






一.数据库基础
(一)数据库概念
数据库分类
关系型(用表格存储):MySql , qlServer, Orcle
非关系型(多用键值对存储):Redis,Mongodb
数据库管理系统(DBMS)
用于管理和操作数据库的大型软件,能建立,使用和维护数据库,对数据库进行统一管理和控制,以保证数据库的安全性和完整性。用户通过数据库管理系统访问数据库中表内的数据。
数据库管理系统与数据库,数据表的关系
数据库管理系统管理着多个数据库,一个数据库管理着多张数据表,一张表里面有很多数据
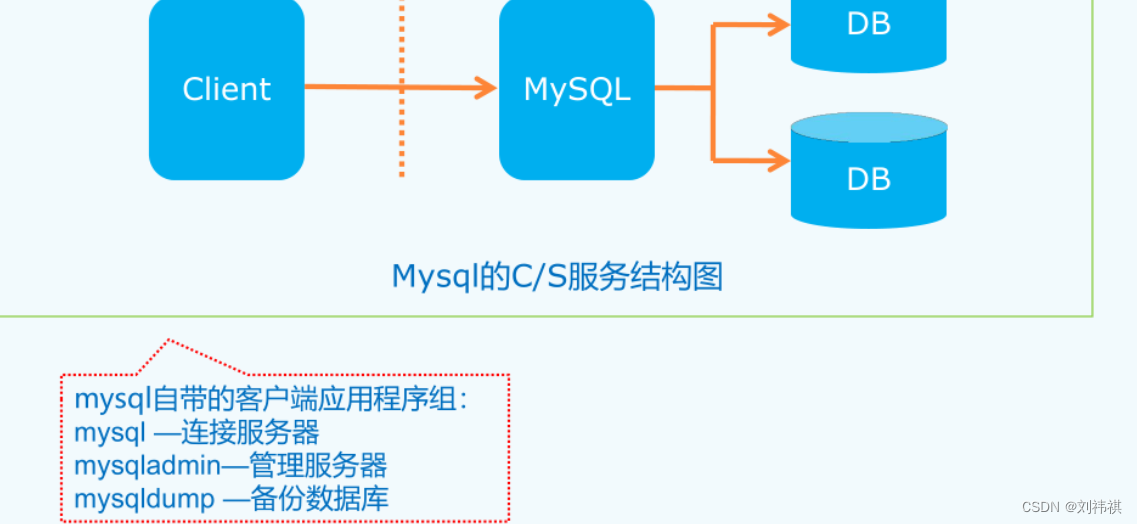
(二)mysql简介
关系型数据库;
以表格形式存储数据;
一个数据库中包含多张表;
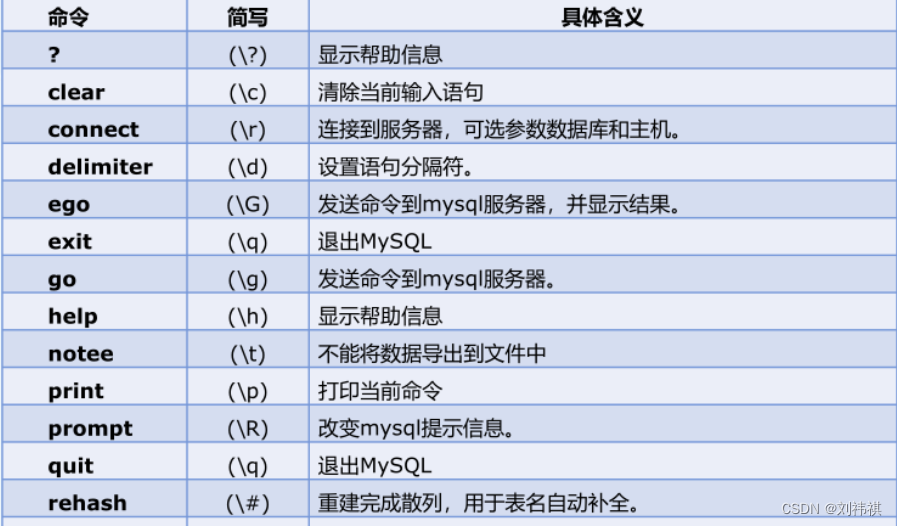

(三)基本术语
主键:主键是唯一标识;一个数据表只有一个主键;可以使用主键查询数
据。
外键:用于关联两张表。
复合键:复合键(组合键)将多个列作为一个索引键,一般用于复合索引。
索引:索引是对数据库表中一列或多列的值进行排序的一种结构,使用索引可以提高查找效率。
(四)数据类型:
数值类型:
INT/INTEGER:4 Bytes
FLOAT : 4 Bytes
DOUBLE: 8 Bytes
日期类型:
DATE :日期类型,XXXX年XX月XX日
添加默认时间类型的配置:CURRENT_TIMESTAMP
字符串类型:
CHAR:定长字符串,长度一般是0~255
VARCHAR:可变长字符串

(五)命名规则
数据库命名:
英文字母大小写,数字或者下划线;
表命名:
英文字母大小写,数字或者下划线;禁止使用关键字
字段命名:
与表命名类似
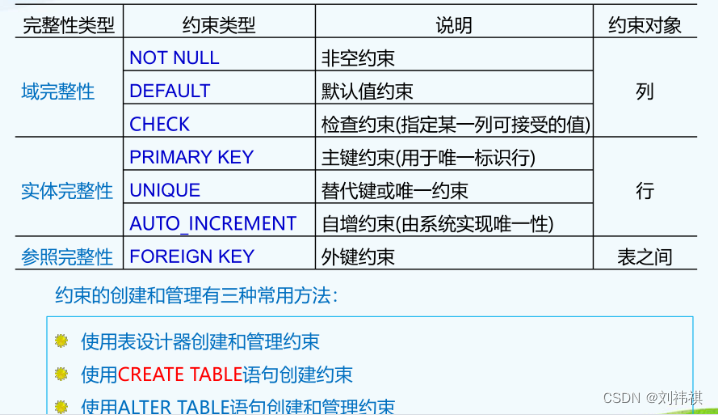
(六)数据库的约束
对表中数据进行限制,保证数据正确性,有效性,完整性
约束种类:
主键约束:
唯一标识数据库中每一条数据(id字段类似身份证)
创建:用关键字primary key
PRIMARY KEY (字段名称) --设置主键
特点:不重复,不为Null(所以通常设置为自动递增)
字段名称 字段类型(长度) AUTO_INCREMENT --设置自动递增
后续添加主键:
alter table 表名 add primary key (字段名称);
删除主键:
alter table 表名 drop primary key;
唯一约束:
表中某一列不能出现重复的值。
格式:字段名称 字段类型 UNIQUE
设置唯一约束
ALTER TABLE 表名 ADD UNIQUE KEY(字段名);
ALTER TABLE 表名 MODIFY 字段名 字段类型 UNIQUE;
非空约束:
表中某一列不为空
格式:字段名称 字段类型 NOT NULL
id INT(10) NOT NULL;
外键:
外键:在从表中与主表主键对应的那一列,如:用户表中的 roleid。
主表:用来约束别人的表,一方
从表(副表):被别人约束的表,多方
建表时添加外键
语法格式:[CONSTRAINT] [外键约束名称] FOREIGN KEY(外键字段名) REFERENCES 主表名(主键字段名);
CREATE TABLE if NOT EXISTS user_c(
id int(11) PRIMARY KEY auto_increment,
username VARCHAR(22),
password VARCHAR(255),
roleid int(11) NOT NULL,-- 外键对应着主表的主键
constraint roleid_fk foreign key (roleid) references rolelist(roleid)
)
已有表添加外键
ALTER TABLE 从表名称 ADD CONSTRAINT 外键名称 FOREIGN KEY (从表外键字段) REFERENCES 主表名称(主表主键);
删除外键
alter table 表名称 drop foreign key 外键名称;
外键级联
ON UPDATE TRUNCATE:级联更新,更新主表的主键,从表的外键也会同步更新
ON DELETE TRUNCATE:级联删除,删除从表中的与主表对应的数据,主表相应的数据也会被删除
外键删除与修改
CASCADE:父表delete、update的时候,子表会delete、update掉关联记录;
SET NULL:父表delete、update的时候,子表会将关联记录的外键字段所在列设为null,所以注意在设计子表时外键不能设为not null;
RESTRICT:如果想要删除父表的记录时,而在子表中有关联该父表的记录,则不允许删除父表中的记录;
NO ACTION:同 RESTRICT,也是首先先检查外键;
当创建外键约束之后,如果两个字段相互RESTRICT关联,这个时候想删除子表中被约束的数据,(例如:用户表中某用户的角色id为4,这个时候想删除这个角色表中的id为4的角色,直接删除就会出错,必须先删除用户表中被约束的数据,再去删除角色表中的数据)
默认值
id INT(10) NOT NULL DEFAULT 0;
二.数据库查询语句
(一)Mysql语法
每一条SQL语句都是以分号(英文状态)结束,但是在Navicat中是可以不加分号的;
SQL中是不区分大小写,关键字中认为大小写一样;
注释:单行注释:--空格 多行注释:/* */
进入数据库:mysql -u root -p 密码
反引号``用于表名和字段名
字段是char 或者varchar时,插入值最好用单引号''


(二)数据库函数
标量函数
UCASE() - 将某个字段转换为大写
SELECT UCASE(username) FROM `user`
LCASE() - 将某个字段转换为小写
MID(字段,开始,长度) - 从某个文本字段提取字符
LENGTH() - 返回某个文本字段的长度
SELECT LENGTH(username) FROM `user`
ROUND() - 对某个数值字段进行指定小数位数的四舍五入
SELECT ROUND(openingprice) FROM gpinfoc
NOW() - 返回当前的系统日期和时间
FORMAT() - 格式化某个字段的显示方式timestampdiff()-时间差,例如:求年龄
SELECT userid,username,DATE_FORMAT(NOW(),'%Y') - DATE_FORMAT(brithday,'%Y') 年龄 FROM user1;
聚合函数
聚合函数是将“若干行数据”经过计算后聚合成“一行数据”,(不包含null数据)即空数据不包含在计算范围之内,所有需要注意使用ifnull()
count(col): 表示求指定列的总行数,
max(col): 表示求指定列的最大值
min(col): 表示求指定列的最小值
sum(col): 表示求指定列的和
avg(col): 表示求指定列的平均值
(三)SQL语句
数据定义语句(DDL)
数据库定义语句用于建库建表
数据库创建与删除
-- 创建数据库 CREATE
CREATE DATABASE 库名
-- 删除数据库 DROP
DROP DATABASE 库名
-- 查看所有数据库
show databases;
-- 查看一个数据库
show create database 库名;
-- 使用数据库
use 库名;
表的创建与删除与修改
-- 创建表
CREATE TABLE IF NOT EXITS 表名;
-- 创建表同时设置字段
CREATE TABLE IF NOT EXITS 表名{
id INT (10),
name VARCHAR(20) COMMENT '姓名', --COMMENT表示注释
sex VARCHAR(3)
}
-- 添加字段 ADD
ALTER TABLE 表名 ADD 字段名 字段类型;
-- 删除字段 DROP
ALTER TABLE 表名 DROP 字段名;
-- 修改字段 MODIFY或者CHANGE
ALTER TABLE 表名 MODIFY 字段名 字段类型(长度);
ALTER TABLE 表名 CHANGE 原字段名 新字段名 新字段类型;
-- 删除数据表内容
TRUNCATE TABLE
数据查询语句(DQL)
用于查询数据
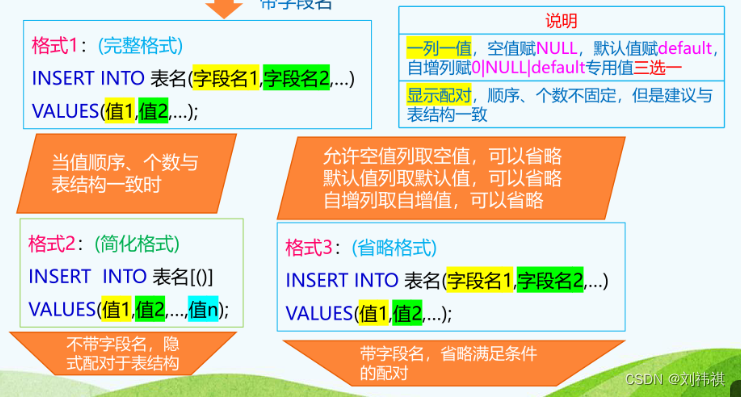
查询数据(SELECT)
-- 查询的语法格式
SELECT 查询列表 FROM 表名 WHERE 条件
(1)查询列表可以包括表中的字段、常量值(相当于增加一列常量值)、表达式、函数(求和);查询常量、表达式、函数时语句后面不用跟from 表名,因为它并不是表示来自哪个表。
(2)查询的结果是一个虚拟的表格
-- 查询表中所有信息
SELECT * FROM 表名;
-- 查询多个字段,用逗号隔开即可
SELECT 字段1,字段2,字段3 FROM 表名;
-- 用WHERE限制查询条件
SELECT * FROM 表名 WHERE 条件
-- 用LIMIT限制查询条数(限制为5条)
SELECT * FROM 表名 WHERE 条件 LIMIT 5
-- 用OFFSET限制偏移量(设置偏移量为2)
SELECT * FROM 表名 WHERE 条件 LIMIT 5 OFFSET 2
SELECT * FROM 表名 WHERE 条件 LIMIT 2,5 -- 与上一条语句是等价的
别名
-- 语法格式:SELECT 字段名 as "别名" FROM 表名
SELECT student_name as "姓名" FROM student
-- 也可以省略as(但不推荐这种用法)
SELECT student_name "姓名" FROM student
去重
查询book列表中得评分,但是我只想知道有哪些评分,查出来的话,会有一些评分重复.所以添加DISTINCT*,*进行去重
-- 语法格式:SELECT DISTINCT 字段名 FROM 表名
SELECT DISTINCT score FROM book
联合
union 和 union all 的区别是,union 会自动压缩多个结果集合中的重复结果,而 union all 则将所有的结果全部显示出来,不管是不是重复。
SELECT score FROM book
UNION ALL
SELECT bookname FROM book
+的作用
在数据库中,+只表示相加
SELECT 122+20; -- 数值加法运算
SELECT "222"+20; -- 其中一个是字符型,会试图将字符型数值转换成数值型,成功就做加法运算
SELECT "john"+20; -- 转化不了数值就直接转化为0
SELECT NULL+20; -- 只有有一个字符为null,结果就是null
如果想将两个字段加在一起输出,使用concat方法
SELECT CONCAT(username,sex) FROM user1
查询条件
(1)添加查询条件用WHERE语句;
(2)查询条件不止一个的时候,可以用AND或者OR
(3)查询介于两个数值之间的数据用 BETWEEN AND
(4)判断某一个字段的值是否属于列表中的某一项用 IN,如果不在表中使用NOT IN。
(5)判断字段是否为空用 IS NULL,判断不为空用 IS NOT NULL
(6)可以用操作符(>,<,=,!=,>=,<=)来添加查询条件
基础查询

在MySQL中,基础查询通常使用SELECT语句来执行。
以下是一些基本的查询示例:
- 查询所有列的所有记录:SELECT * FROM table_name;
- 查询特定的列:SELECT column1, column2 FROM table_name;
- 查询并去除重复的记录:SELECT * FROM table_name WHERE column_name = 'value';
- 条件查询(例如查询某列值为特定值的记录):SELECT * FROM table_name WHERE column_name = 'value';
- 排序查询结果(例如按某列升序排序):SELECT * FROM table_name ORDER BY column_name ASC;
- 限制查询结果的数量:SELECT * FROM table_name LIMIT 5;
- 结合条件和排序进行查询:SELECT * FROM table_name WHERE column_name = 'value' ORDER BY another_column_name DESC LIMIT 5;
-

-
分组查询
-
1、分组查询是对数据按照某个或多个字段进行分组,在MYSQL中使用GROUP BY关键字数据进行分组
-
2、GROUP BY关键字可以将查询结果按照某个字段或多个字段进行分组。字段中值相等为一组
⑴分组的核心是:在查询SQL中指定分组的列名,然后根据该列的值进行分组,值相等为一组创建分组
1、对数据进行分组,一般有两种使用场景:
⑴单独使用GROUP BY关键字,
⑵将GROUP BY关键字与聚合函数一起使用(常用)2、对于GROUP BY子句的使用,需要注意以下几点:
⑴GROUP BY子句可以包含任意数目的列,使其可以对分组进行嵌套,为数据分组提供更加细致的控制
⑵GROUP BY子句列出的每个列都必须是检索列或有效的表达式,但不能是聚合函数。若在SELECT语句中使用表达式,则必须在GROUP BY子句中指定相同的表达式3、若用于分组的列中包含有NULL值,则NULL将作为一个单独的分组返回;若该列中存在多个NULL值,则将这些NULL值所在的行分为一组
-
GROUP BY与聚合函数
1、GROUP BY关键字通常与集合函数一起使用。集合函数包括COUNT()函数、SUM()函数、AVG()函数、MAX()函数和MIN()函数2、如果GROUP BY不与聚合函数一起使用,那么查询结果就是字段取值的分组情况
⑴字段中取值相同的记录为一组,但是只显示该组的第一条记录(跟前面GROUP BY单独使用一样)3、常用的聚合函数有:
⑴COUNT()函数:用于统计记录的条数
⑵SUM()函数:用于计算字段的值的总和
⑶AVG()函数:用于计算字段的值的平均值
⑷MAX()函数:用于查询字段的最大值
⑸MIN()函数:用于查询字段的最小值 -

-

-
视图
-
视图是在数据库中定义的虚拟表。它是一个基于一个或多个实际表的查询结果集,可以像实际表一样被查询和操作。视图可以看作是一个动态生成的数据表,其内容是从其他表中选择、过滤和计算得到的。
视图通过使用SQL查询语句来定义,这些查询语句可以包括与一个或多个表的连接、条件过滤、列计算、聚合函数等操作。在视图定义中,我们可以指定要在视图中包含的列和行,以及对这些列进行何种计算和处理。
视图用途
简化复杂查询:通过将复杂的查询逻辑封装到视图中,可以简化应用程序中的查询操作。
数据安全性:视图可以限制用户对底层表的访问权限,从而提供更高的数据安全性和隐私保护。
数据抽象和封装:通过视图,可以将多个表的数据抽象为一个虚拟表,简化数据模型和应用程序开发。
性能优化:视图可以预先计算和存储结果集,以提高查询性能,并避免重复执行复杂查询。
视图的优点
数据的抽象和简化:视图是一个虚拟表,它可以根据特定的查询语句从一个或多个表中选择、过滤和计算数据。通过使用视图,可以将复杂的查询逻辑和多表连接操作封装为一个简化的视图查询,提供了更简洁、更易于理解的数据模型。数据安全性:视图可以限制用户对底层表的访问权限。通过给用户授予对视图的访问权限,可以隐藏底层表的结构和敏感数据,只允许用户在特定条件下查看和操作数据。这为数据库提供了更高的安全性和数据保护。
逻辑数据分离和模块化:通过视图,可以将数据逻辑分离为不同的模块。这使得数据库的维护和管理更加灵活,可以根据需要对各个模块进行独立的修改和优化,而无需影响其他模块。
提高查询性能:视图可以预先计算和存储查询结果,从而提高查询性能。当使用视图进行查询时,MySQL 可以利用预先计算的结果,而不需要重新执行复杂的查询操作。这对于频繁执行相同查询的场景非常有用。
简化应用开发:通过将复杂的查询逻辑封装为视图,应用程序开发人员可以更快速、更轻松地构建应用程序。他们只需要简单地查询视图,而无需关心视图背后的复杂查询逻辑和表结构。
视图缺点
性能影响:视图查询可能在执行时产生额外的性能开销。因为视图是根据查询语句动态生成的,每次查询时都需要重新计算视图的结果。对于复杂的视图和大型数据集,这可能导致询较慢,影响数据库性能。更新限制:默认情况下,MySQL 不允许对含特定条件的视图进行更新操作。这些条件包括使用聚合函数、DISTINCT、GROUP BY 和 HAVING 等的视图。因此,如果你使用的视图有这些限制条件,你将无法对其进行直接的插入、更新或删除操作。数据一致性:视图查询的结果是根据底层表的数据动态生成的,而不是存储实际的数据副本。这意味着如果底层表的数据发生了变化,但视图查询结果没有及时更新,可能导致数据一致性的问题。限制和复杂性:视图的使用是受到一些限制的,特别是在涉及复杂的查询和多表连接时。一些复杂的查询逻辑和操作可能无法在视图中实现,这可能需要使用其他技或重新设计询。管理复杂性:随着数据库中视图的数量增加,管理和维护视图变得更加困难。复杂的视图次结构和依赖关系可能会导致维护和调试问题的增加
-
创建视图
Create [or replace 替换 ] [algroithm 视图选择的算法 ={undefined|merge |temptable}] view 视图名 [(column_list)] as select_statement [with[cascaded|local]check option]
[algroithm 视图选择的算法 ={undefined|merge |temptable}] Undefined :不常用。 merge :表示将使用 的视图语句与视图定义合并起来,使视图定义的某一部分取代语句对应的部分 temptable :表示将视图 的结果存入临时表,然后用临时表来执行语句
with[cascaded|local] Cascaded :默认为cascaded,表示更新视图时,满足所有相关视图和表的条件。 -


索引
-
索引的作用相当于图书的目录,可以根据目录中的页码快速找到所需的内容。数据库使用索引以找到特定值,然后顺指针找到包含该值的行。在表中建立索引,然后在索引中找到符合查询条件的索引值,最后通过保存在索引中的 ROWID(相当于页码)快速找到表中对应的记录。索引的建立是表中比较有指向性的字段,相当于目录,比如说行政区域代码,同一个地域的行政区域代码都是相同的,那么给这一列加上索引,避免让它重复扫描,从而达到优化的目的。
-
















 3182
3182











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









