







 本文详细分析了MySQL主从复制中遇到的error1236错误,包括logevent过大、binlog文件缺失、主库空间不足和GTID冲突等问题,提供了相应的解决方法和预防措施。
本文详细分析了MySQL主从复制中遇到的error1236错误,包括logevent过大、binlog文件缺失、主库空间不足和GTID冲突等问题,提供了相应的解决方法和预防措施。
一 前言
MySQL 的主从复制作为一项高可用特性,用于将主库的数据同步到从库,在维护主从复制数据库集群的时候,作为专职的MySQL DBA,笔者相信大多数人都会遇到“Got fatal error 1236 from master when reading data from binary log” 这类的报错/报警。本文整理了常见的几种 error 1236 报错,并给出相应的解决方法,有所不足之处,当然也希望各位读者朋友指正。
二 常见的error 1236 报错
2.1 logevent超过max_allowed_packet 大小
Got fatal error 1236 from master when reading data from binary log: 'log event entry exceeded max_allowed_packet; Increase max_allowed_packet on master; the start event position from 'mysql-bin.006730' at 290066246, the last event was read from '/u01/my3309/log/mysql-bin.006730 【原因】
此类报错和max_allowed_packet相关。首先max_allowed_packet控制着主从复制过程中,一个语句产生的二进制binlog event大小,它的值必须是1024的倍数 。出现此类错误的常见原因是
1 该参数在主备库的配置大小不一样,主库的配置值大于从库的配置值。 从主库传递到备库的binlog event大小超过了主库或者备库的max_allowed_packet大小。
2 主库有大量数据写入时,比如在主库上执行 laod data,insert into .... select 语句,产生大事务。
当主库向从库传递一个比从库的max_allowed_packet 大的packet ,从库接收该packet失败,并报 “log event entry exceeded max_allowed_packet“。
【如何解决】
需要确保主备配置一样,然后尝试调大该参数的值。
set global max_allowed_packet =1*1024*1024*1024; stop slave;start slave
另外,5.6 版本中的 slave_max_allowed_packet_size 参数控制slave 可以接收的最大的packet 大小,该值通常大于而且可以覆盖 max_allowed_packet 的配置, 进而减少由于上面的问题导致主从复制中断。
2.2 slave 在主库找不到binlog文件
Got fatal error 1236 from master when reading data from binary log:
【原因】
该错误发生在从库的io进程从主库拉取日志时,发现主库的mysql_bin.index文件中第一个文件不存在。出现此类报错可能是由于你的slave 由于某种原因停止了好长一段是时间,当你重启slave 复制的时候,在主库上找不到相应的binlog ,会报此类错误。或者是由于某些设置主库上的binlog被删除了,导致从库获取不到对应的binglog file。
【如何解决】
1 为了避免数据丢失,需要重新搭建slave 。
2 注意主库binlog的清理策略,选择基于时间过期的删除方式还是基于空间利用率的删除方式。
不要使用rm -fr 命令删除binlog file,这样不会同步修改mysql_bin.index 记录的binlog 条目。在删除binlog的时候确保主库保留了从库 show slave status 的Relay_Master_Log_File对应的binlog file。
2.3 主库空间问题,日志被截断
Got fatal error 1236 from master when reading data from binary log: 'binlog truncated in the middle of event; consider out of disk space on master; the start event position from 'mysql-bin.006730' at 290066434, the last event was read from '/u01/my3309/log/mysql-bin.006730 【原因】
该错误和主库的空间问题和sync_binlog配置有关,当主库 sync_binlog=N不等于1且磁盘空间满时,MySQL每写N次binary log,系统才会同步到磁盘,但是由于存储日志的磁盘空间满而导致MySQL 没有将日志完全写入磁盘,binlog event被截断。slave 读取该binlog file时就会报错"binlog truncated in the middle of event;"
当sync_binlog 的默认值是0,像操作系统刷其他文件的机制一样,MySQL不会同步到磁盘中去而是依赖操作系统来刷新binary log。
当sync_binlog =N (N>0) ,MySQL 在每写 N次 二进制日志binary log时,会使用fdatasync()函数将它的写二进制日志binary log同步到磁盘中去。
【如何解决】
在从库重新指向到主库下一个可用的binlog file 并且从binlog file初始化的位置开始
stop slave; change master to master_log_file='mysql-bin.006731', master_log_pos=4;start slave;
2.4 主库异常断电,从库读取错误的position
120611 20:39:38 [ERROR] Error reading packet from server: Client requested master to start replication from impossible position ( server_errno=1236) 120611 20:39:38 [ERROR] Slave I/O: Got fatal error 1236 from master when reading data from binary log: 'Client requested master to start replication from impossible position', Error_code: 1236120611 20:39:38 [Note] Slave I/O thread exiting, read up to log 'mysql-bin.000143', position 664526789 【原因】
该问题也是和sync_binlog=N不等于1有关,多出现在主机异常crash ,比如磁盘损坏,raid 卡损坏,或者主机异常掉电导致binlog 未及时同步到磁盘。从库读取了主库binlog file中的不存在的binlog position ,一般比binlogfile 的end position 的值还要大。
【如何解决】
1 在从库重新指向到主库下一个可用的binlog file 并且从binlog file初始化的位置开始
stop slave; change master to master_log_file='mysql-bin.000144', master_log_pos=4;start slave; 2 主备库设置 sync_binlog=1,但是设置为1的时候,会带来性能下降。
方法一:
1、报错如下:
Got fatal error 1236 from master when reading data from binary log: 'The slave is connecting using CHANGE MASTER TO MASTER_AUTO_POSITION=1, but the master has purged binary logs containing GTIDs that the slave requires.'
2、问题解决:
查看mastergtid_purged
show global variables like '%gtid%'; 找到gtid_purged的值
3、从库执行:
mysql> stop slave; mysql> reset slave; mysql> reset master; mysql> set @@global.gtid_purged='你的GITD值'; mysql> change master to master_host='MASTER_IP',master_port=PORT,master_user='USERNAME',master_password='PASSWORD',master_auto_position=1; mysql> start slave; mysql> show slave status \G;
思考:
1、规范搭建主从,主库的数据与从库数据在初始化主从时候务必保持一致。
2、设置从库的super_read_only =on ;, read_only=on;,当主从切换时候在切换时候再把super_read_only =off, ,read_only=off;
3、限制mysql 应用用户权限只能对应用库对象进行增删改查。
方法二:
一、错误原因分析
错误信息如下:
Last_IO_Errno: 1236
Last_IO_Error: Got fatal error 1236 from master when reading data from binary log: 'The slave is connecting using CHANGE MASTER TO MASTER_AUTO_POSITION = 1, but the master has purged binary logs containing GTIDs that the slave requires.'

一般两种情况会出现以上现象
1.在主库上手动执行清除二进制日志文件
2.主库重启,重新同步时
二、解决方法:
1.在主库上执行以下命令,查询gtid_purged,记录下改值
mysql> show global variables like '%gtid%'\G
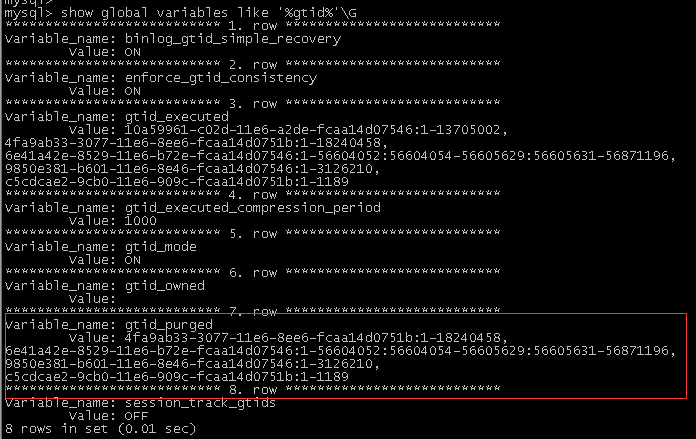
2.在从库上执行以下命令,查询已经执行过的gtid即gtid_executed,记录下主库的值,本机的不需要
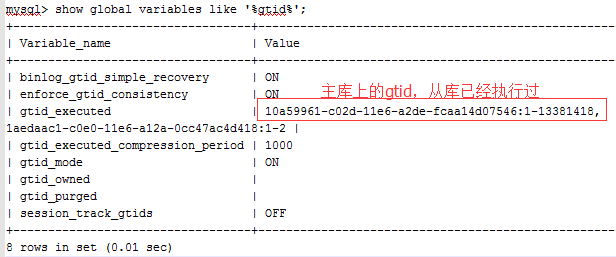
3.在从库上执行以下命令停止同步线程及重置同步相关信息
mysql> stop slave;
mysql> reset slave;
mysql> reset master;
4.在从库上设置gtid_purged
该值有两个来源,一是在主库上查询的gtid_purged,二是在从库上查询的已经执行过的gtid_executed值(本机的就不需要,主库上gtid)
注意:一定记得加上从库上已经执行过的gtid,若只设置了主库上的gtid_purged,此时从库会重新拉取主库上所有的二进制日志文件,同步过程会出现其他错误,导致同步无法进行
mysql> set @@global.gtid_purged='4fa9ab33-3077-11e6-8ee6-fcaa14d0751b:1-18240458,6e41a42e-8529-11e6-b72e-fcaa14d07546:1-56604052:56604054-56605629:56605631-56871196,9850e381-b601-11e6-8e46-fcaa14d07546:1-3126210,c5cdcae2-9cb0-11e6-909c-fcaa14d0751b:1-1189,10a59961-c02d-11e6-a2de-fcaa14d07546:1-13381418';
注意:设置gtid_purged值时,gtid_executed值必须为空否则报错,该值清空的方法就是reset master命令
执行完,再次查看相关信息
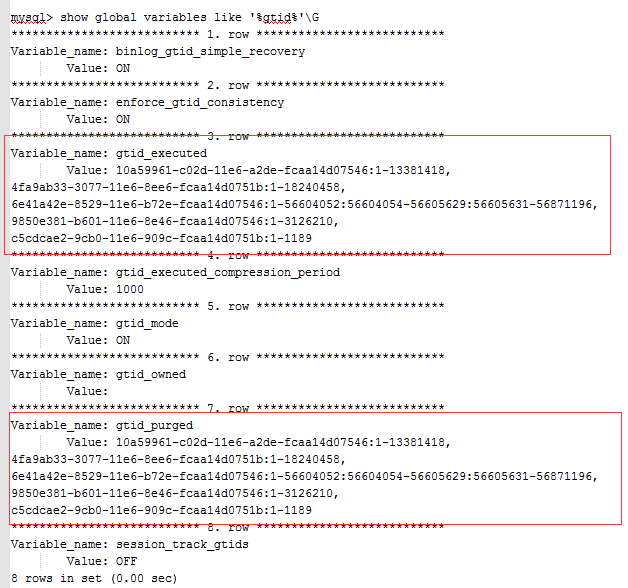
5.重新开启同步
mysql> change master to master_host='192.168.1.15',master_port=3306,master_user='repl',master_password='xxx',master_auto_position=1;
mysql> start slave;
当从库追赶上主库,此时测试主从数据是否一致,测试结果一切正常
mk-table-checksum h=192.168.1.15,u=root,p=xxx,P=3306 h=192.168.1.19,u=root,p=xxxx,P=3307 -d 6coursestudychoose_test | mk-checksum-filter
方法三:mysqlbinlog –no-defaults -v -v –base64-output=decode-rows /data/mysql/mysql-bin.000014 |grep -A 10 1708 > 1.log
Last_SQL_Errno: 1032(从库少数据,主库更新的时候,从库报错)
Last_SQL_Error: Could not execute Update_rows event on table test.t; Can’t find record in ‘t’, Error_code: 1032; handler error HA_ERR_KEY_NOT_FOUND; the event’s master log mysql-bin.000014, end_log_pos 1708
解决问题的办法:根据报错信息,我们可以获取到报错日志和position号,然后就能找到主库执行的哪条sql,导致的主从报错。
在主库执行:
/usr/local/mysql/bin/mysqlbinlog –no-defaults -v -v –base64-output=decode-rows /data/mysql/mysql-bin.000014 |grep -A 10 1708 > 1.log
cat 1.log
#170720 14:20:15 server id 3 end_log_pos 1708 CRC32 0x97b6bdec Update_rows: table id 113 flags: STMT_END_F ### UPDATE `test`.`t` ### WHERE ### @1=4 /* INT meta=0 nullable=0 is_null=0 */ ### @2=’dd’ /* VARSTRING(60) meta=60 nullable=1 is_null=0 */ ### SET ### @1=4 /* INT meta=0 nullable=0 is_null=0 */ ### @2=’ddd’ /* VARSTRING(60) meta=60 nullable=1 is_null=0 */ # at 1708 #170720 14:20:15 server id 3 end_log_pos 1739 CRC32 0xecaf1922 Xid = 654 COMMIT/*!*/; DELIMITER ; # End of log file ROLLBACK /* added by mysqlbinlog */; /*!50003 SET COMPLETION_TYPE=@OLD_COMPLETION_TYPE*/; /*!50530 SET @@SESSION.PSEUDO_SLAVE_MODE=0*/;
获取到SQL语句之后,就可以在从库反向执行SQL语句。把从库缺少的SQL语句补全,解决报错信息。
在从库依次执行:
mysql> insert into t (b) values (‘ddd’); Query OK, 1 row affected (0.01 sec) mysql> stop slave; Query OK, 0 rows affected (0.00 sec) mysql> exit Bye [root@node4 bin]# ./pt-slave-restart -uroot -proot123 2017-07-20T14:31:37 p=…,u=root node4-relay-bin.000005 283 1032
方法四
MYSQL 报错 LAST_SQL_ERRNO: 1032
show slave status \G
-
Last_SQL_Errno: 1032 -
Last_SQL_Error: Could not execute Update_rows event on table 35lq_db.dr_planstats_h; Can't find record in 'dr_planstats_h', Error_code: 1032; handler error HA_ERR_KEY_NOT_FOUND; the event's master log mysql-bin.000010, end_log_pos 317865

end_log_pos 有了它,根据pos值,在主库上直接就能找到,找到那条数据,反做(变成insert)
/usr/local/mysql/bin/mysqlbinlog -v --base64-output=DECODE-ROWS /data/mysql/binlog/mysql-bin.000010 | grep -A '10' 317865
mysql> select * from 35lq_db.dr_planstats_h where id=39222;
知道是那条数据就好办了,
我通过 Navicat for MySQL 把这个表导出,
选择SQL脚本文件
勾选 ‘包含列的标题’
点击‘开始’ 然后就可以看到导出的sql文件位置
使用notepad++ 打开导出的sql文件
找到sql语句,在slave上插入,启动slave。




使用NOTEPAD++ 打开导出的SQL文件

INSERT INTO `dr_planstats_h` (`id`, `day`, `hours`, `uid`, `planid`, `money`, `adstypeid`, `ipnums`, `views`, `clicks`) VALUES (39222, '2018-7-18', 11, 35, 65, 651.5340, 2, 0, 0, 0);















 428
428

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









