







个人复习笔记Mark,图片内容大多来自老师提供ppt,感谢大数据课的陈老师、孙老师的辛苦授课~
目录
(2)分布式事务处理:事务读写的数据分布在不同机器上,代价昂贵
1 大数据背景与趋势
1.1 计算机硬件的发展
晶体管数量-摩尔定律,指数级增加
- CPU体系结构发展
- 2005年以前-提高主频,功耗、散热等限制主频的进一步增加
- 转向核的增加:单核单线->多核多线->众核
- 多种类型的处理器:GPU/ARM/…
- 存储层次结构
- 外存(硬盘、闪存)->DRAM内存->L3缓存->L2缓存->L1缓存->寄存器 =>速度快,容量低,价格高
- 内存:容量符合摩尔定律,带宽有一定的方法增加,访问速度比指令执行慢100倍
- 硬盘:容量指数级增加,性能(访问速度慢,带宽受限于盘片转速,顺序访问比随机访问好)
- 固态:以闪存为存储介质,随机读性能、顺序读写性能优于机械,但随机写性能差
1.2 数据管理系统的发展
- 关系型数据库(1970-1980)
- 第一个关系型数据库:System R
- 事务处理(Transaction Processing)
- 大量并发用户,少量随机读写操作
- 典型:银行业务,订票,购物等
- 数据仓库:读取大量数据的分析操作 1990
- 数据流处理、GIS、多媒体数据库等 2000
- 大数据 2010
1.3 大数据的挑战
- 三个重要概念&挑战
- 数据量巨大 Volume
- 数据的产生速度、更新速度快 Velocity
- 数据种类繁多 Variety
1.4 大数据管理系统

2 关系型数据管理系统
2.1 关系型数据模型
(1)Table/Relation (表)
- Column 列
- 一个属性,有明确的数据类型
- 必须是原子类型,不可再分,无内部结构
- Row 行
- 一个记录,记录之间无序
- 表型瘦长,列数较少,行数成千上万
- 原子类型:无内部嵌套结构
- Int,Double,Char…及Int基础上表达类型(Date等)
- 数学定义
- Schema vs Instance
- Schema:类型,只需定义一次
- Instance:具体取值,每列具体值

(2)Key(键)
- 特殊的列
- 用处:取值唯一,唯一确定一个记录
- Primary Key:主键,唯一确定本表中的一个纪录(例如学生信息表的ID,选课信息表中学生ID和课程ID的组合)
- Foreign Key:外键,是另一个表的主键,唯一确定另一个表的一个记录(例如选课信息表的学生ID和课程ID),可理解为指针或引用
2.2 关系型运算 & SQL语言
SQL:主流的关系型数据库语言
- 一般运算
- SQL Create Table +声明主键、外键


- SQL Insert
- 插入完整记录
- 插入特定列
- 插入完整记录
- SQL Delete


- SQL Update

- 主要关系运算
- Selection 选择
- 从一个表中提取一些行

- Projection 投影
- 从一个表中提取一些列
- Selection 选择
|
|
=>SQL 选择+投影
|
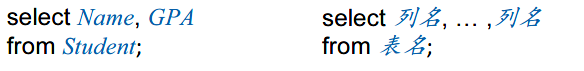

- Join 连接(等值连接 Equi-join)
- R表中的a列与S表中的b列,找到两个表中互相匹配的记录

- Group by 分组统计
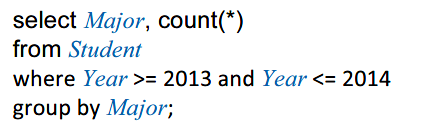
![]()
- Having 在group by基础上选择
- Order by 排序
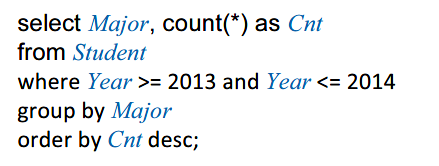
- desc (descending 减少)表示从大到小排序;asc (ascending 增加) 表示从小到大排序
- 如何计算平均成绩?
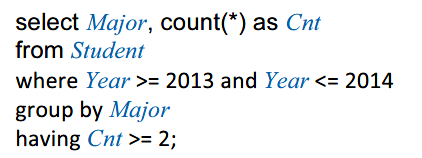
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









