







评测结果,如图所示:
*评测综合得分排名(图)|绿色(闭源),蓝色(开源)
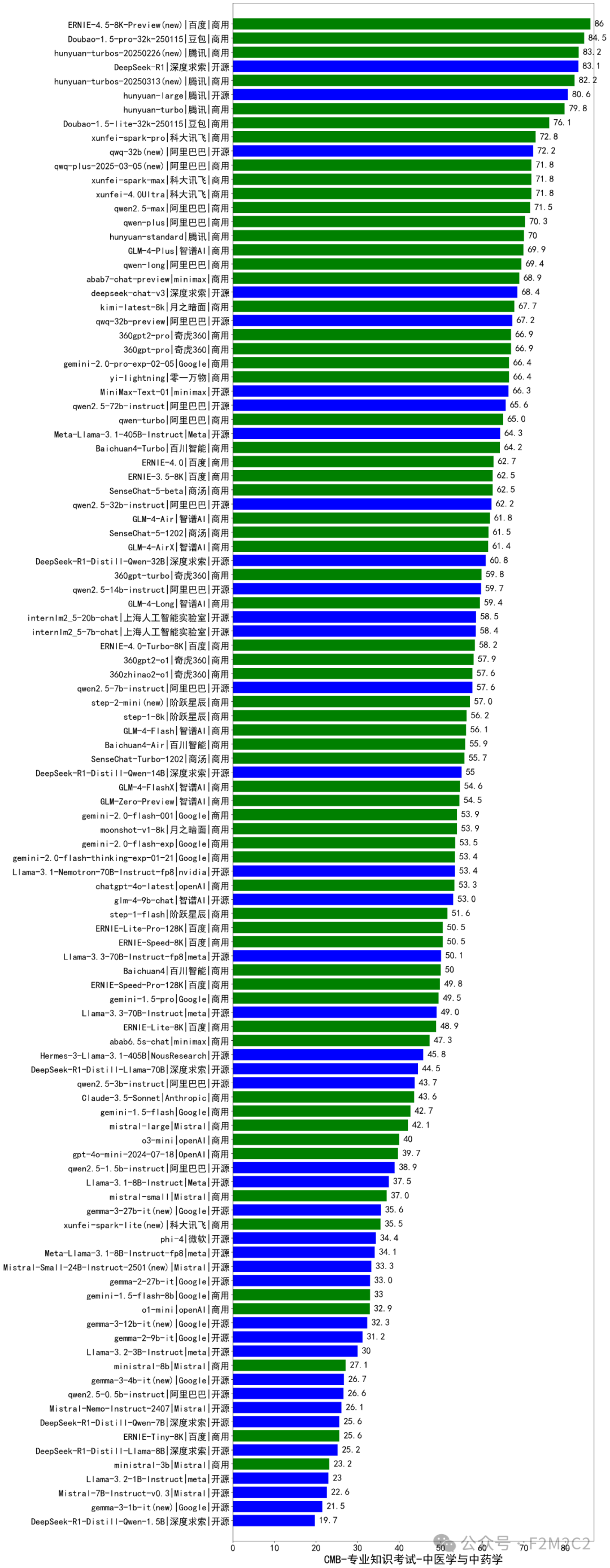
【评测结论】:百度系模型得分第一,豆包、腾讯系混元大模型、deepseek分列2-4名,,其中deepseek是前5中唯一一个开源模型。
各科目完整评测题集及结果详见:https://github.com/jeinlee1991/chinese-llm-benchmark
【模型数量】:110个大模型(国内外,开源、闭源的大模型)
【评测维度】:「专业知识考试-中医学与中药学」类目的11个专业细分领域的择题题集评测
-
中医眼科学
-
金匮要略讲义
-
中医基础理论
-
中医诊断学
-
中医学
-
温病学
-
中国医学史
-
中医内科学
-
中医儿科学
-
伤寒论
-
内经讲义
【错题集】:请前往以下链接查阅👇
各科目完整评测题集及结果详见:https://github.com/jeinlee1991/chinese-llm-benchmark
大模型评测EasyLLM,目前已就DeepSeek和各个大模型的不同能力维度进行了综合评测(详情可回顾以下链接👇),接下来还会针对大模型当律师、医生、老师等各个岗位角色进行测评,看看谁是各个垂直领域的最强打工人!宝子们看好哪个大模型可以在哪些岗位胜任最强牛马?或者想评测大模型的哪方面能力?评论区留言,有求必测,一一公布结果!有评测样本、有错题集、有图有真相!
往期文章
Llama/Qwen/DeepSeek开源之争——CLiB开源大模型排行榜03.04
那些免费的大模型API效果到底好不好?——CLiB大模型排行榜
关于大模型评测EasyLLM
-
首创——行业首创百万级AI大模型错题本
-
最全——全球最全大模型产品评测平台,已囊括203个大模型
-
最新——月更各个大模型各项能力指标评测,输出排行榜
-
最方便——无需注册/梯子,国内外各个大模型可一键评测
-
结果可见——所有大模型评测的方法、题集、过程、得分结果,可见可追溯!
大模型评测EasyLLM目前已囊括203个大模型,覆盖chatgpt、gpt-4o、o3-mini、谷歌gemini、Claude3.5、智谱GLM-Zero、文心一言、qwen-max、百川、讯飞星火、商汤senseChat、minimax等商用模型, 以及DeepSeek-R1、deepseek-v3、qwen2.5、llama3.3、phi-4、glm4、书生internLM2.5等开源大模型。不仅提供能力评分排行榜,也提供所有模型的原始输出结果,以及各个大模型不同维度、不同细分领域的评测错题本!
完整评测题集及结果详见:https://github.com/jeinlee1991/chinese-llm-benchmark



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









