






公众号关注 「奇妙的 Linux 世界」
设为「星标」,每天带你玩转 Linux !

什么是 Istio?
Istio 是一个服务网格,它允许在集群中的 pods 和服务之间进行更详细、复杂和可观察的通信。
它通过使用 CRD 扩展 Kubernetes API 来进行管理。它将代理容器注入到所有 Pods 中,然后由这些 Pods 控制集群中的流量。
Kubernetes Services
从这里开始,您应该已经了解了 Kubernetes Services,可以阅读 本系列的第 1 部分。我们现在将简短地探讨如何实现 Kubernetes Services。我认为这有助于理解 Istio 如何做相同和不同的事情。
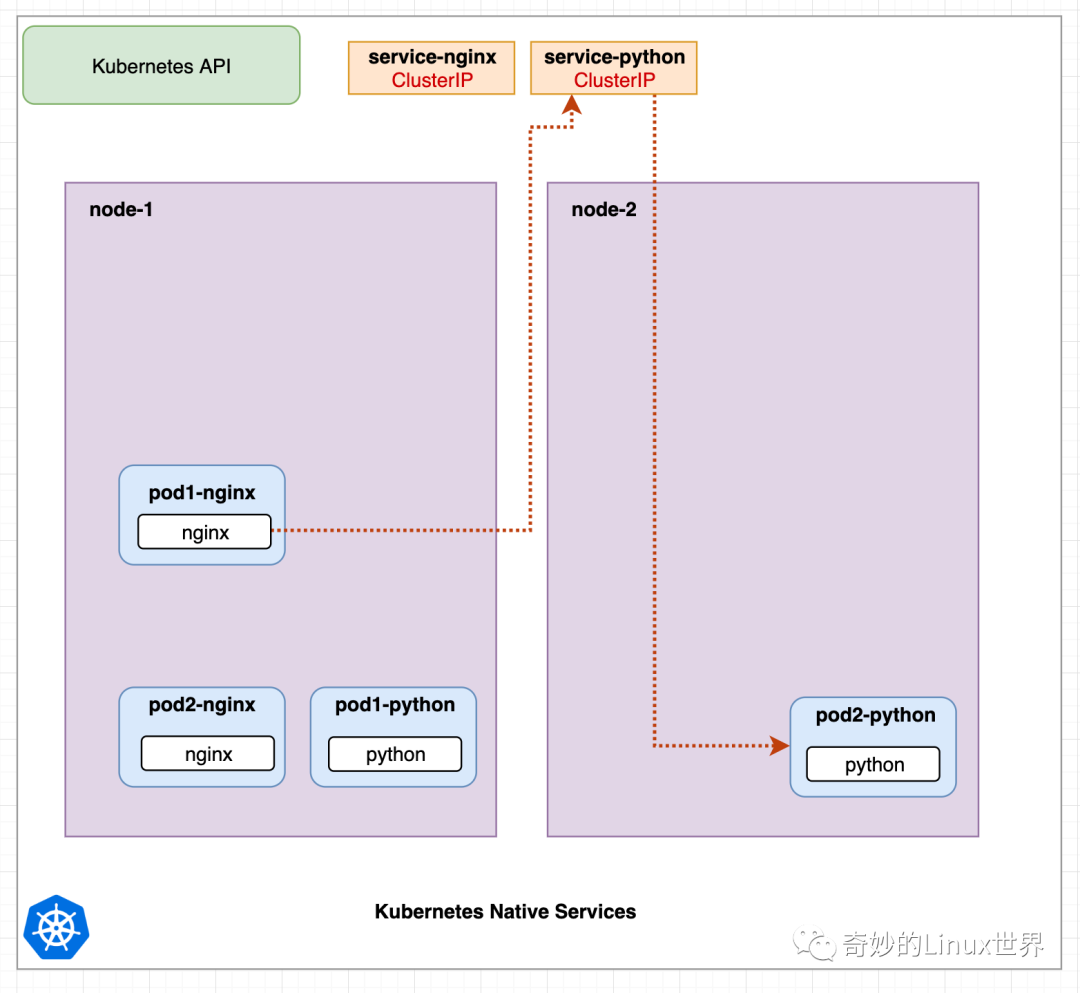
图 1 显示了一个 Kubernetes 集群,该集群有两个节点和 4 个 Pod,每个 Pod 都有一个容器。服务 service-nginx 指向 Nginx Pods,服务 service-python 指向 Python Pods。红线显示了从 pod1-nginx 中的 nginx 容器向 service-python 服务发出的请求,该服务将请求重定向到 pod2-python。
默认情况下,ClusterIP 服务执行简单的随机或循环分发。Kubernetes 中的 Services 并不存在于特定的节点上,而是存在于整个集群中。我们可以在图 2 中看到更多细节:
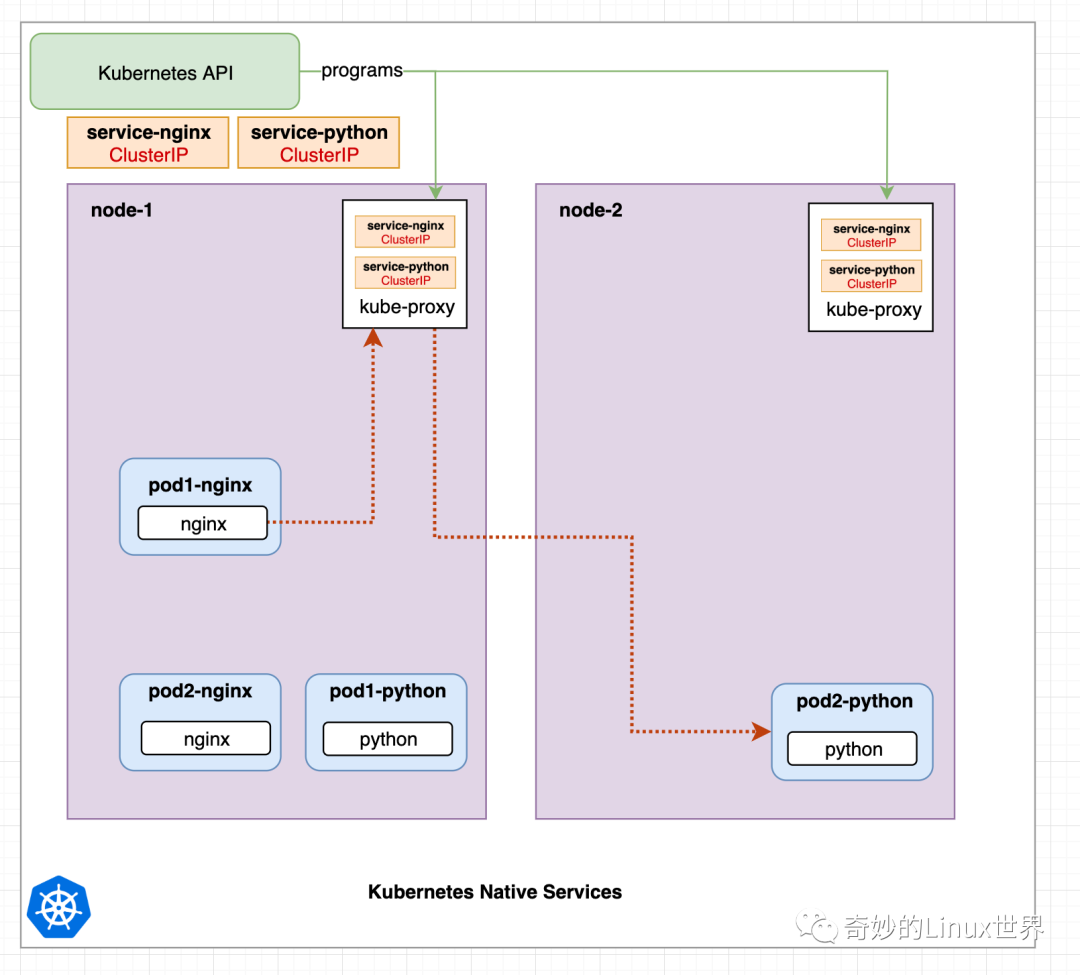
图 2 显示了与图 1 相同的示例,只是更详细一些。Kubernetes 中的服务是由运行在每个节点上的 Kube-proxy 组件实现的。该组件创建 Iptables 规则,并将请求重定向到 Pod。因此,服务就是 Iptables 规则。(还有其他不使用 Iptables 的代理模式,但过程是相同的。)
在图 2 中,我们看到 Kubernetes API 对每个 Kube-proxy 进行编程。每当服务配置或服务的 Pods 发生更改时,就会发生这种情况。通过这种方式,Kubernetes API (以及整个主节点或控制平面)可能会崩溃,但服务仍然可以工作。
Kubernetes Istio
现在我们来看一个配置了 Istio 的相同示例:
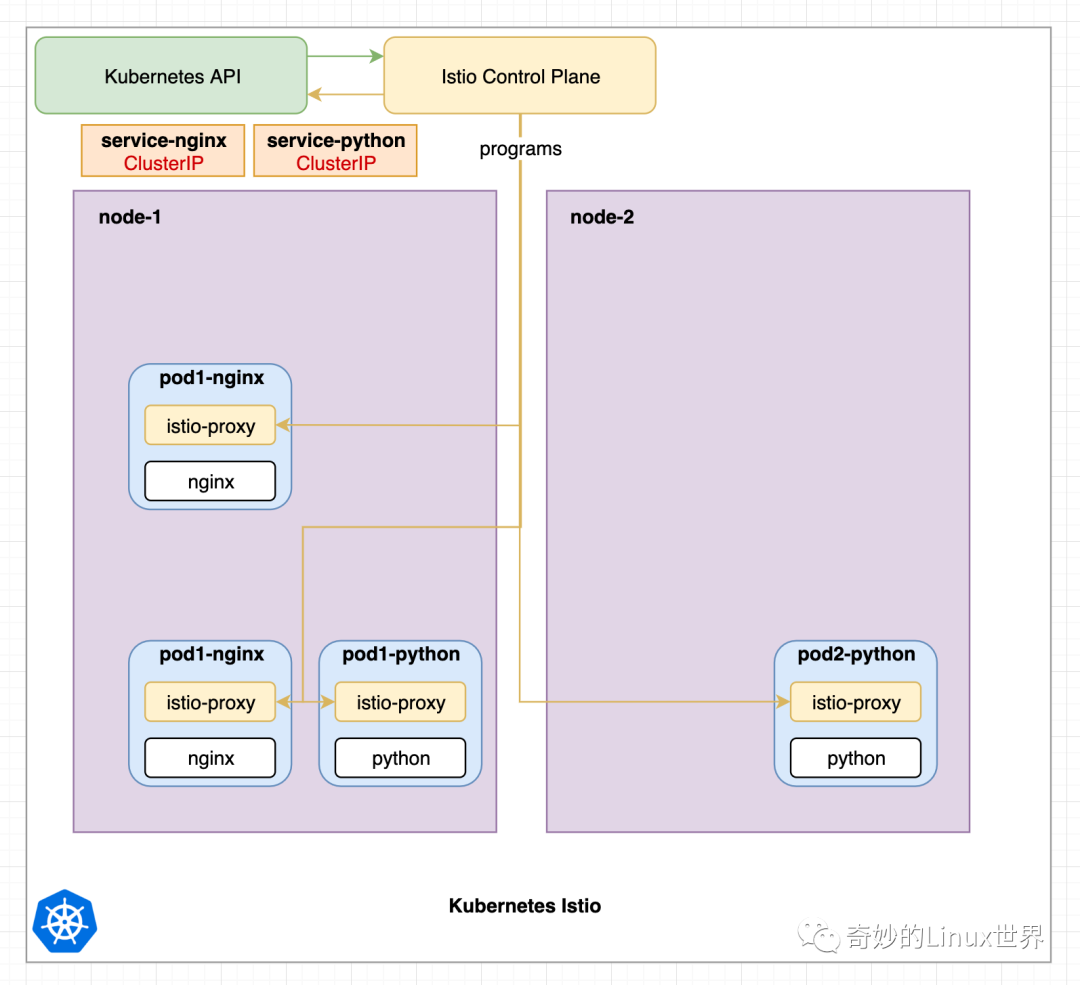
图 3 显示安装了 Istio,它随 Istio 控制平面一起提供。还常见的是,每个 Pod 都有第二个称为 istio-proxy 的容器,该容器在创建期间自动将其注入到 Pods 中。
Istio 最常见的代理是具有惊人能力的 Envoy。虽然可以使用其他代理(如 Nginx),这就是为什么我们从现在开始只将代理称为 Istio-Proxy。
我们可以看到不再显示 Kube-Proxy 组件,这样做是为了保持图像的整洁。这些组件仍然存在,但是拥有 Istio-Proxy 的 Pods 将不再使用 Kube-Proxy 组件。
每当配置或服务发生变化时,Istio 控制平面就会对所有 Istio-Proxy Sidecars 进行编程。类似于图 2 中 Kubernetes API 编程所有 Kube-Proxy 组件的方式。Istio 控制平面使用现有的 Kubernetes 服务来接收每个服务点所指向的所有 Pods 。通过使用 Pod IP 地址,Istio 实现了自己的路由。
在 Istio 控制平面对所有 Istio-Proxy Sidecars 编程之后,它看起来是这样的:
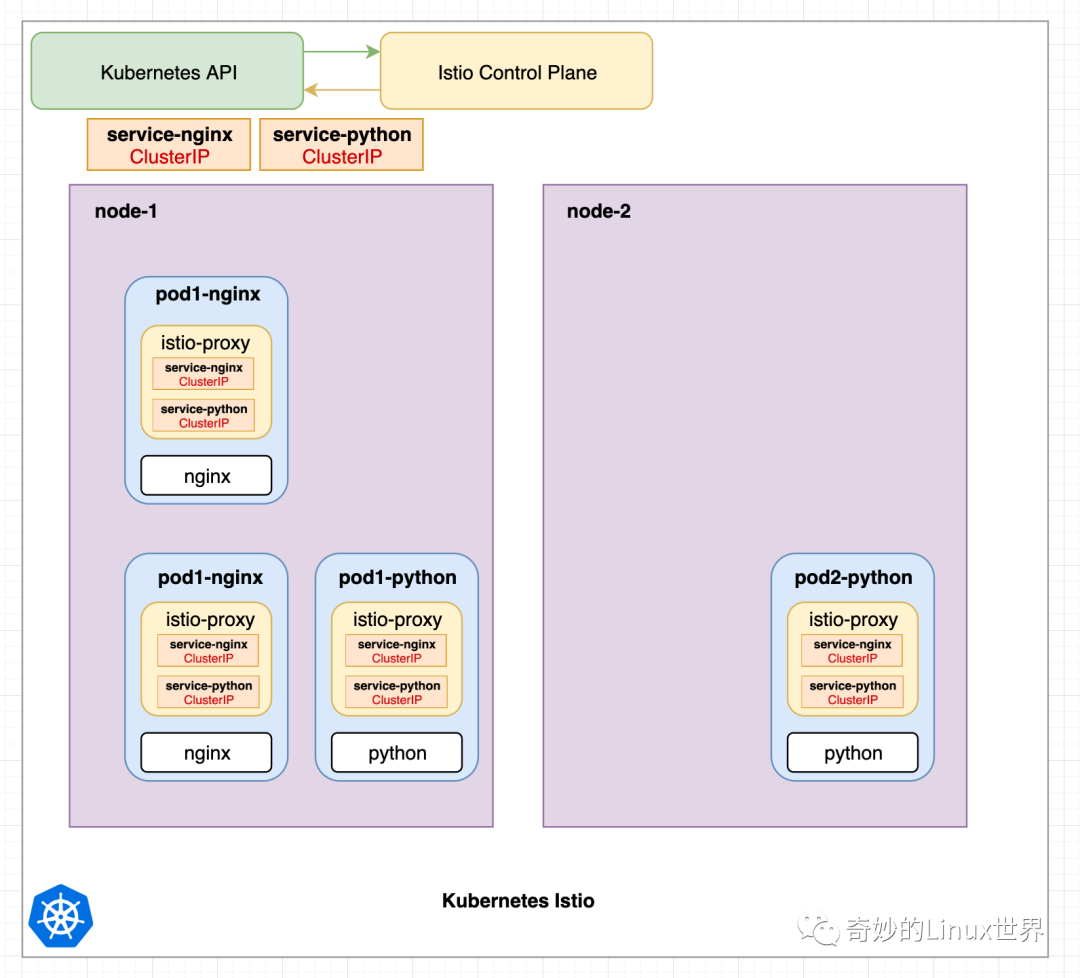
在图 4 中,我们看到 Istio 控制平面如何将当前配置应用到集群中的所有 Istio-Proxy 容器。为了简单起见,还包括 “ClusterIP” 声明。虽然 ClusterIP 是 Kubernetes 的内部服务类型。Istio 将把 Kubernetes 服务声明转换成它自己的路由声明。但是想象一下图像中显示的情况会很有帮助。
让我们看看如何使用 Istio 发出请求:
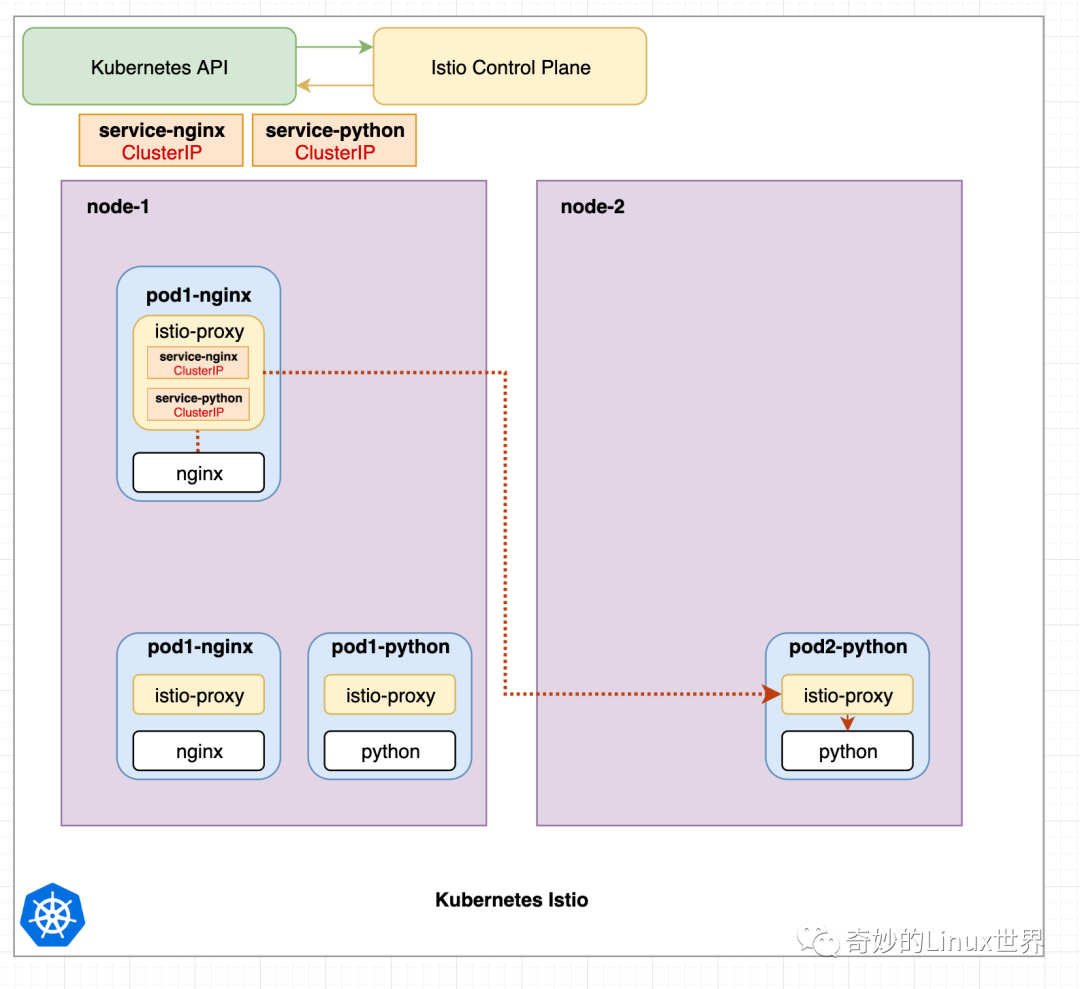
在图 5 中,所有的 Istio-Proxy 容器已经被 Istio 控制平面编程,并包含所有必要的路由信息,如图 3/4 所示。来自 Pod1-nginx 的 Nginx 容器向 Service-Python 发出请求。
请求被 Pod1-Nginx 的 Istio-Proxy 容器拦截,并被重定向到一个 Python Pod 的 Istio-proxy 容器,该容器随后将请求重定向到 Python 容器。
这里发生了什么?
图 1-5 显示了使用 Nginx 和 Python Pod 的 Kubernetes 应用程序的相同示例。我们已经看到了使用默认的 Kubernetes 服务和使用 Istio 是如何发生请求的。
重要的是: 无论使用什么方法,结果都是相同的,并且不需要更改应用程序本身,只需要更改基础结构代码。
为什么要这样,为什么要使用 Istio?
如果在使用 Istio 的时候没有什么变化(Nginx Pod 仍然可以像以前一样连接到 Python Pod),为什么要首先使用 Istio 呢?
其惊人的优势是, 现在所有流量都通过每个 Pod 中的 Istio-Proxy 容器进行路由。每当 Istio-Proxy 接收并重定向一个请求时,它还会将有关该请求的信息提交给 Istio 控制平面。
因此 Istio 控制平面可以准确地知道该请求来自哪个 Pod、存在哪些 HTTP 头、从一个 Istio-Proxy 到另一个 Istio-Proxy 的请求需要多长时间等等。在具有许多彼此通信的服务的群集中,这可以提高可观察性并更好地控制所有流量。
先进的路由
Kubernetes 内部 Services 只能对 Pods 执行轮询或随机分发请求。使用 Istio 可以实现更复杂的方式。比如,如果发生错误,根据请求头进行重定向,或者重定向到最少使用的服务。
部署
它允许将一定比例的流量路由到特定的服务版本,因此允许绿色/蓝色和金丝雀部署。
加密
可以对 Pods 之间从 Istio-Proxy 到 Istio-Proxy 的集群内部通信进行加密。
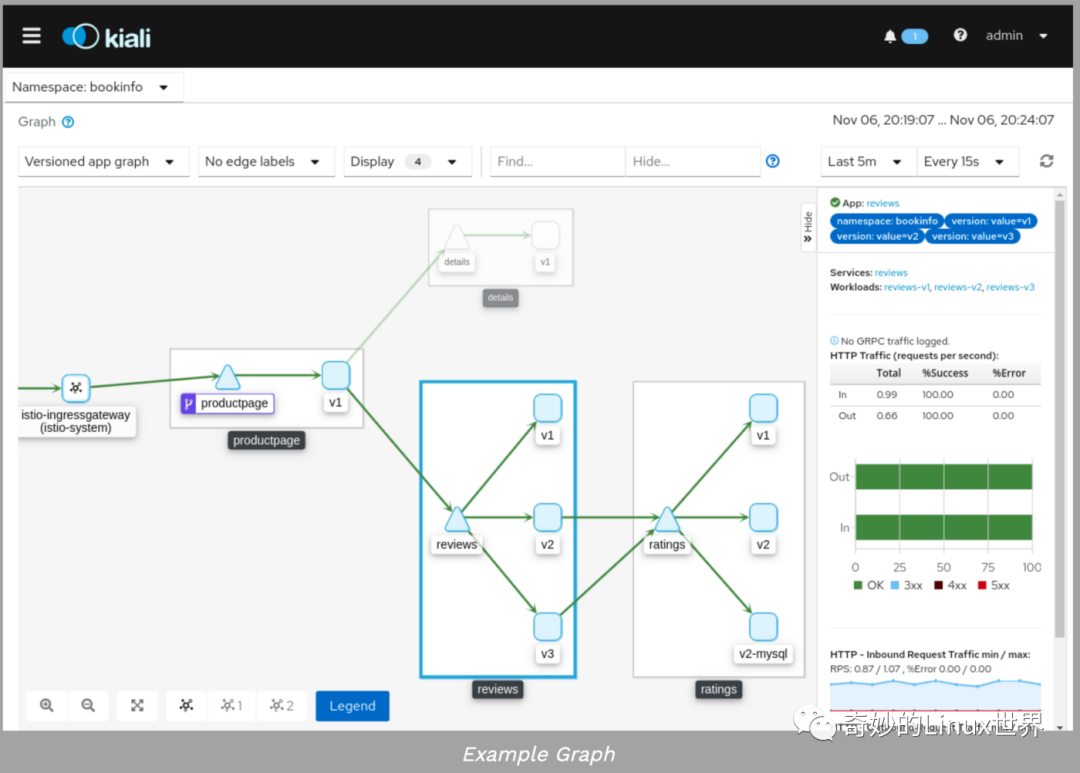
监控/图形生成
Istio 连接到 Prometheus 等监控工具。它也可以与 Kiali 一起很好的显示所有的服务和它们的流量。
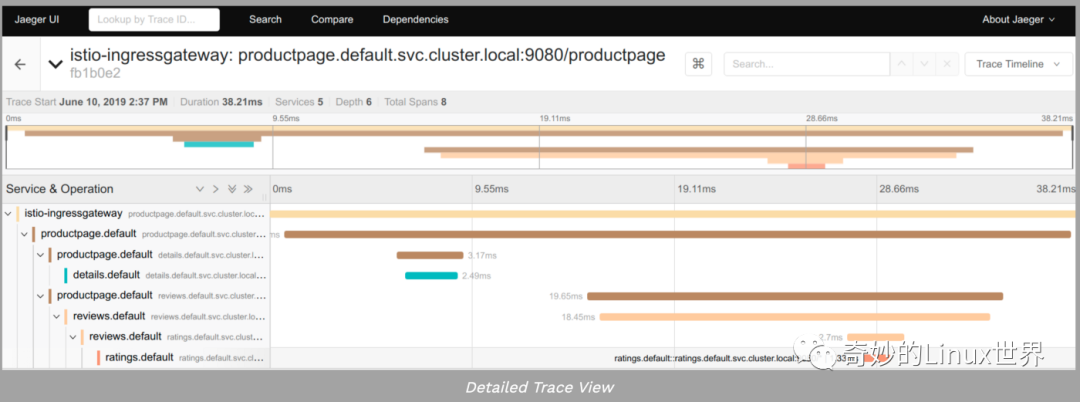
追踪
因为 Istio 控制平面拥有大量关于请求的数据,所以可以使用 Jaeger 等工具跟踪和检查这些数据。
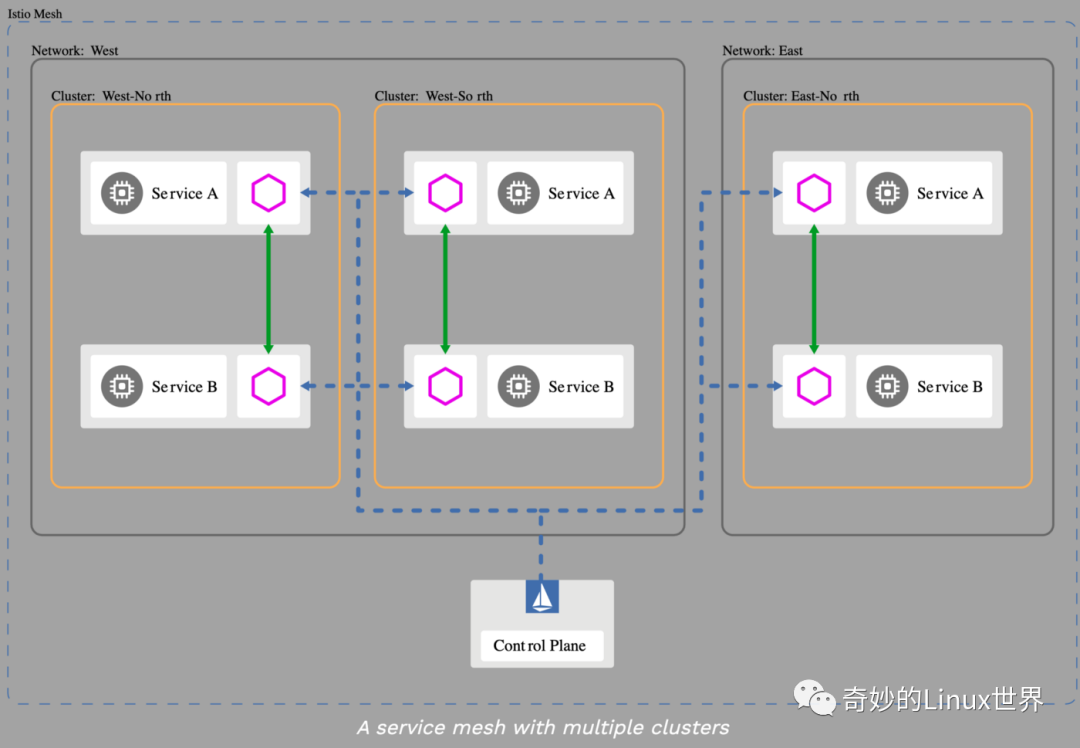
多集群 Mesh
Istio 有一个内部服务注册中心,它可以使用现有的 Kubernetes 服务。但是也可以从集群外部添加资源,甚至将不同的集群连接到一个网格中。
Sidecar 注入
为了使 Istio 工作,每一个作为网状结构一部分的 Pod 都需要注入 Istio-Proxy Sidecar。这可以在 Pod 创建期间为整个名称空间自动完成(通过 Admission Controller 钩子,也可以手动完成)。
Istio 会取代 Kubernetes 的服务吗?
不。当我开始使用 Istio 时,我问自己的一个问题是它是否会取代现有的 Kubernetes 服务。答案是否定的。Istio 使用现有的 Kubernetes 服务获取它们的所有 Endpoints/Pod IP 地址。
Istio 取代了 Kubernetes 的 Ingress 吗?
是的。Istio 提供了新的资源,比如网关和虚拟服务,甚至还附带了 Ingress 转换器 istioctl convert-ingress。一个很好的来源是: https://istio.io/docs/concepts/traffic-management
图 6 显示了 Istio 网关如何处理进入流量。网关本身也是一个 Istio-Proxy 组件。
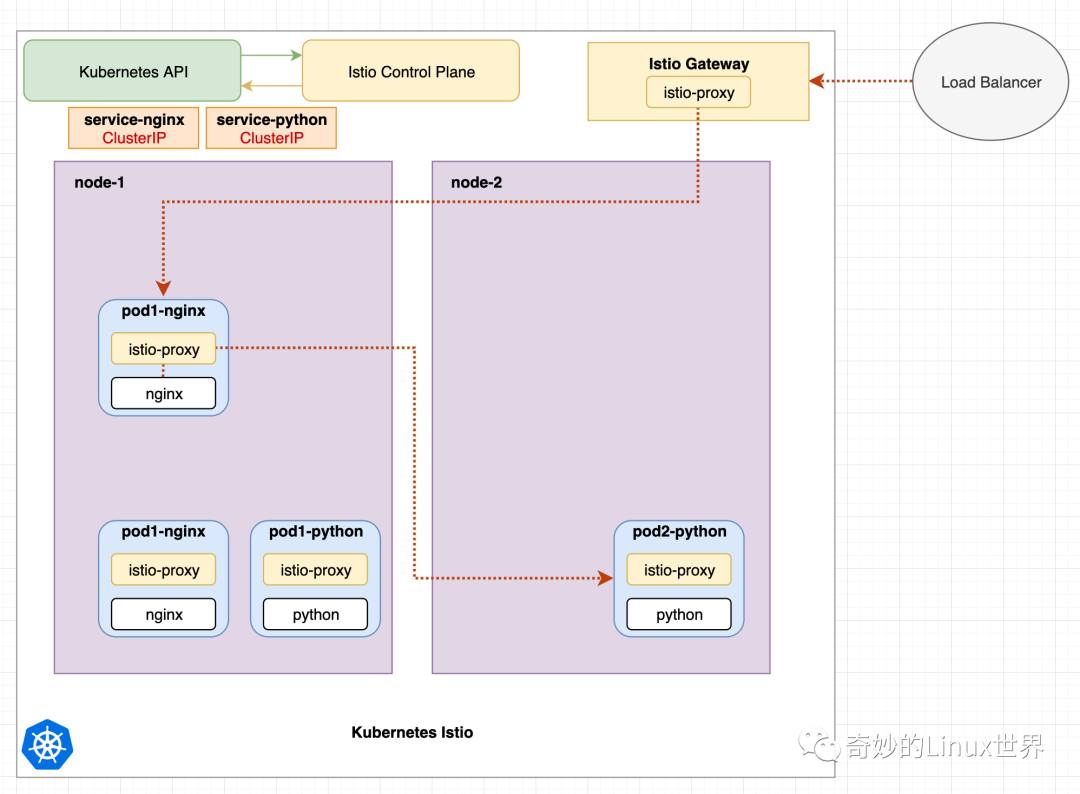
控制平面组件
Istio 控制平面由几个较小的部件组成,如 Pilot、Mixer、Citadel 和 Galley。如果您想深入研究,我建议您访问 https://istio.io/docs/ops/deployment/architecture
如果 Istio 控制平面关闭会发生什么?
因为所有的 Istio-Proxy Sidecar 都已经编程好了,所以 Istio 的控制平面可以关闭,流量也会像以前一样工作。但是配置更新或新创建的 Pods 不会被应用。
但对于高级路由,如将流量发送到使用最少的 Pod 或策略(https://istio.io/docs/tasks/policy-enforcement),所有 Istio-proxys 之间需要通过 Istio 控制平面进行通信。然后,在允许请求之前,每个 Istio-proxy 都需要检查 Istio 控制平面。
为了使这些配置正常工作,我认为控制平面必须始终可用。
下一步你能做什么?
我写了一篇关于 Istio Canray 部署的示例文章。
Istio 提供了一个很好的示例应用程序和一些微服务。如果你喜欢进入 Istio,这是一个很好的开始方法:https://istio.io/docs/setup/getting-started
如果你想更深入地研究,?这段视频也是很棒的。
回顾
这是一个简单的介绍和广泛的概述,我希望对你有所帮助。Istio 无疑在 Kubernetes 之上又增加了另一层次的复杂性。尽管对于现代微服务架构来说,它实际上提供了一种比必须在应用程序代码本身中实现跟踪或可观察性更简单的方法。
原文链接:https://itnext.io/kubernetes-istio-simply-visually-explained-58a7d158b83f
本文转载自:「CloudNative 架构」,原文:https://tinyurl.com/y565jom7,版权归原作者所有。欢迎投稿,投稿邮箱: editor@hi-linux.com。


你可能还喜欢
点击下方图片即可阅读

13 张图带你学懂 Kubernetes Service

点击上方图片,打开小程序,加入「玩转 Linux」圈子

更多有趣的互联网新鲜事,关注「奇妙的互联网」视频号全了解!


















 1937
1937

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









