







 本文详细介绍了 MongoDB 中创建(Create)、读取(Read)、更新(Update)和删除(Delete)的基本操作,包括文档的增删改查以及集合管理等内容。
本文详细介绍了 MongoDB 中创建(Create)、读取(Read)、更新(Update)和删除(Delete)的基本操作,包括文档的增删改查以及集合管理等内容。
1.概述
1.1创建
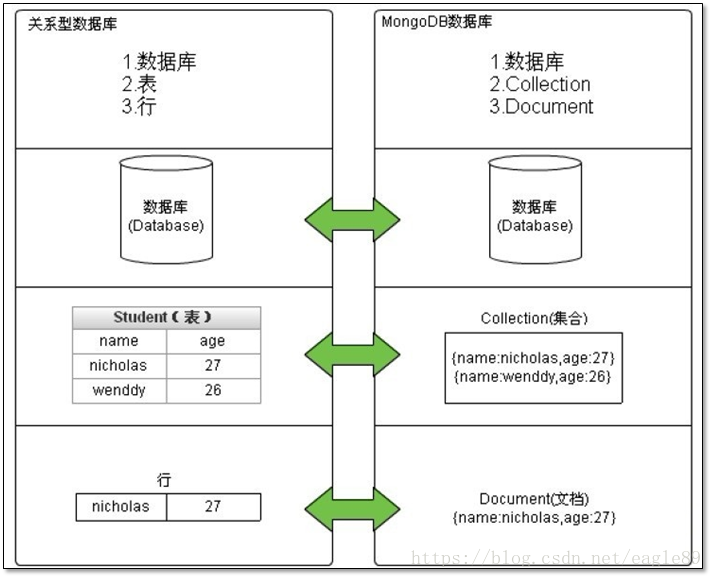
关系型数据库的思想:一个服务器要想存放数据,首先要有数据库,表,字段,约束,当然了也少不了主键,外键,索引,关系等;
MongoDB的世界里边,我们不用预先的去创建这些信息从而直接来使用各个属性。
1、数据库(database)
a)、创建
use mydb(创建并切换到名称为mydb的数据库实例下。注:如果你对其不进行任何操作,该数据库是没有任何实际意义的)
2、集合(collection)---》表
a)、创建
我们直接指定,不做任何预处理,指定一个名称为users的数据集(相当于表),并向其中插入一条用户数据。
db.users.insert({ "name" : "wjg" , "age" : 24 })
返回结果如下,表示你已经成功插入了一条数据:
WriteResult({ "nInserted" : 1 })
b)、显式创建
仅创建一个名称为collectionName的,没有任何大小和数量限制的数据集
db.createCollection("collectionName")
如果该数据集有重名,会给出已经存在的提示:
{ "ok" : 0, "errmsg" : "collection already exists", "code" : 48 }
成功之后会给出ok的提示:
{ "ok" : 1 }
3、文档(document)
a)、单一插入
注:如果没有主键“_id”,插入文档的时候MongoDB会为我们自动保存一个进去。
这里我们指定一个“_id”,当然了,“_id”肯定是不能重复的,否则无法插入成功。
db.users.insert({"_id":0,"name":"jack","age":20})
成功插入数据之后:
WriteResult({ "nInserted" : 1 })
b)、批量插入
注:一次性插入多个文档会明显提高插入速度;
插入文档的大小限制为48MB;
如果其中有一个文档插入失败了,这个文档之前的都可以插入成功,但是在它之后都会失败;(不同的驱动可能会有不同的处理方式)
db.users.insert([{"_id":1,"name":"tom","age":21},{"_id":2,"name":"joe","age":22},{"_id":3,"name":"bob","age":22}])
批量插入成功之后会返回如下信息:
BulkWriteResult({
"writeErrors":[],
"writeConcernErrors":[],
"nInserted":3,
"nUpserted":0,
"nMatched":0,
"nModified":0,
"nRemoved":0,
"upserted":[]})
分别表示的大致意思为:
插入的错误信息,其他的插入错误信息,插入的文档数量,特殊更新的文档数量,匹配到的文档数量,
更新的文档数量,移出的文档数量和特殊文档更新信息
特殊的文档更新(upsert),其定义如下:
如果没有找到符合更新条件的文档,就会以这个条件和更新文档为基础创建一个新的文档;如果找到了匹配的文档,那么就正常更新
1.2更新
想要更新文档,必须要有两个参数:
一个是查询条件,用于定位到需要更新的目标文档;
另一个是修改器,用于说明要对找到的文档进行哪些修改;
截至此刻为止,我们已经向mydb数据库中名称为users的数据集中添加了如下几个文档:

a)、单一更新
让我们来为名字为bob的年龄增加一岁,直接将年龄更新为23岁
db.users.update({"name":"bob"},{$set:{"age":23}}) //使用了$set修改器之后,只会更新age自段的值为23
或者
db.users.update({"name":"bob"},{"age":23}) //同样会将age自段的值更新为23,但是会移出除了“_id”和本身之外的所有字段值
具体详情如下图:
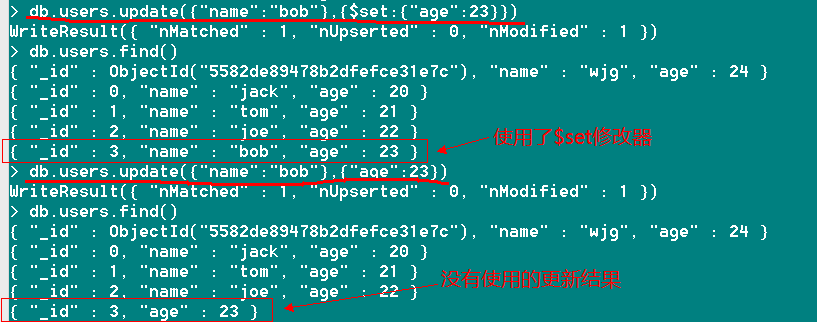
注:如果需要更新的字段不存在,那么MongoDB会按字段顺序进行插入,类似于上边提到的特殊更新。
其实细心的童鞋会发现,我们都是以name作为条件进行更新,所以并不能保证其唯一性,那么MongoDB只会更新匹配到的第一个文档。
这里还是建议大家指定一个唯一的文档进行更新,"_id"可以帮你保证!
b)、使用选择器更新(重点)
1、$set修改器
执行特殊更新操作;可以修改内嵌文档;甚至可以更改键的类型;
Ⅰ、假设需求改了,我们需要为为所有用户添加一个”hobby“的属性用于存放用户的喜好,那么我们可以这样做:
db.users.update({},{$set:{"hobby":"read"}}) //这样做是错的,哈哈。。
更新后的文档如下:

切记:update方法只会更新它匹配到的第一个文档对象,所以这个操作只会将名字为”wjg“的用户添加一个”hobby“属性,其它对象不会添加
正确方式如下:
db.users.update({},{$set:{"hobby":"write"}},false,true) //第三个参数为是否启用特殊更新,第四个为是否更新所有匹配的文档;
这俩参数默认都为false
更新后的文档如下:

可以看到我们成功更新了五个文档对象
Ⅱ、假设我们需求又变了,老板说了,每个用户的爱好会有多个。那么简单,因为我们可以直接将string类型的hobby属性改成string数组类型的
db.users.update({"_id":0},{"$set":{"hobby":["write","read","paly ping-pong"]}}) //将_id为0的hobby属性更新为数组类型的
Ⅲ、然后我们发现tom压根就没有爱好,那么我们可以使用$unset修改器将其删除
db.users.update({"_id":1},{"$unset":{"hobby":1}}) //1表示彻底删除这个键值对
Ⅳ、现在已经过去一年了,我们是时候把所有用户的年龄加一岁了。这时$inc上场
db.users.update({},{"$inc":{"age":1}},false,true) //别忘了将第四个参数置为true
注:$inc修改器只针对数字类型,如果是string或者其他类型的会提示报错:
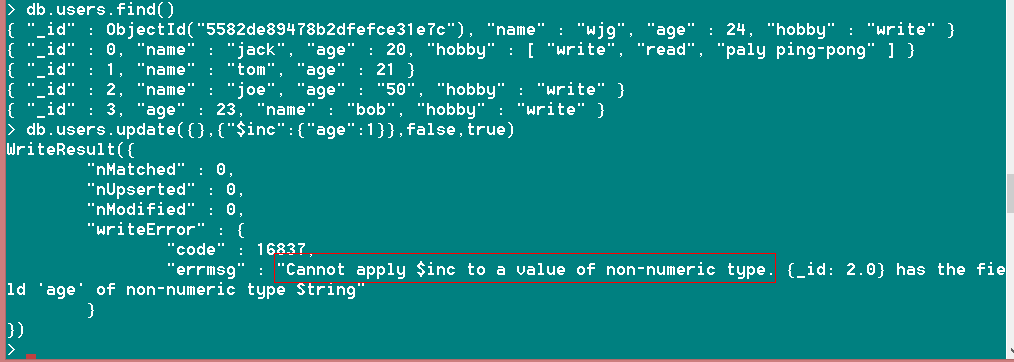
提示无法将$inc应用到非数字类型上,并且给出错误位置:”_id“为2的文档;
我们将joe的age改为数字类型的重新执行一次,就可以成功啦!
Ⅴ、过了一段时间,jack又喜欢上了游泳,那么我们可以用$push这样搞:
db.users.update({"_id":0},{"$push":{"hobby":"swim"}}) //hobby必须是一个数组,所以你在其他文档上使用是不会成功的
Ⅵ、然而jack不喜欢读书了,我们就用$pull来移除“read”元素
db.users.update({"_id":0},{"$pull":{"hobby":"read"}}) //它会移除数组中所有匹配到的“read”元素
另外:db.users.update({"_id":0},{"$pop":{"hobby":1}}) //表示移除hobby中的最后一个元素,为-1表示移除第一个元素

不知道大家有没有发现,“_id”为0的文档从第二的位置被移动到了数据集的末尾,这是因为该文档尺寸变大的原因导致的,
原先的位置已经容不下它了!
那么这就引出了另外一个概念:填充因子,它是MongoDB为每个新文档预留的增长空间。上边的这种情况就会使填充因子增加。
移动文档是一个非常缓慢的操作,尽量让填充因子的值接近1;
通过db.users.stats()查看该数据集信息,“paddingFactor”即为填充因子的大小;
1.3删除
删除文档相对来说就简单了许多
1、单一删除
给定一个查询参数,只要符合条件的,都会被删除
db.users.remove({"_id":{"$lte":1}}) //删除“_id”的值小于等于1的所有文档
返回结果如下:
WriteResult({"nRemoved":2}) //成功删除了两个文档
2、清空整个数据集
db.users.remove()
如果数据较多的话,用db.users.drop()会明显提升删除速度
注:删除都是不可逆的,不能撤销,也不能恢复,所以要谨慎使用;
清空数据集的时候集合本身并不会被删除,也不会删除集合的元信息;
1.3.1删除文档的常用方法
1、删除文档常用方法
db.collection.remove()
删除满足匹配条件的一个或多个文档
db.collection.deleteOne()
删除满足匹配条件的最多一个文档(即使有多个文档满足匹配条件),3.2版本支持
db.collection.deleteMany()
删除满足匹配条件的所有文档
单个或集合内的所有文档的删除,与之相应的索引并不会被删除
文档删除的操作属于原子性操作,仅仅在单个文档级别,可以理解为关系型数据库的行级锁
2、语法
db.collection.remove(
<query>, //查询或过滤条件
{
justOne: <boolean>, //用于确定是单行还是删除所有行(true为缺省值即单行)
writeConcern: <document> //设定写安全,用于确保强一致性还是弱一致性
}
)
1.3.2准备环境
> db.users.insertMany(
[
{
_id: 1,
name: "sue",
age: 19,
type: 1,
status: "P",
favorites: { artist: "Picasso", food: "pizza" },
finished: [ 17, 3 ],
badges: [ "blue", "black" ],
points: [
{ points: 85, bonus: 20 },
{ points: 85, bonus: 10 }
]
},
{
_id: 2,
name: "bob",
age: 42,
type: 1,
status: "A",
favorites: { artist: "Miro", food: "meringue" },
finished: [ 11, 25 ],
badges: [ "green" ],
points: [
{ points: 85, bonus: 20 },
{ points: 64, bonus: 12 }
]
},
{
_id: 3,
name: "ahn",
age: 22,
type: 2,
status: "A",
favorites: { artist: "Cassatt", food: "cake" },
finished: [ 6 ],
badges: [ "blue", "red" ],
points: [
{ points: 81, bonus: 8 },
{ points: 55, bonus: 20 }
]
},
{
_id: 4,
name: "xi",
age: 34,
type: 2,
status: "D",
favorites: { artist: "Chagall", food: "chocolate" },
finished: [ 5, 11 ],
badges: [ "red", "black" ],
points: [
{ points: 53, bonus: 15 },
{ points: 51, bonus: 15 }
]
},
{
_id: 5,
name: "xyz",
age: 23,
type: 2,
status: "D",
favorites: { artist: "Noguchi", food: "nougat" },
finished: [ 14, 6 ],
badges: [ "orange" ],
points: [
{ points: 71, bonus: 20 }
]
},
{
_id: 6,
name: "abc",
age: 43,
type: 1,
status: "A",
favorites: { food: "pizza", artist: "Picasso" },
finished: [ 18, 12 ],
badges: [ "black", "blue" ],
points: [
{ points: 78, bonus: 8 },
{ points: 57, bonus: 7 }
]
}
]
)
1.3.3演示文档删除
1、db.collection.deleteOne
//语法如下
db.collection.deleteOne(
<filter>, //查询的过滤条件
{
writeConcern: <document> //用于控制写入何时应答及超时
}
)
> db.users.find({status:"A"}).count()
3
> db.users.deleteOne({status:"A"})
{ "acknowledged" : true, "deletedCount" : 1 }
> db.users.find({status:"A"}).count()
2
2、删除多个文档
//语法,参数同deleteOne
db.collection.deleteMany(
<filter>,
{
writeConcern: <document>
}
)
> db.users.deleteMany({status:"A"})
{ "acknowledged" : true, "deletedCount" : 2 }
> db.users.find({status:"A"}).count()
0
3、db.collection.remove
//语法
db.collection.remove(
<query>, //过滤条件
{
justOne: <boolean>, //可选条件,布尔类,为true时,仅删除满足条件单个文档,否则删除满足条件全部文档
writeConcern: <document> 写安全参数,用于控制写入何时应答及超时
}
)
//对于db.collection.remove,当justOne为true时等同于deleteOne方法,为false时等同于deleteMany方法
//如下,当不指定任何参数的时候,收到错误提示,即需要指定过滤条件,防止误清空整个集合
> db.users.remove()
2016-10-21T23:48:31.766+0800 E QUERY [thread1] Error: remove needs a query :
DBCollection.prototype._parseRemove@src/mongo/shell/collection.js:406:1
DBCollection.prototype.remove@src/mongo/shell/collection.js:433:18
@(shell):1:1
> db.users.find({status:"D"}).count()
2
> db.users.createIndex({name:1})
{
"createdCollectionAutomatically" : false,
"numIndexesBefore" : 1,
"numIndexesAfter" : 2,
"ok" : 1
}
> db.users.getIndexes()
[
{
"v" : 1,
"key" : {
"_id" : 1 //Author : Leshami
}, //Blog : http://blog.csdn.net/leshami
"name" : "_id_",
"ns" : "test.users"
},
{
"v" : 1,
"key" : {
"name" : 1
},
"name" : "name_1",
"ns" : "test.users"
}
]
//删除满足状态为D的任意一个文档
> db.users.remove({status:"D"},true)
WriteResult({ "nRemoved" : 1 })
//删除满足年龄大于20的所有文档
> db.users.remove({age:{$gt:20}})
WriteResult({ "nRemoved" : 1 })
//删除满足年龄小于20的所有文档
//且writeConcern参数w为majority,该参数通常用于副本集中,确定有几个节点写入成功才应答给客户端
//此列中表明,满足大多数即可返回应答给客户端,如3个节点复制集,2个节点写入即可返回应答
//wtimeout为写入超时参数,避免写入因意外故障导致挂起,陷入无限等待
> db.users.remove(
{ age: { $lt: 20 } },
{ writeConcern: { w: "majority", wtimeout: 5000 } }
)
WriteResult({ "nRemoved" : 1 })
//此时查看集合,已经无文档返回
> db.users.find()
//查看索引,索引依旧存在,尽管没有任何文档
> db.users.getIndexes()
[
{
"v" : 1,
"key" : {
"_id" : 1
},
"name" : "_id_",
"ns" : "test.users"
},
{
"v" : 1,
"key" : {
"name" : 1
},
"name" : "name_1",
"ns" : "test.users"
}
]
> db.users.dropIndexes()
{
"nIndexesWas" : 2,
"msg" : "non-_id indexes dropped for collection",
"ok" : 1
}
//下面直接删除这个空集合
> db.users.drop()
true
//再次查看当前数据库下已经无任何集合对象
> show collections;
1.3.4小结
1、文档的移除通过使用db.collection.remove()方法来实现。
2、db.collection.remove()方法,当justOne为true时等同于db.collection.deleteOne
3、db.collection.remove()方法,当justOne为false时等同于db.collection.deleteMany
4、文档的删除以及全部删除后,对于已经创建的索引依旧存在,可以单独删除(dropIndexes)或者删除整个集合
5、参数writeConcern: <document>在副本集的时候用于副本集数据库一致性
{
"author": "张三",
"title": "MongoDB简介",
"content": "它是介于关系型数据库和非关系型数据库之间的一种NoSQL数据库,用C++编写,是一款集敏捷性、可伸缩性、扩展性于一身的高性能的面向文档的通用数据库",
"tags": [
"MongoDB",
"NoSQL"
],
"comment": [
{
"name": "Jack",
"detail": "Good!",
"date": ISODate("2015-07-09 09:55:49")
},
{
"name": "Tom",
"detail": "Hello World!",
"date": ISODate("2015-07-09 18:12:35")
},
{
"name": "Alice",
"detail": "你好,Mongo!",
"date": ISODate("2015-07-10 20:30:30")
}
],
"readCount": 154
},
{
"author": "李四",
"title": "1+1等于几",
"content": "有的人说1+1=2,因为这是老师从小告诉我们的;而有的人说1+1=11,这是两个1的组合;但是有些人就认为1+1=1,他们觉得1个团队加上另一个团队,会组成了一个更强大的团队!",
"tags": [
"story",
"rule",
"数学"
],
"comment": [
{
"name": "王小光",
"detail": "每个人心里边都有自己的答案。",
"date": ISODate("2015-07-10 11:45:57")
}
],
"readCount": 367
},
{
"author": "李四",
"title": "如何写一篇好的博客?",
"content": "1、目标;2、坚持;3、分享;4、学习;5、提高",
"tags": null,
"comment": [
{
"name": "小明",
"detail": "ComeOn!!!!",
"date": ISODate("2015-07-10 14:49:06")
},
{
"name": "Nike",
"detail": "终身学习!",
"date": ISODate("2015-07-11 10:22:36")
},
{
"name": "小红",
"detail": "贵在坚持吧、",
"date": ISODate("2015-07-12 12:12:12")
}
],
"readCount": 1489,
"isTop": true
}
])
1、查询所有博客
db.blogs.find()
或
db.blogs.find({})
注:查询一个文档:db.blogs.findOne()
2、查询所有博客的标题和内容(指定需要返回的键值)
db.blogs.find({},{"title":1,"content":1,"_id":0})
注:1表示返回,0表示不返回。默认情况下,“_id”这个键总是被返回,即便是没有指定这个键
3、查询作者为“张三”的博客(=操作)
db.blogs.find({"author":"张三"})
或
db.blogs.find({"author":{"$eq":"张三"}})
4、查询除了作者为“张三”的博客(!=操作)
db.blogs.find({"author":{"$ne":"张三"}})
5、查询作者为“李四”并且博客标题为“MongoDB简介”的博客(and操作)
db.blogs.find({"author":"张三","title":"MongoDB简介"})
6、查询阅读量大于等于200并且小于1000的博客(>=操作)
db.blogs.find({"readCount":{"$gte":200,"$lt":1000}})
注:“$lt”,“$lte”,“$gt”,“$gte”分别对应<,<=,>,>=操作
7、查询作者为“张三”或者“李四”的博客(or操作)
db.blogs.find({"$or":[{"author":"张三"},{"author":"李四"}]})
8、查询博客标签包含了“NoSQL”或者“数学”的博客(in操作)
db.blogs.find({"tags":{"$in":["NoSQL","数学"]}})
注:not in操作
db.blogs.find({"tags":{"$nin":["NoSQL","数学"]}}) //不包含
9、查询标签为空的博客(null操作)
db.blogs.find({"tags":null})
注:null不仅会匹配到某个键为null的文档,也会匹配不包含这个键的文档
10、查询内容里边包含了数字“1”的博客
db.blogs.find({"content":/1/})
注:只要符合常规正则表达式的,都能被MongoDB接受
数组操作
11、查询标签里边既包含“story”,又包含了“rule”的博客
db.blogs.find({"tags":{"$all":["story","rule"]}})
12、查询第一个标签是“MongoDB”的博客
db.blogs.find({"tags.0":"MongoDB"})
注:数组的下标是从0开始的
13、查询标签个数为3个的博客
db.blogs.find({"tags":{"$size":3}})
内嵌文档
14、查询“jack”评论过的博客
db.blogs.find({"comment.name":"Jack"})
注:因为内嵌文档“.”的问题,所以不能使用URL等
15、假设每页2篇博客,按阅读量倒序,取第二页的数据
db.blogs.find({}).skip(2).limit(2).sort({"readCount":-1})
注:skip()、limit()、sort(),分别表示略过文档的数量,匹配的数量和排序(1表示正序,-1表示倒序)

















 996
996

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









