






公众号关注 「奇妙的 Linux 世界」
设为「星标」,每天带你玩转 Linux !

随着Kubernetes 1.25关于cgroup v2 特性的正式发布(GA), kubelet容器资源管理能力得到加强。本文针对K8s迁移cgroup v2做了如下的checklist,主要分为:cgroup v2是什么,对于K8s意味着什么以及如何迁移等相关内容。

“简介”
Pod资源管理
Kubernetes通过配置Pod中容器的request和limit来设置资源请求和限制(声明式),其中request字段描述了Pod应该拥有的资源量,而limit字段描述了Pod可以使用的最大限度,例如CPU资源中request对于的cpu.shares,limit对应的cpu.cfs_period_us 和cpu.cfs_quota_us,主要原理是Linux的CFS调度算法,cgroups 可以限制、记录、隔离进程组所使用的物理资源(包括:CPU、memory、IO 等),为容器实现虚拟化提供了基本保证,其是容器运行时管理工具的底层技术。
apiVersion: v1
kind: Pod
metadata:
name: nginx
spec:
containers:
- name: nginx
image: nginx:latest
resources:
requests:
memory: 128Mi
cpu: 250m
limits:
memory: 128Mi
cpu: 500mcgroup的接口以cgroupfs的虚拟文件系统方式进行公开,该文件系统通常挂载在/sys/fs/cgroup上,其主要提供资源限制、优先级分配、资源统计及进程控制等能力,其中关于资源统计,在K8s生态中,一般使用cAdvisor来收集与容器相关的监控指标,关于cgroup相关的内容可以参看kernel文档,后续会有两篇相关内容的具体介绍。
这里以一个Pod为例,其中一个容器配置了resources.limits.memory,通过kubectl get pod -o wide可以查看其是处于Pending还是已经调度至某一节点,接着SSH至调度节点,通过crictl ps查看其容器ID(crictl是K8s社区提供的CRI运行时的交互工具,关于CRI的相关内容可以参看Containerd深度剖析-CRI篇),最后输入crictl inspect查看其cgroup路径,示例中显示为/sys/fs/cgroup/kubepods.slice/kubepods-burstable.slice/kubepods-burstable-podf9a04ecc_1875_491b_926c_d2f64757704e.slice/cri-containerd-47e320f795efcec1ecf2001c3a09c95e3701ed87de8256837b70b10e23818251.scope,通过slice后缀可以知道kubelet以systemd方式启动,示例结果如下所示:
$ # This is an example for cgroup v2.
$ # Kubernetes translates resources.limits into cgroup parameters.
$ # Accessed from within a container
$ cd /sys/fs/cgroup
$ cat memory.max
134217728 # 128Mi
$ # cgroup.procs shows what processes it contains.
$ cat cgroup.procs
1 # container's main process
34 # sh
41 # cat
$ # It also delivers some measurements.
$ cat cpu.stat
usage_usec 106492566
user_usec 66687448
system_usec 39805118
nr_periods 0
nr_throttled 0
throttled_usec 0在探讨cgroup v2的优点之前,可以简要分析一下cgroup v1和v2有何不同。如下所示,v1对不同的资源类型使用不同的层次结构,关于v1中子系统跟层级相关概念,暂不做详细介绍。
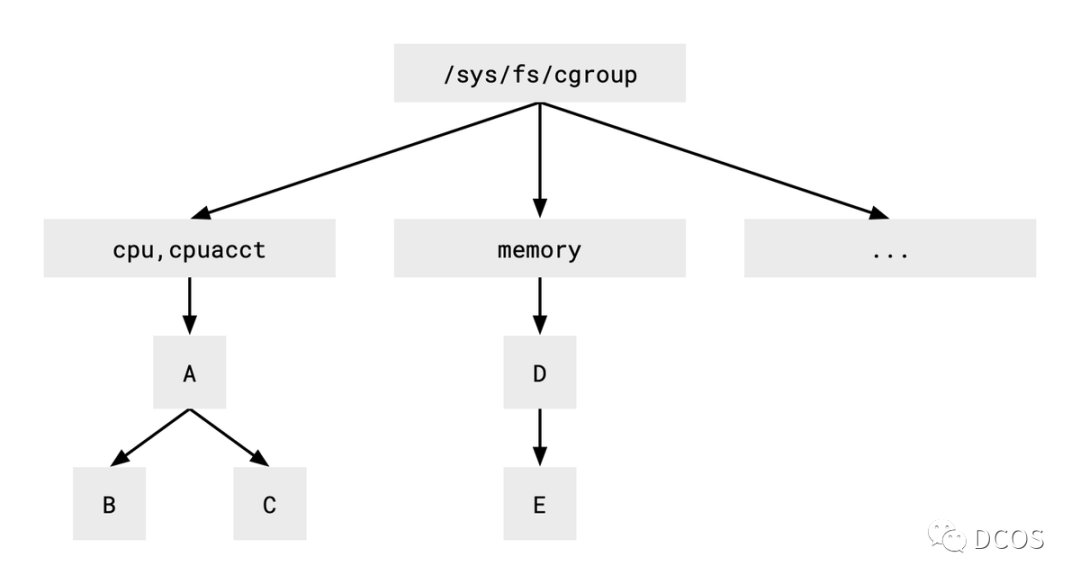
图中的每个框表示一个目录,由于CPU和内存的树是分开的,如果希望应用这两种资源类型的控制策略,就需要将一个进程同时放入这两个树中。例如,将相同的进程放入B组和E组,允许B组最多使用两核CPU,E组最多使用128MiB的内存。
但是v1的多层级在使用时会产生一些问题,cgroup v2使用统一的层次结构来避免上述问题。
cgroup v2
cgroup v2 是 Linux cgroup API 的最新版本, 自 2016 年以来,cgroup v2 一直在 Linux 内核中进行开发, 近年来随着容器生态的逐步推广,cgroup v2也随之逐渐成熟。在 Kubernetes 1.25 中, 对于 cgroup v2 的支持也变得水到渠成。
默认情况下,许多Linux 发行版已经默认支持 cgroup v2, cgroup v2 较 cgroup v1 有了多项增强,例如:
API 中单个统一的层次结构设计
为容器提供更安全的子树委派能力
全局inotify支持、容器级别OOM等
增强的资源分配管理和跨多个资源的隔离
统一管理不同类型的内存分配(网络和内核内存等)
考虑非即时资源变更,例如页面缓存回写
Kubernetes可以依托cgroup v2可以实现一系列亮眼的特性,例如:
容器级别的OOM
支持rootless
利用eBPF
cgroup v2可以支持容器级别的(但还没有实现)OOM而非某个进程。一个容器或Pod可以运行多个进程,以前OOM killer不考虑它们的整体性,只杀死其中的一些进程,这种方式可能导致Pod进入不一致的状态。cgroup v2接口允许我们判断特定cgroup中的进程是否相互依赖,从而确定是否应该同时关闭。
另一个使用场景是可以加强集群安全性。管理没有root权限的容器的技术称为rootless容器,其允许由受限用户运行Kubernetes节点组件(如kubelet),提高安全性,并允许非管理用户在共享机器上创建Kubernetes集群等。
最后,eBPF需要cgroup v2来启用它的所有功能,当前Cilium是一个依托eBPF技术实现cni插件的开源项目,它的一些功能需要使用cgroup v2,当启用cgroup v2时,可以替换kube-proxy。

“迁移”
如果决定采用cgroup v2,在此之前有三件事要做。
Linux OS
启用cgroup v2 具有以下要求:
操作系统发行版启用 cgroup v2
Linux 内核为 5.8 或更高版本
可以通过修改内核 cmdline 引导参数在你的 Linux 发行版上手动启用 cgroup v2。如果你的发行版使用 GRUB,则应在 /etc/default/grub 下的 GRUB_CMDLINE_LINUX 中添加 systemd.unified_cgroup_hierarchy=1, 然后执行 sudo update-grub。但还是推荐使用已默认启用 cgroup v2 的Linux发行版。
要检查发行版使用的是哪个 cgroup 版本,需要执行以下命令:
stat -fc %T /sys/fs/cgroup/对于 cgroup v2,输出为 cgroup2fs;对于 cgroup v1,输出为 tmpfs。
需要注意的是,cgroup v2还不支持实时进程,如果需要在系统上部署一些实时进程,应该将其放在root cgroup中。
这里介绍一个案例,在每个工作节点上运行bird和chrony,其作为实时进程,正常工作需要很小的延迟,我们将Docker服务以systemd方式启动,然后修改ExecStartPost指令将它们移动到根cgroup。
以下为示例配置,等待Docker启动容器,然后获取进程ID,并将其写入cgroup,最后使用chrt命令使bird成为一个实时进程。
ExecStart=/usr/bin/docker run --name bird ...
ExecStartPost=/bin/sh -c 'while ! docker container inspect bird >/dev/null; do sleep 1; done'
ExecStartPost=/bin/sh -c 'echo $(docker inspect bird | jq ".[0].State.Pid") > /sys/fs/cgroup/cgroup.procs'
ExecStartPost=/bin/sh -c 'chrt --pid --rr 50 $(docker inspect bird | jq ".[0].State.Pid")'K8s生态
在cgroup v2下,层次结构中的每个cgroup都由一个进程进行管理,在大多数情况下,systemd管理根cgroup并创建整个系统使用的层级。
配置kubelet使用systemd的cgroup管理Pod:
apiVersion: kubelet.config.k8s.io/v1beta1
kind: KubeletConfiguration
cgroupDriver: systemd其中如果选用Containerd作为容器引擎,那么cgroup配置如下:
[plugins."io.containerd.grpc.v1.cri".containerd.runtimes.runc]
[plugins."io.containerd.grpc.v1.cri".containerd.runtimes.runc.options]
SystemdCgroup = trueKubernetes官方文档提供了其他容器运行时关于cgroup的配置。
迁移之后,需要检查cgroup2文件系统是否正常启用,当然也可以通过运行测试Pod,通过设置资源限制,查看其值是否转换为相应的cgroup参数即可。
$ mount | grep cgroup
cgroup2 on /sys/fs/cgroup type cgroup2 (rw,nosuid,nodev,noexec,relatime,seclabel)
none on /run/cilium/cgroupv2 type cgroup2 (rw,relatime,seclabel)启用cgroup v2之后,如果前期使用cadvisor采集监控指标,那么需要使用合适的cAdvisor版本,因为cgroup接口从v1到v2,发生了重大变化。当前cAdvisor v0.43支持cgroup v2,但存在一个BUG,已经在v0.44中修复。
我们有以下选项来使用适当的cAdvisor版本:
1. 更新Kubernetes到v1.23,因为该版本的kubelet嵌入了cAdvisor v0.43。
2. 将最新的cAdvisor以DaemonSet方式部署,因为kubelet计划移除cAdvisor。
应用变更
Go
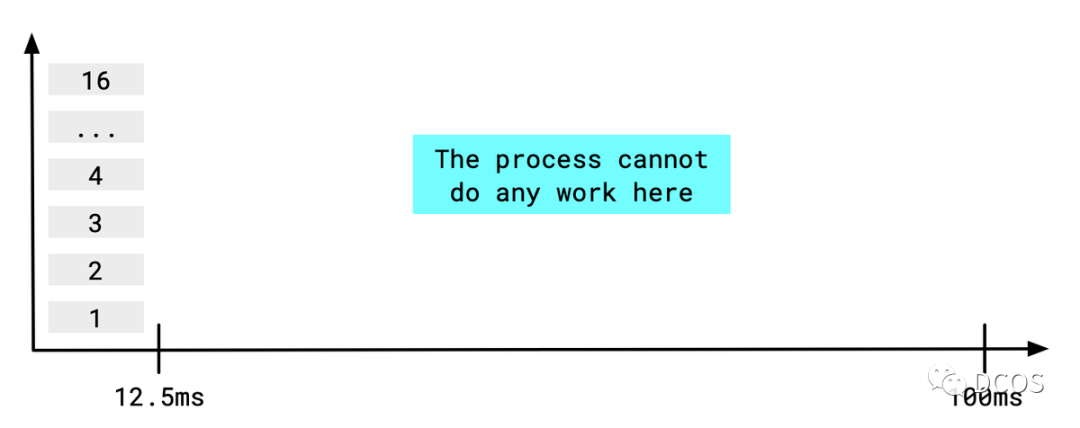
当想要限制容器的CPU(配额)时,可以配置Pod中容器的resources.limits.cpu字段,其意味着cgroup为容器中的进程在固定的时间周期内消耗一定量的CPU时间。时间周期通常为100ms(可配)。
如果容器中的一个进程运行16个线程(它应该决定这样做,因为主机有16个内核),它将在12.5ms内耗尽配额,那么容器中的进程在剩余的87.5ms内无法执行任何工作,并且可能会拒绝 readiness请求,因此需要告诉进程应该使用两个线程。
设置线程数的方法因程序的实现语言而定,对于Go程序,可以通过环境变量GOMAXPROCS设置为合适的数值,当然sautomaxprocs是一个比较实用的工具,其可从cgroup接口读取CPU配额并自动设置环境变量。如果正在使用v1.4.0之前的版本,则需要更新mod以支持cgroup v2功能。
Java
我们需要使用JDK 15或更高版本才能在启用了cgroup v2的系统中正常运行Java应用程序。JDK从版本8u131开始就支持容器环境,在JDK 10版本中引入了+UseContainerSupport选项,并默认启用了该选项。当使用该选项时,JDK检查cgroup文件系统以读取CPU和内存配额供应用使用,CPU配额信息可以通过Runtime.availableProcessors()获得。内存配额影响其堆内存使用。这种机制应该针对cgroup v2进行调整,JDK 15提供了相关的修复。
由于笔者时间、视野、认知有限,本文难免出现错误、疏漏等问题,期待各位读者朋友、业界专家指正交流。
参考文献
1. https://kubernetes.io/zh-cn/docs/concepts/architecture/cgroups
2. https://blog.kintone.io/entry/2022/03/08/170206#Two-things-to-prepare-for-workloads
3. https://www.infoq.cn/article/docker-kernel-knowledge-cgroups-resource-isolation
本文转载自:「DCOS」,原文:https://url.hi-linux.com/WOoUp,版权归原作者所有。欢迎投稿,投稿邮箱: editor@hi-linux.com。

最近,我们建立了一个技术交流微信群。目前群里已加入了不少行业内的大神,有兴趣的同学可以加入和我们一起交流技术,在 「奇妙的 Linux 世界」 公众号直接回复 「加群」 邀请你入群。

你可能还喜欢
点击下方图片即可阅读
探秘 Docker 容器化技术黑科技 Cgroups
点击上方图片,『美团|饿了么』外卖红包天天免费领

更多有趣的互联网新鲜事,关注「奇妙的互联网」视频号全了解!















 1145
1145











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









