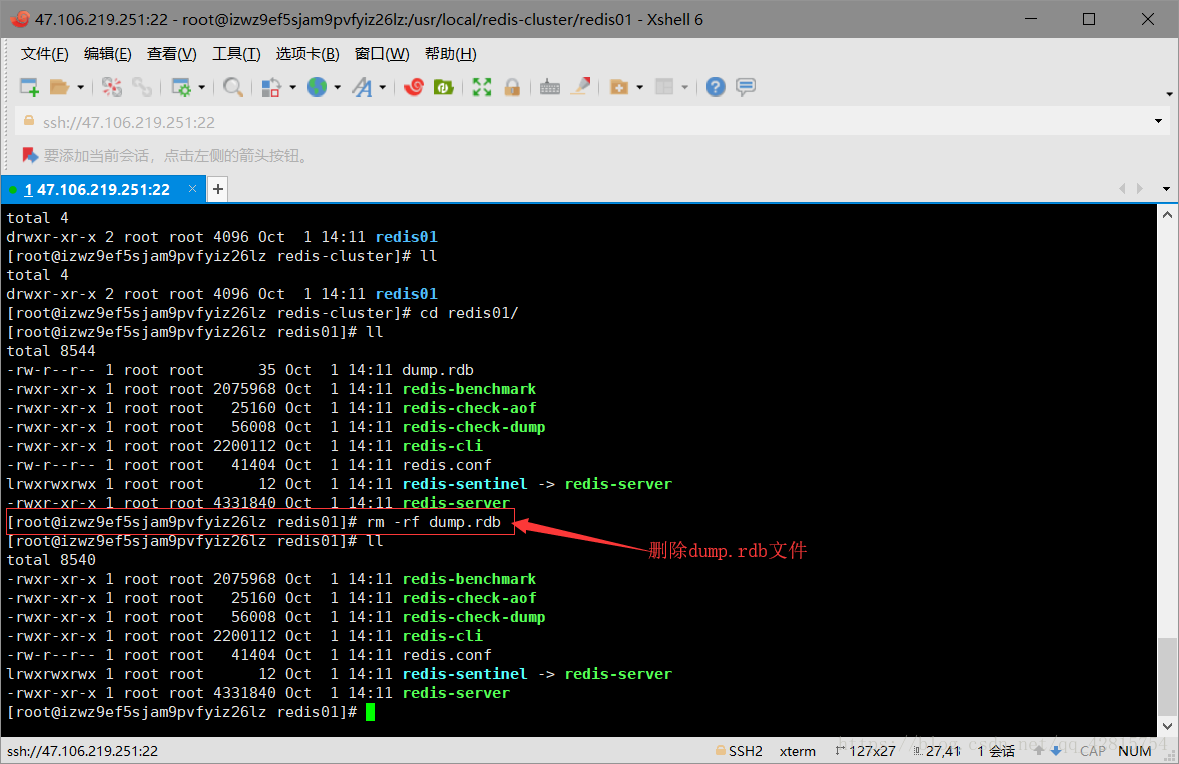
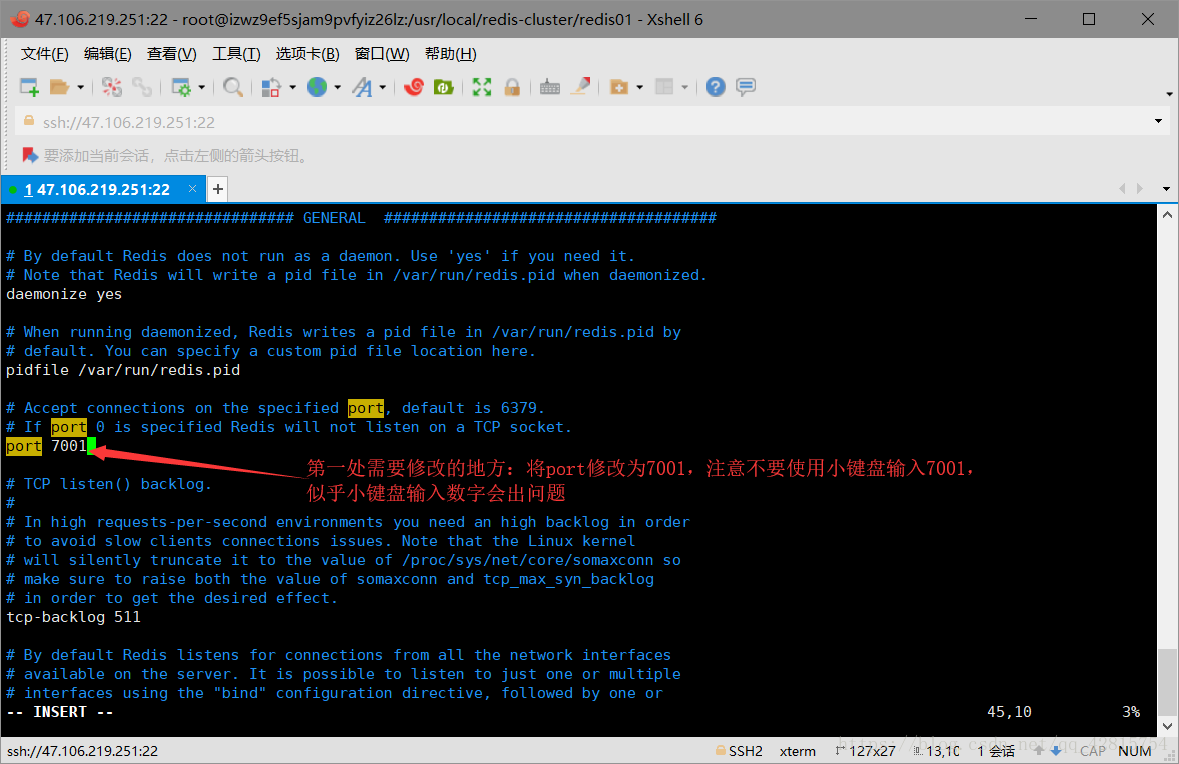
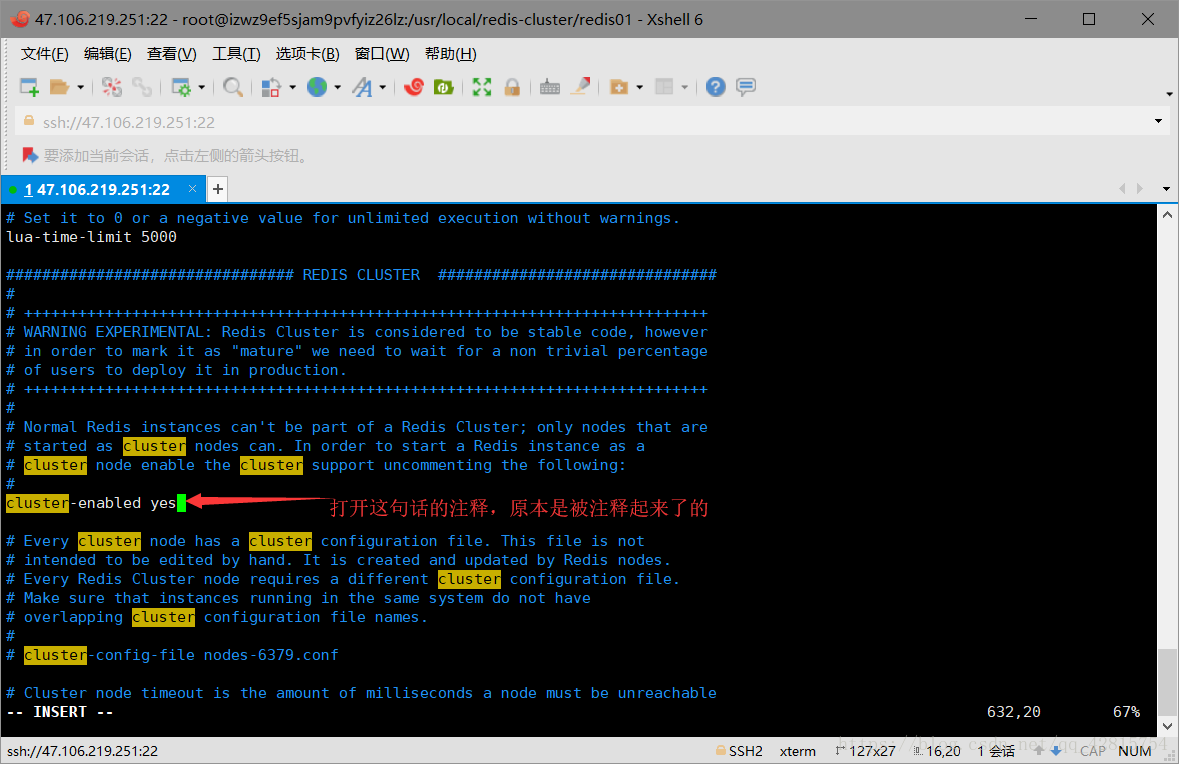
3.3 删除redis01目录下的快照文件dump.rdb,并且修改该目录下的redis.cnf文件,具体修改两处地方:一是端口号修改为7001,二是开启集群创建模式,打开注释即可。分别如下图所示:
删除dump.rdb文件
修改端口号为7001,默认是6379
将cluster-enabled yes 的注释打开
3.4 将redis-cluster/redis01文件复制5份到redis-cluster目录下(redis02-redis06),创建6个redis实例,模拟Redis集群的6个节点。然后将其余5个文件下的redis.conf里面的端口号分别修改为7002-7006。分别如下图所示:
创建redis02-06目录
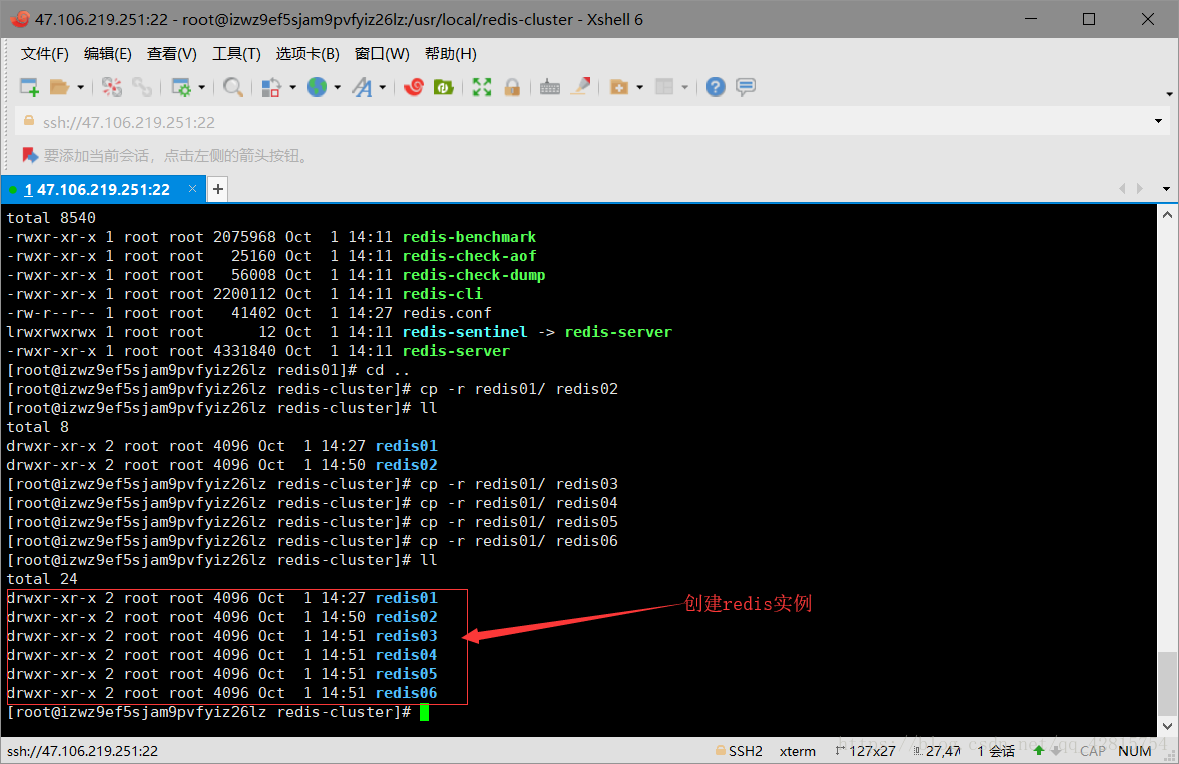
分别修改redis.conf文件端口号为7002-7006
3.5 接着启动所有redis节点,由于一个一个启动太麻烦了,所以在这里创建一个批量启动redis节点的脚本文件,命令为start-all.sh,文件内容如下:
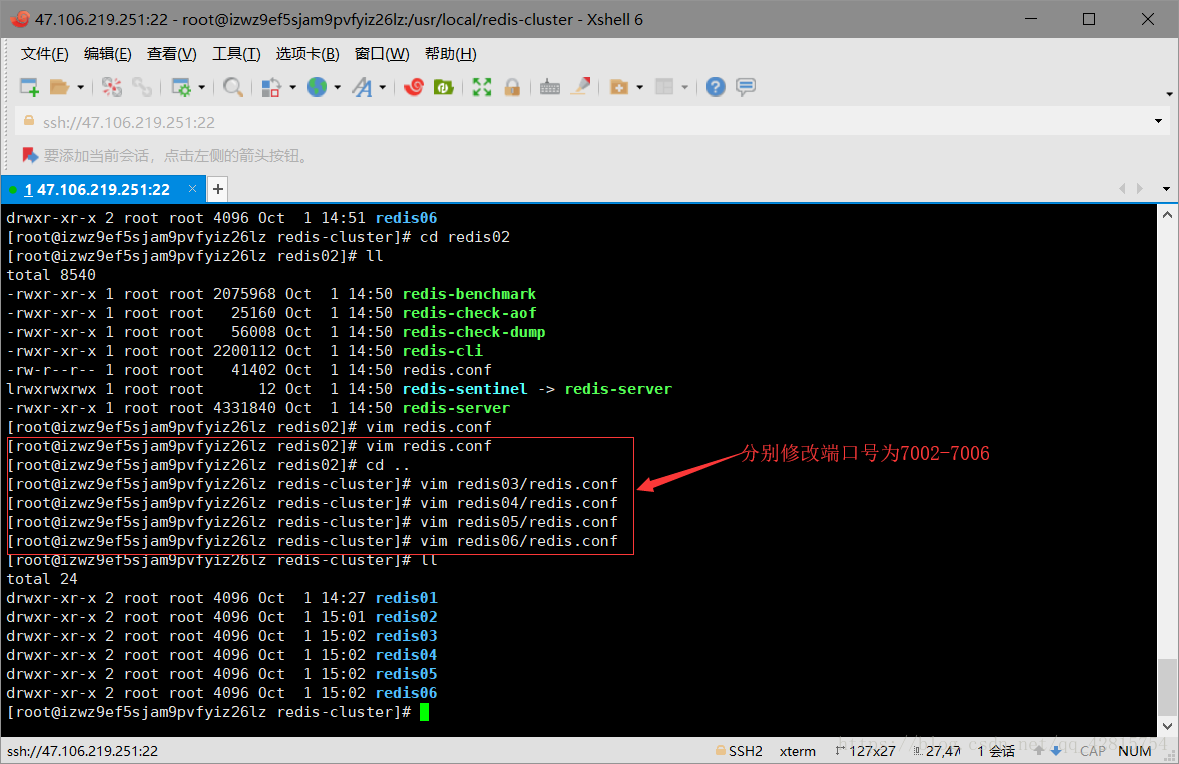
-
cd redis01 -
./redis-server redis.conf -
cd .. -
cd redis02 -
./redis-server redis.conf -
cd .. -
cd redis03 -
./redis-server redis.conf -
cd .. -
cd redis04 -
./redis-server redis.conf -
cd .. -
cd redis05 -
./redis-server redis.conf -
cd .. -
cd redis06 -
./redis-server redis.conf -
cd ..

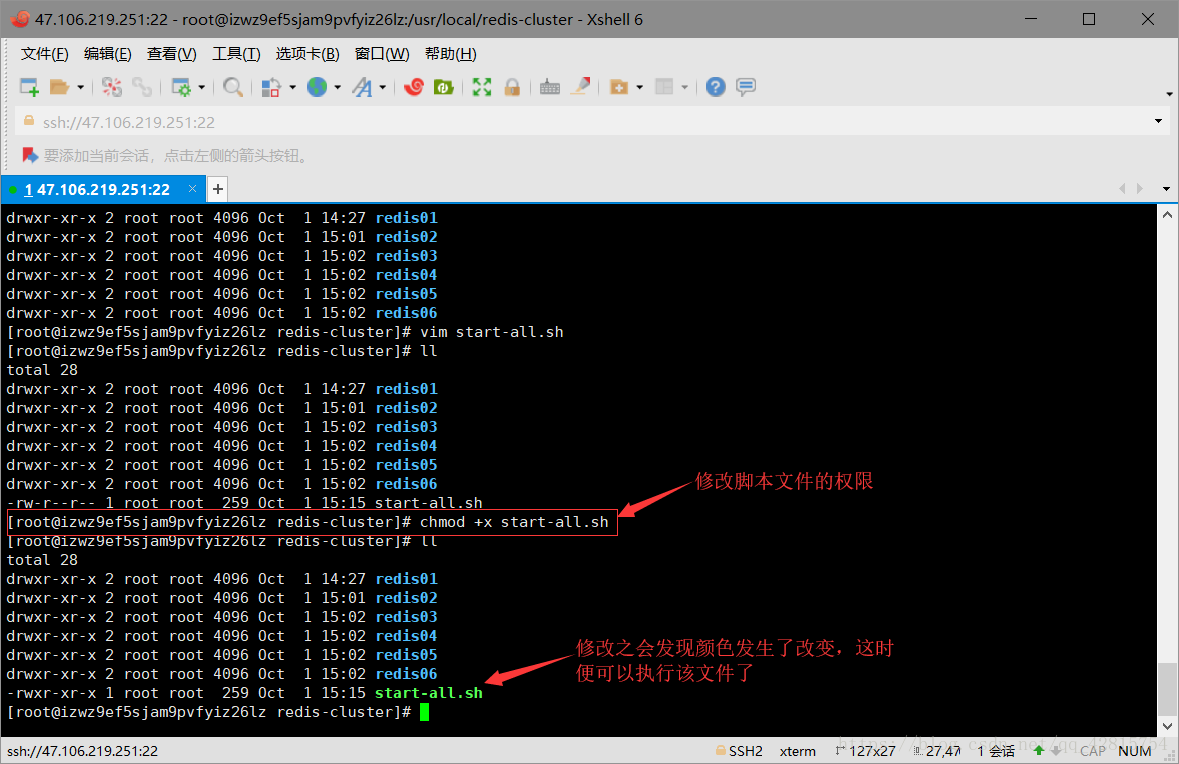
3.6 创建好启动脚本文件之后,需要修改该脚本的权限,使之能够执行,指令如下:
chmod +x start-all.sh
-
1
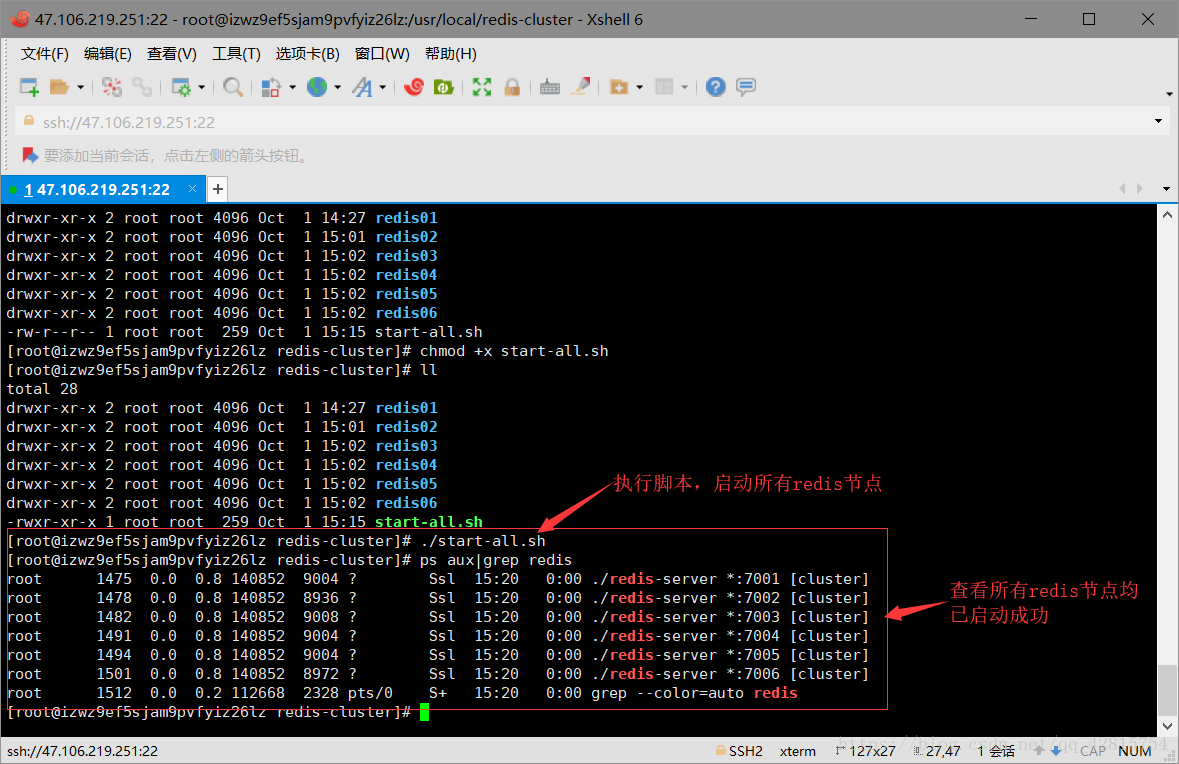
3.7 执行start-all.sh脚本,启动6个redis节点
3.8 ok,至此6个redis节点启动成功,接下来正式开启搭建集群,以上都是准备条件。大家不要觉得图片多看起来冗长所以觉得麻烦,其实以上步骤也就一句话的事情:创建6个redis实例(6个节点)并启动。
要搭建集群的话,需要使用一个工具(脚本文件),这个工具在redis解压文件的源代码里。因为这个工具是一个ruby脚本文件,所以这个工具的运行需要ruby的运行环境,就相当于java语言的运行需要在jvm上。所以需要安装ruby,指令如下:
yum install ruby
然后需要把ruby相关的包安装到服务器,我这里用的是redis-3.0.0.gem,大家需要注意的是:redis的版本和ruby包的版本最好保持一致。
将Ruby包安装到服务器:需要先下载再安装,如图
安装命令如下:
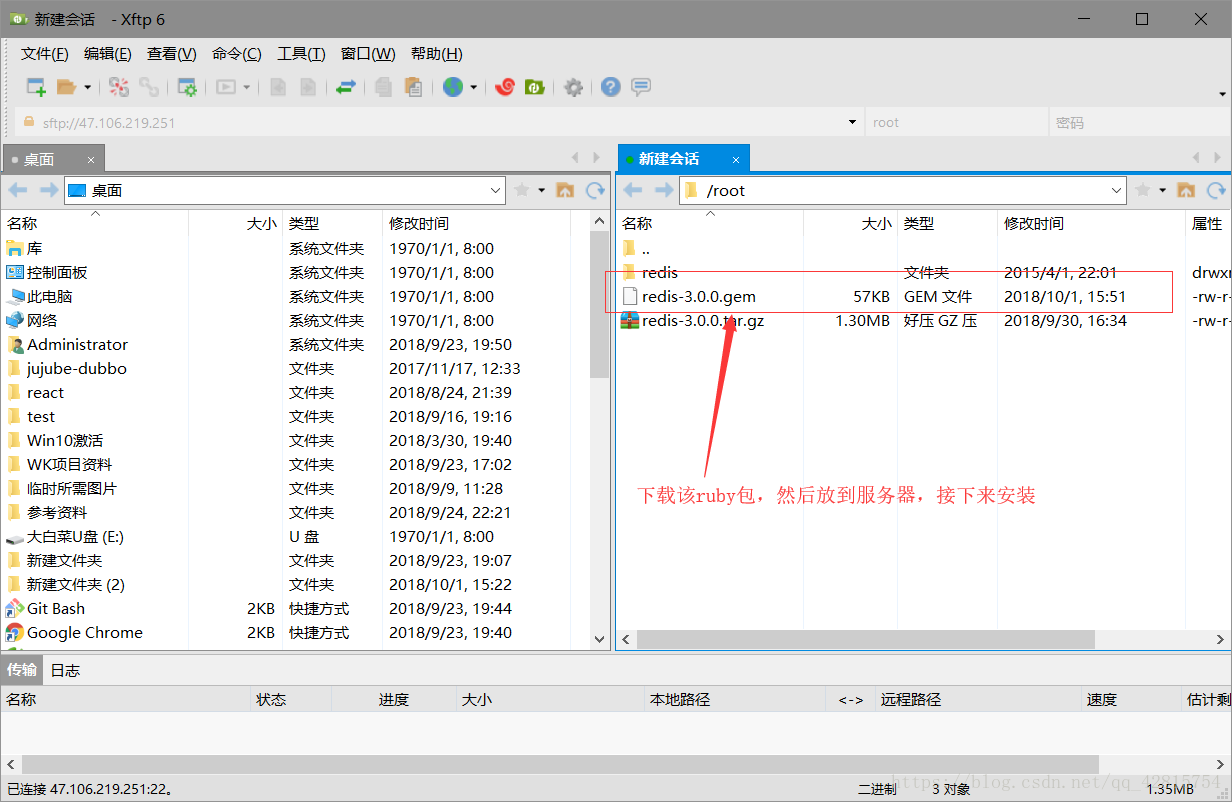
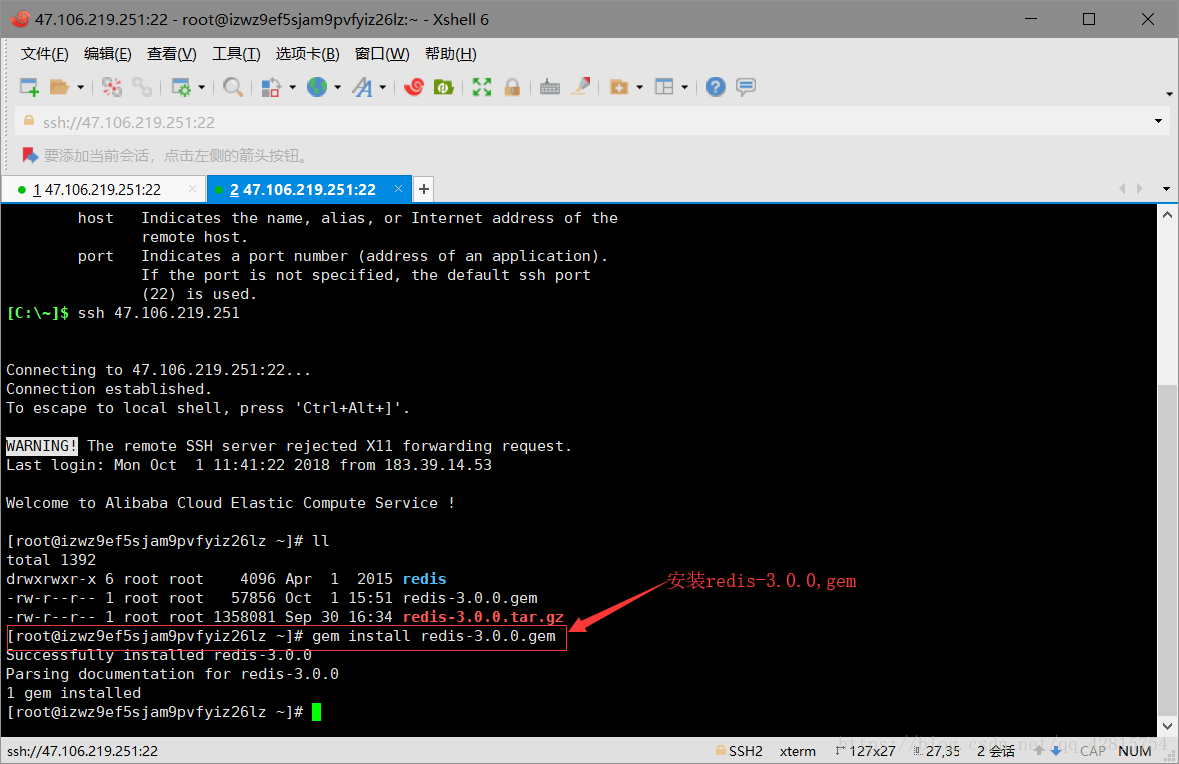
gem install redis-3.0.0.gem
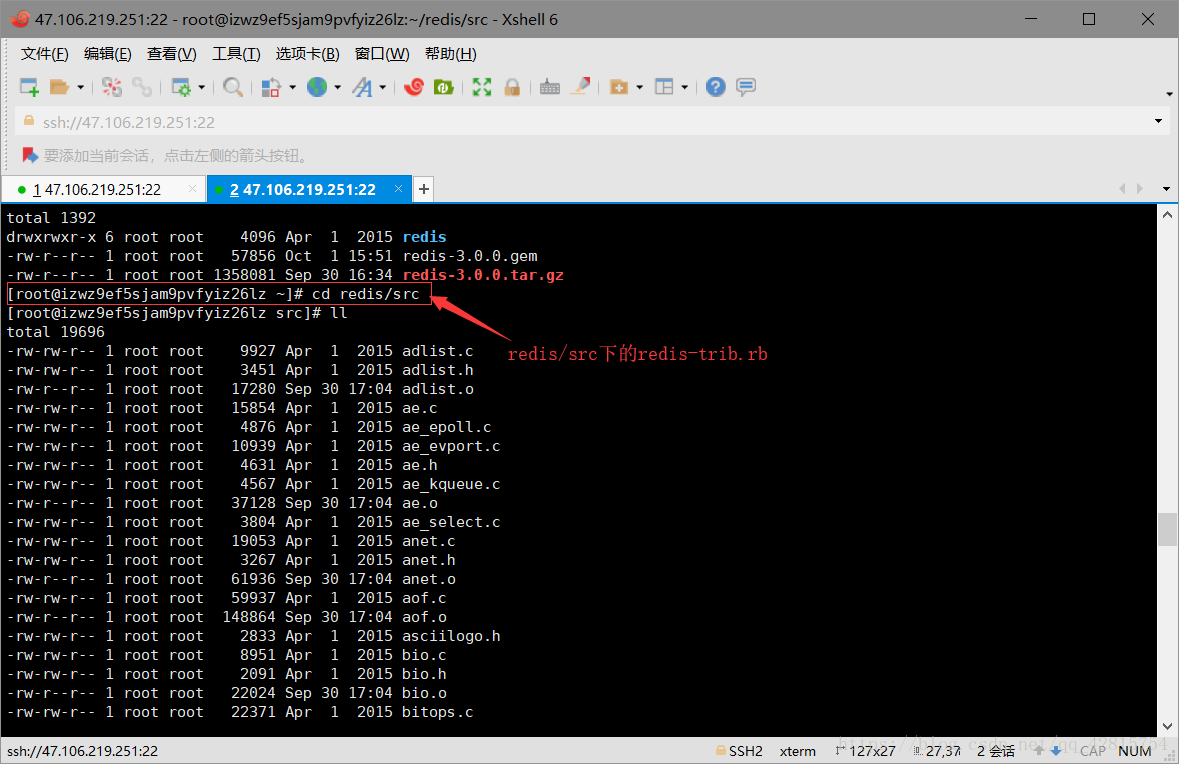
3.9 上一步中已经把ruby工具所需要的运行环境和ruby包安装好了,接下来需要把这个ruby脚本工具复制到usr/local/redis-cluster目录下。那么这个ruby脚本工具在哪里呢?之前提到过,在redis解压文件的源代码里,即redis/src目录下的redis-trib.rb文件。
3.10 将该ruby工具(redis-trib.rb)复制到redis-cluster目录下,指令如下:
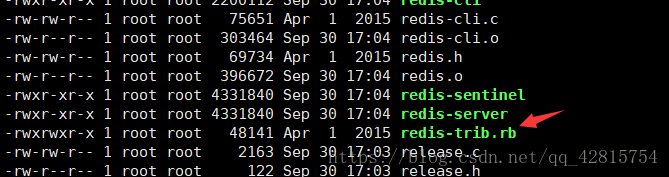
cp redis-trib.rb /usr/local/redis-cluster
然后使用该脚本文件搭建集群,指令如下:
./redis-trib.rb create --replicas 1 47.106.219.251:7001 47.106.219.251:7002 47.106.219.251:7003 47.106.219.251:7004 47.106.219.251:7005 47.106.219.251:7006
注意:此处大家应该根据自己的服务器ip输入对应的ip地址!
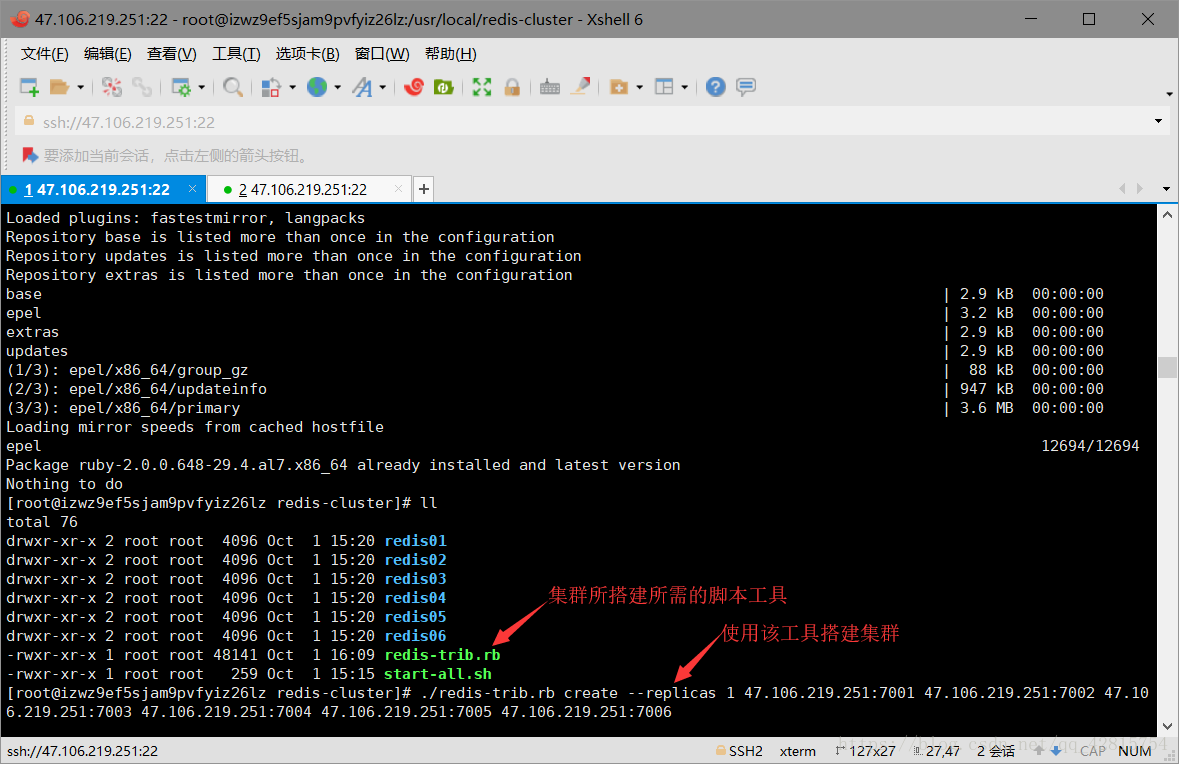
中途有个地方需要手动输入yes即可
至此,Redi集群搭建成功!大家注意最后一段文字,显示了每个节点所分配的slots(哈希槽),这里总共6个节点,其中3个是从节点,所以3个主节点分别映射了0-5460、5461-10922、10933-16383solts。
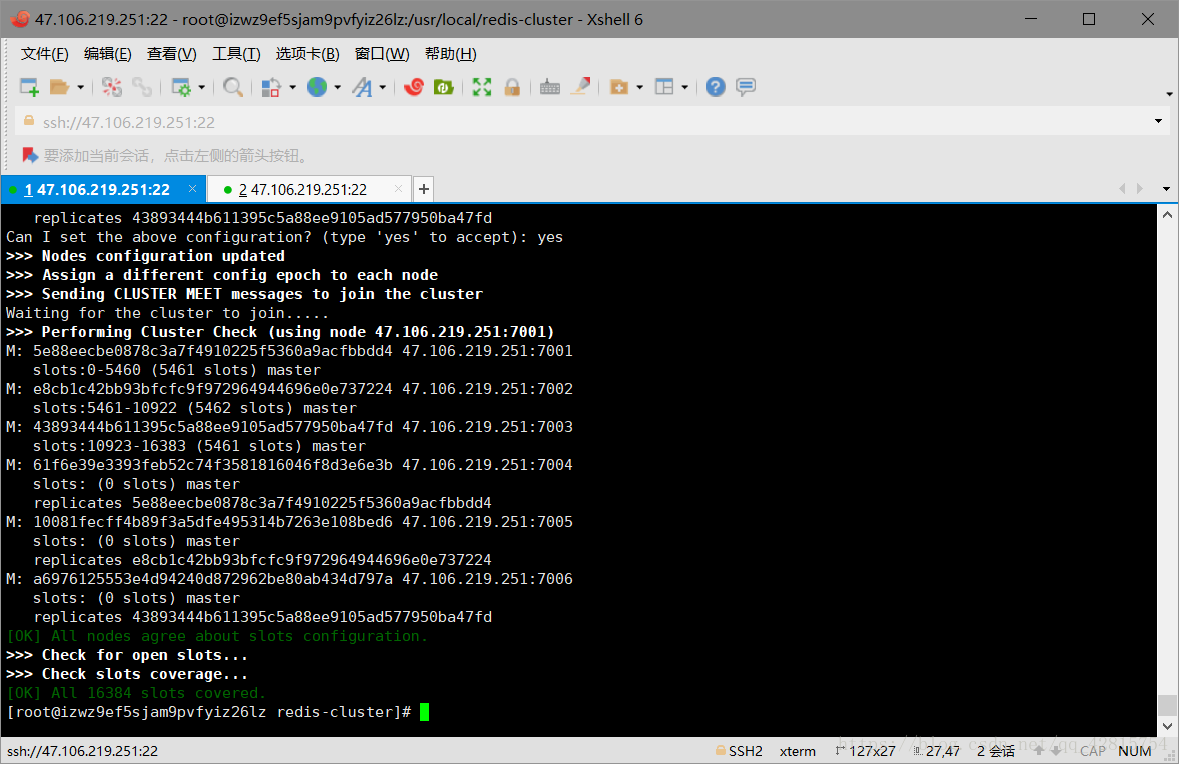
3.11 最后连接集群节点,连接任意一个即可:
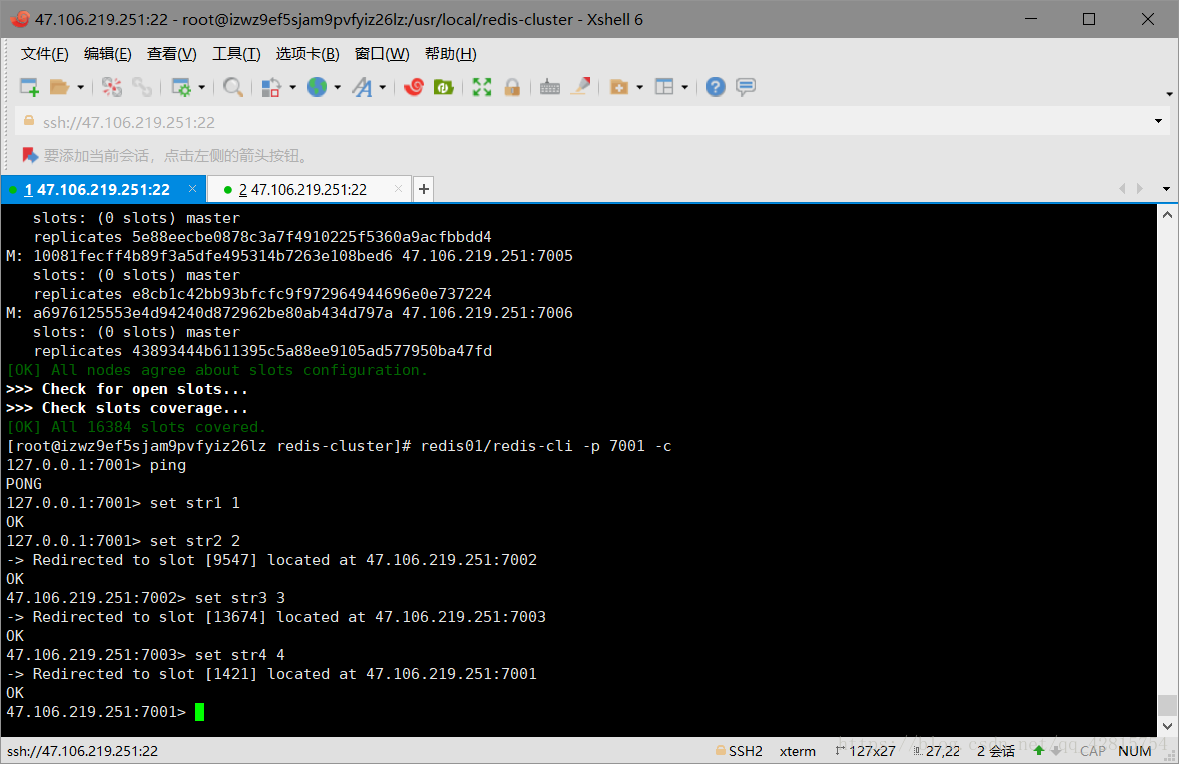
redis01/redis-cli -p 7001 -c
注意:一定要加上-c,不然节点之间是无法自动跳转的!如下图可以看到,存储的数据(key-value)是均匀分配到不同的节点的:
9.4、结语
最后,加上两条redis集群基本命令:
1.查看当前集群信息
cluster info
2.查看集群里有多少个节点
cluster nodes














 584
584











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









