






公众号关注 「奇妙的 Linux 世界」
设为「星标」,每天带你玩转 Linux !

Kubernetes 彻底火了,这把开源之火烧到了所有互联网大厂。许多分析机构认为,以 Kubernetes 为基础的云原生架构,很可能是云计算下一个十年发展的关键。
船长在容器编排方面从业数年,借着这股东风,给大家讲讲 Kubernetes 一个很重要的自动伸缩组件,也是目前社区比较火热的一个项目:Kubernetes Event-Driven Autoscaling (KEDA),中文名叫 Kubernetes 基于事件驱动的自动伸缩。这个名字好长有没有,咱业内将其简称为 KEDA。
1. 既生瑜何生亮

Kubernetes 本身自带了一个自动伸缩组件:Horizontal Pod Autoscaler (HPA)。为什么有了 HPA,还非得要 KEDA 呢?主要是 HPA 这哥们天生有缺陷,无法基于灵活的事件源进行伸缩:
01:
例如在基于事件驱动或 Serverless 架构的开发系统中,最常见的用例之一是根据 Queue/Topic 中的消息数量而不是 CPU 或内存来扩展 Workload。公司领导的要求是:在消息计数增加时向外扩展 Queue/Topic 的实例数量;在消息计数减少时缩减实例,咱得省钱!HPA 没这个功能,你说气不气!
02:
HPA 无法将 Pod 的实例数缩到零,也无法从零伸到一。不干活儿,还要占资源,找打!
03:
HPA 的每种指标收集器只能配置一个,还需添加指标转换器让 HPA 识别指标。虽然社区也提供了相应的转换组件,但是会导致调用链路拉长,同时也增加了响应延时和排错的复杂性。而使用 KEDA 立马改观,可以大大简化这一流程。
KEDA 是一个单一用途的轻量级组件,轻巧简单,可以添加到任何 Kubernetes 集群中,适配范围很广。
KEDA 很友好,不会让 HPA 下岗,其实现方式不是取代上位,而是扩展和增强 HPA 的功能。KEDA 允许用户使用 External Metrics 来定义任何事件源(例如 Kafka topic 滞后、Azure 队列长度或 Prometheus 查询指标)的自动伸缩,具有以下亮点:
1、支持伸缩到零
2、基于事件驱动
3、安装和配置简单,开箱即用
4、内置多种 Scaler
5、支持多种 Workload
6、支持 Azure Functions
2. KEDA 具体干啥?

Deployment 或 StatefulSet 伸缩
KEDA 可以根据触发器来自动伸缩 ScaledObject 中定义的 Deployment 或 StatefulSet。KEDA 负责监控事件源,并将数据反馈给 Kubernetes 和 HPA 进行资源的伸缩。KEDA 和 Deployment/StatefulSet 可以根据事件进行伸缩,同时也保留了事件源的丰富信息。
自定义资源伸缩
KEDA 可以自动伸缩任何自定义资源(例如 ArgoRollout 资源)的工作负载。缩放的方式与 Deployment 或 StatefulSet 的缩放方式相同。唯一的限制是,目标自定义资源必须定义 /scale 子资源。
Job 伸缩
KEDA 可以根据事件触发器和 ScaledJob 中设置的信息生成对应的 Kubernetes Job,从而处理 ScaledJob 定义的工作负载。
Scaler 认证
可以在 ScaledObject/ScaledJob 的清单文件中引用 TriggerAuthentication 或 ClusterTriggerAuthentication 增加监视事件源的认证。

点击上方图片,打开小程序,『美团外卖』红包天天免费领!
3. 组件与原理
下图为 KEDA 的工作原理图。
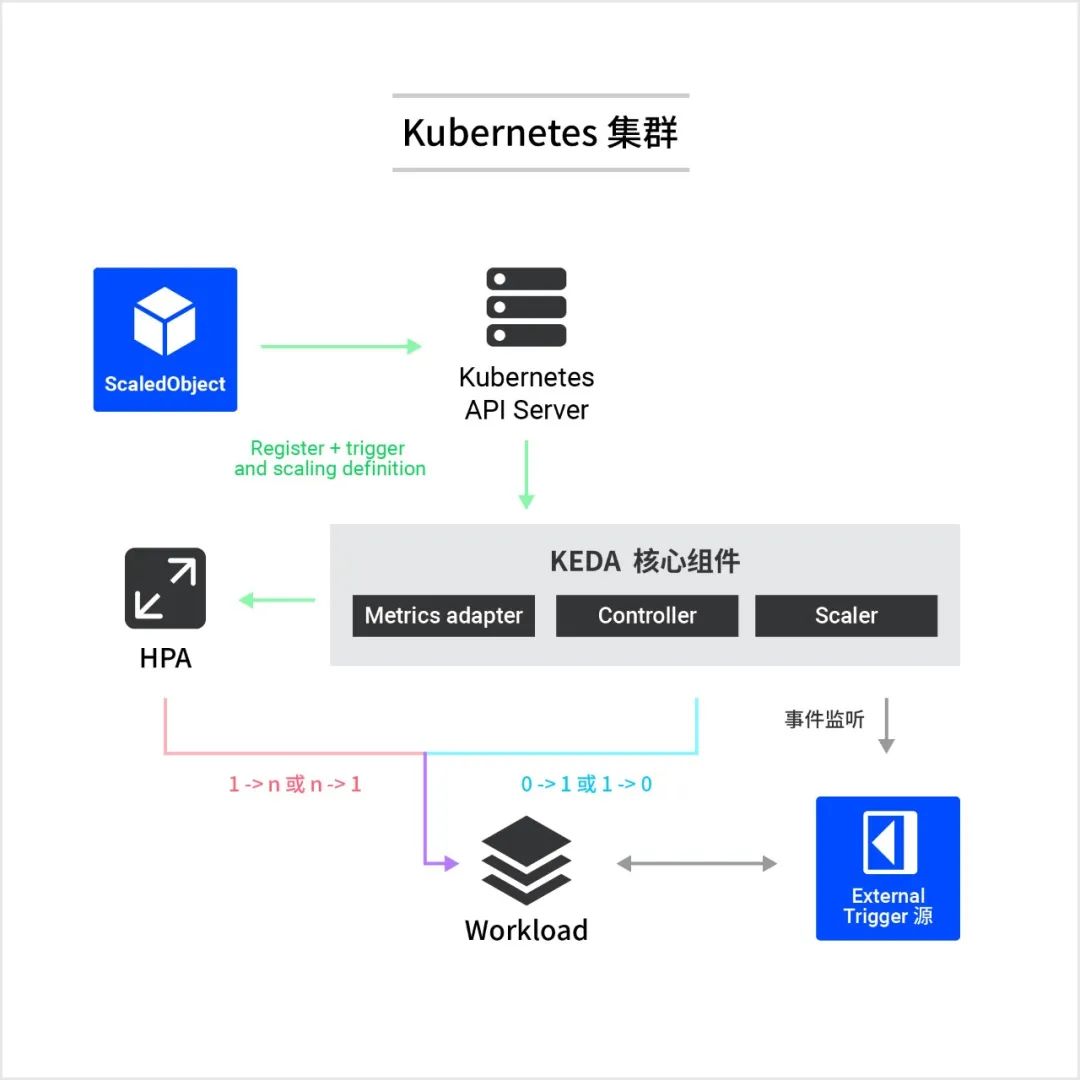
KEDA 核心组件有三个:
Metrics Adapter
将 Scaler 获取的指标转化成 HPA 可以使用的格式并传递给 HPAController
负责创建和更新一个 HPA 对象,并负责扩缩到零Scaler
连接到外部组件(例如 Prometheus)获取指标
3.1. Metrics Adapter
KEDA Metrics Adapter 实现并充当外部指标的服务器。准确地说,它实现了 Kubernetes 外部指标 API 并充当“适配器”,将来自外部的指标转换为 HPA 可以理解和使用的形式,从而驱动自动伸缩过程。
3.2. Controller
KEDA Controller 是一个控制器,它实现了一个 “Reconcile loop”,并充当一个 Agent 来激活和停用 Deployment 以便从零扩展。这是安装 KEDA 时运行的 keda-operator 容器的主要作用,它通过创建 HPA 对资源的创建做出反应 。KEDA 负责将 Deployment 从零扩展到一个实例,也可以将其缩减到零,而 HPA 负责 Deployment 从 KEDA 操作后的状态开始自动伸缩。
3.3. Scaler
Scaler 类型在 ScaledObject 的清单文件中进行定义。它集成了外部源或在 ScaledObject 中定义的触发器,能够获取所需的指标并将其传递给 KEDA 指标服务器。KEDA 内部集成了多个 Scaler,您可以使用可插拔接口添加其他 Scaler 或外部度量
源。
KEDA Scaler 包括:
Apache Kafka:基于 Kafka topic lag
Redis:基于 Redis 列表的长度
Prometheus:基于 PromQL 查询的结果
KEDA 主页上提供了当前支持的所有 Scaler 列表。
「🔗 KEDA 主页:https://keda.sh/#scalers」
4. 代码用例

🔗 图片来源:https://commons.wikimedia.org/wiki/File:LinuxCon_Europe_Linus_Torvalds_05.jpg
安装 KEDA
添加 Helm Repo
helm repo add kedacore https://kedacore.github.io/charts更新 Helm Repo
helm repo update安装
KEDAHelm chart
kubectl create namespace keda
helm install keda kedacore/keda --namespace keda创建一个 Deployment
apiVersion: apps/v1kind: Deploymentmetadata: name: httpserverspec: replicas: 1 selector: matchLabels: app: httpserver template: metadata: labels: app: httpserver spec: containers: - name: httpserver image: httpserver # 镜像需自己编写,并暴露对应的指标 imagePullPolicy: Always---apiVersion: v1kind: Servicemetadata: name: httpserver labels: app: httpserver annotations: # prometheus 服务发现规则 prometheus.io/scrape: "true" prometheus.io/path: "/metrics" prometheus.io/port: "http"spec: type: ClusterIP ports: - port: 80 protocol: TCP name: http selector: app: httpserver创建一个 ScaledObject
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: prometheus-scaledobject
namespace: default
spec:
scaleTargetRef:
name: httpserver # ScaledObject 绑定的 Deployment 名字
pollingInterval: 20 # 检查每个触发器的时间间隔
minReplicaCount: 1 # 最小副本数,可以缩小到零
maxReplicaCount: 10 # 最大副本数
triggers:
- type: prometheus # 使用的事件源
metadata: # 触发器的属性
serverAddress: http://promethes_ur1:port/
metricName: httpserver_requests_total
threshold: '1'
query: sum(rate(httpserver_requests_total[1m]))
authenticationRef:
name: promethes-auth-secret # 用于事件源身份验证完成上述操作后,KEDA 将开始从 Prometheus 中查询信息和并控制对应 Deployment 进行自动伸缩。
5. KEDA 社区
2019 年 5 月 Microsoft 和 Red Hat 共同发起了 KEDA 项目,该项目旨在简化应用程序的自动伸缩。用户只需创建 ScaledObject 或 ScaledJob 定义想要伸缩的对象和要使用的触发器,支持缩减到零 (scale-to-zero)。
KEDA 在 2020 年 3 月成为 CNCF 沙盒项目。自从成为沙盒项目以来,KEDA 用户数量大幅增长,这些用户主要来自 Alibaba、CastAI、KPMG、Meltwater、Microsoft 等公司。目前 KEDA 已经从 CNCF 的沙箱项目升级为孵化项目。
KEDA 的开源代码仓库地址为 https://github.com/kedacore/keda,目前已获得 3600 多颗 Star,超过 100 位贡献者。KEDA 主要由 Microsoft、Red Hat 和 Codit 这三个组织的 4 名维护人员进行维护。如果您有兴趣为 KEDA 的发展方向做出贡献或参与 KEDA 开发,欢迎加入 KEDA 的社区会议。
本文转载自:「道客船长」,原文:https://tinyurl.com/4dsjf428,版权归原作者所有。欢迎投稿,投稿邮箱: editor@hi-linux.com。


你可能还喜欢
点击下方图片即可阅读
Linux 技能不再是第一需求?Linux 基金会 2021 最新开源工作报告:云原生市场需求成最热
点击上方图片,『美团|饿了么』外卖红包天天免费领

更多有趣的互联网新鲜事,关注「奇妙的互联网」视频号全了解!















 1170
1170











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









