







一、git基本使用
git是LINUX创始人为适应分布式源码管理的需求而开发的源码管理工具。在这里先介绍git的本地管理,然后再介绍如何把工作成果push到服务器端。
git本地文件有四种状态:untracked、unmodified、modified和staged。
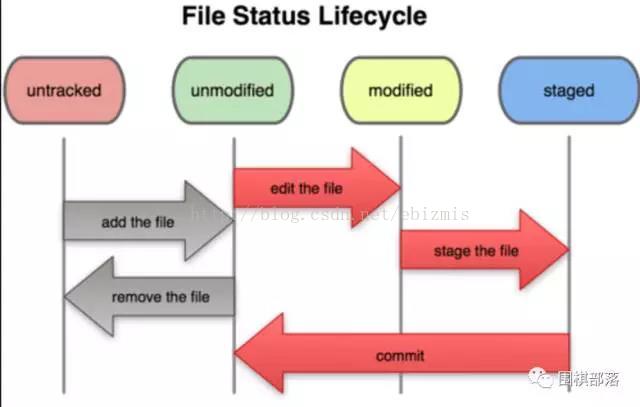
untracked:没有加入到git本地库管理的文件,可以通过git add命令加入;
unmodified:没有被修改的文件;
modified:修改了内容的文件;
staged:等待commit
本地库主要使用命令:
1)初始化本地库
进入相应的源码目录,执行git init。
2) 往本地库里加文件
git add <filename>
增加后的文件状态为staged,可以commit后转到unmodified状态。
3) 提交文件
git commit -m "comments for modifying"
4) 创建branch
git branch dev
创建一个新的分支,并指向此branch
5) 切换branch
git checkout master
6) 查看log
git log --oneline --graph
7) 查看status
git status -s
与github同步:
1)上传源码到github
git push -u https://github.com/xxx/xxx.git
在MacOS中第一次输入用户名和密码后会记住。
2)下载源码
git clone https://github.com/xxx/xxx.git
git是分布式的源码管理工具,如果需要集中管理和严格授权,还是建议使用svn。
二、python
python是一种解释性执行高级编程语言。使用者众多,涉及各行业,在各行业累积运行良好的程序包,达到了众人拾柴火焰高的良性循环状态。python已经成为应用研究和工作即时使用的重要工具。python推荐安装anaconda版本,集成了jupter notebook等其他工具。
1) 数据类型
数字类型:
x = 3
print(type(x)) # Prints "<class 'int'>"
print(x) # Prints "3"
print(x + 1) # Addition; prints "4"
print(x - 1) # Subtraction; prints "2"
print(x * 2) # Multiplication; prints "6"
print(x ** 2) # Exponentiation; prints "9"
x += 1print(x) # Prints "4"
x *= 2print(x) # Prints "8"
y = 2.5print(type(y)) # Prints "<class 'float'>"
print(y, y + 1, y * 2, y ** 2) # Prints "2.5 3.5 5.0 6.25"
布尔类型:
t = True
f = False
print(type(t)) # Prints "<class 'bool'>"
print(t and f) # Logical AND; prints "False"
print(t or f) # Logical OR; prints "True"
print(not t) # Logical NOT; prints "False"
print(t != f) # Logical XOR; prints "True"
字符类型:
hello = 'hello' # String literals can use single quotes
world = "world" # or double quotes; it does not matter.
print(hello) # Prints "hello"
print(len(hello)) # String length; prints "5"
hw = hello + ' ' + world # String concatenation
print(hw) # prints "hello world"
hw12 = '%s %s %d' % (hello, world, 12)
print(hw12) # prints "hello world 12"
列表类型:
xs = [3, 1, 2] # Create a list
print(xs, xs[2]) # Prints "[3, 1, 2] 2"
print(xs[-1]) # prints "2"
xs[2] = 'foo' # Lists can contain elements of different types
print(xs) # Prints "[3, 1, 'foo']"
xs.append('bar')
print(xs) # Prints "[3, 1, 'foo', 'bar']"
x = xs.pop() # Remove and return the last
print(x, xs) # Prints "bar [3, 1, 'foo']" 字典类型:
d = {'cat': 'cute', 'dog': 'furry'}
print(d['cat']) # prints "cute"
print('cat' in d) # prints "True"
d['fish'] = 'wet' # Set an entry in a dictionary
print(d['fish']) # Prints "wet"# print(d['monkey'])
print(d.get('monkey', 'N/A')) # prints "N/A"
print(d.get('fish', 'N/A')) # prints "wet"
del d['fish']
print(d.get('fish', 'N/A')) # prints "N/A"
集合类型:
animals = {'cat', 'dog'}print('fish' in animals) # prints "False"
print('cat' in animals)
animals.add('fish') # Add an element to a set
print('fish' in animals) # Prints "True"
print(len(animals)) # Number of elements in a set; prints "3"
animals.add('cat')
print(len(animals)) # Prints "3"
animals.remove('cat') # Remove an element from a set
print(len(animals)) # Prints "2"
2) 语句
循环语句:
animals = ['cat', 'dog', 'monkey']
for animal in animals:
print(animal)# Prints "cat", "dog", "monkey" if判断语句:
if x > 0:
str = 'positive'
elif x < 0:
str = 'negative'
else:
str = 'zero' 函数:
def hello(name, loud=False):
if loud:
print('HELLO, %s!' % name.upper())
else:
print('Hello, %s' % name)
hello('Bob')
hello('Fred', loud=True) # Prints "HELLO, FRED!" 类:
class Greeter(object):
# Constructor
def __init__(self, name):
self.name = name # Create an instance variable
# Instance method
def greet(self, loud=False):
if loud:
print('HELLO, %s!' % self.name.upper())
else:
print('Hello, %s' % self.name)
g = Greeter('Fred')
g.greet()
g.greet(loud=True)
三、Python第三方库
1)Numpy
矩阵:
import numpy as np
a = np.array([1, 2, 3]) # Create a rank 1 array
print(type(a)) # Prints "<class 'numpy.ndarray'>"
print(a[0], a[1], a[2]) # Prints "1 2 3"
a[0] = 5
print(a) # Prints "[5, 2, 3]"
b = np.array([[1,2,3],[4,5,6]]) # 矩阵2*3
print(b[0, 0], b[0, 1], b[1, 0]) # Prints "1 2 4"
import numpy as np
a = np.zeros((2,2)) # Create an array of all zeros
print(a) # Prints "[[ 0. 0.]
# [ 0. 0.]]"
b = np.ones((1,2)) # Create an array of all ones
print(b) # Prints "[[ 1. 1.]]"
c = np.full((2,2), 7) # Create a constant array
print(c) # Prints "[[ 7. 7.]
# [ 7. 7.]]"
d = np.eye(2) # Create a 2x2 identity matrix
print(d) # Prints "[[ 1. 0.]
# [ 0. 1.]]"
e = np.random.random((2,2))
print(e) # Might print "[[ 0.91940167 0.08143941]
# [ 0.68744134 0.87236687]]"
import numpy as np
# Create the following rank 2 array with shape (3, 4)
# [[ 1 2 3 4]
# [ 5 6 7 8]
# [ 9 10 11 12]]
a = np.array([[1,2,3,4], [5,6,7,8], [9,10,11,12]])
b = a[:2, 1:3]
print(a[0, 1]) # Prints "2"
b[0, 0] = 77
print(a[0, 1]) # Prints "77"
矩阵运算:
import numpy as np
x = np.array([[1,2],[3,4]], dtype=np.float64)
y = np.array([[5,6],[7,8]], dtype=np.float64)
# [[ 6.0 8.0]
# [10.0 12.0]]
print(x + y)
print(np.add(x, y))
print(x - y)
print(np.subtract(x, y))
print(x * y)
print(np.multiply(x, y))
print(x / y)
print(np.divide(x, y))
print(np.sqrt(x))
2) SciPy 图像操作
from scipy.misc import imread, imsave, imresize
img = imread('assets/cat.jpg')
print(img.dtype, img.shape)
# Prints "uint8 (400, 248, 3)"
img_tinted = img * [1, 0.95, 0.9]
img_tinted = imresize(img_tinted, (300, 300))
imsave('assets/cat_tinted.jpg', img_tinted)
四、两点距离
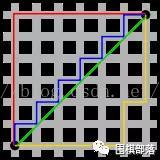
1)Manhattan距离
指两点之间x方向和y方向位移绝对值之和,如下图:
2)Euclidean距离
即欧几里得距离,两点之间的直线距离。设两点 A(x1,y1)、B(x2,y2),则距离为:
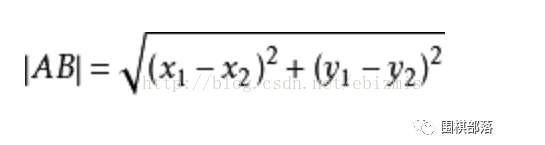
五、分类和回归
分类是根据输入样本,推断它所对应的类别,一般是用整数代表分类;回归是根据输入样本推断它所对应的输出实数值是多少。也就是使用y=g(x)来推断任一输入x所对应的输出实数值。分类和回归,一个是推断整数,另外一个是推断实数,本质是一样的。
六、一些概念及数学符号
1)合计

j从0到3,表示m0+m1+m2+m3。

i从0到3,同时j也从0到3,表示m0*n0+m0*n1+m0*n2+m0*n3+m1*n0+m1*n1+m1*n2+m1*n3+m2*n0+m2*n1+m2*n2+m2*n3+m3*n0+m3*n1+m3*n2+m3*n3。
2)拟合
所谓拟合是指已知某函数的若干离散函数值{f1,f2,…,fn},通过调整该函数中若干待定系数f(λ1, λ2,…,λn),使得该函数与已知点集的差别(最小二乘意义)最小。如果拟合出来的函数是线性,就叫线性拟合或者线性回归,否则叫作非线性拟合或者非线性回归。
3)过拟合
为了得到一致假设而使假设变得过度严格称为过拟合。避免过拟合是分类器设计中的一个核心任务。通常采用增大数据量和测试样本集的方法对分类器性能进行评价。也可以这样说,在训练的过程中,教过的都会,没教过的都不会。















 519
519











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









