






网络爬虫(Web Crawler)是一种自动化程序,用于从互联网上系统地浏览和收集数据。它被广泛应用于搜索引擎、数据分析、价格监控、信息聚合等领域。以下是对网络爬虫的详细介绍:
网络爬虫的定义
网络爬虫(又称网络蜘蛛、机器人)通过模拟人类浏览网页的行为,自动访问网页并提取其内容,最终将数据存储或处理后供后续使用。其核心目标是高效、合法地获取目标信息。
工作原理
-
种子URL初始化
爬虫从一个或多个初始URL(种子链接)开始,例如网站首页或特定页面。 -
下载页面
通过HTTP/HTTPS协议请求网页内容(如HTML、JSON),常用的库包括Python的requests或Scrapy。 -
解析内容
使用正则表达式、BeautifulSoup、lxml或PyQuery等工具提取页面中的文本、链接或其他结构化数据。 -
URL管理
将新发现的链接加入待抓取队列(通常使用队列或优先队列),并通过去重(如布隆过滤器、哈希表)避免重复抓取。 -
存储数据
将提取的数据保存到数据库(如MySQL、MongoDB)、文件(CSV、JSON)或云端存储。 -
遵守协议
遵循robots.txt文件的规定,控制抓取频率以避免对服务器造成过大压力。
网络爬虫的分类
-
通用爬虫
面向全网,用于搜索引擎(如Google Bot)构建索引,抓取范围广但深度不足。 -
聚焦爬虫(主题爬虫)
针对特定主题或网站(如电商价格监控),通过规则或机器学习过滤无关内容。 -
增量式爬虫
仅抓取更新或新增内容,减少资源消耗。 -
深度爬虫
抓取需要登录或通过多层交互的页面(如AJAX动态内容)。
核心技术组成
-
页面下载器
处理HTTP请求、应对反爬机制(如User-Agent轮换、IP代理池、Cookie管理)。 -
解析器
提取数据(XPath、CSS选择器)或处理JavaScript渲染的页面(如Selenium、Puppeteer)。 -
调度器
管理URL优先级、调度多线程/异步任务(如Scrapy框架的异步引擎)。 -
去重机制
使用算法(如SimHash、MD5)或数据库(Redis)高效判断URL是否已抓取。 -
反反爬策略
应对验证码(OCR识别、第三方打码平台)、IP封禁(代理IP池)、请求频率限制(随机延迟)等。
处理HTTP请求、应对反爬机制(如User-Agent轮换、IP代理池、Cookie管理)。

典型应用场景
-
搜索引擎
抓取全网页面建立索引库(如Google、百度)。 -
数据分析
收集社交媒体、新闻、评论等数据用于情感分析或市场研究。 -
价格监控
追踪电商平台商品价格波动(如Keepa、 camelcamelcamel)。 -
内容聚合
整合多来源信息(如新闻聚合网站、学术论文库)。 -
SEO优化
分析网站结构、外链和关键词排名。
挑战与限制
-
反爬虫技术
-
检测手段:User-Agent验证、IP频率限制、JavaScript加密、验证码。
-
应对策略:动态请求头、分布式爬虫、Headless浏览器(如Playwright)。
-
-
动态内容加载
AJAX、React/Vue等前端框架生成的页面需通过渲染工具解析。 -
法律与道德风险
-
违反《计算机欺诈与滥用法》(如美国CFAA)或欧盟GDPR可能导致法律纠纷。
-
抓取用户隐私数据或受版权保护内容可能侵权。
-
-
资源消耗
高频抓取可能占用目标服务器带宽,引发服务拒绝。

url ='https://www.jd.com/?cu=true&utm_source=baidu-pinzhuan&utm_medium=cpc&utm_campaign=t_288551095_baidupinzhuan&utm_term=0f3d30c8dba7459bb52f2eb5eba8ac7d_0_086d17012e04401aba120fa26464844f'
headers={
'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/134.0.0.0 Safari/537.36',
'cookie':'unpl=JF8EALBnNSttCE5RBB0BE0YZQlRcW1QMGB9TPzBQXFpfH1wMGgEcExh7XlVdWRRKFR9sYxRUWlNLVg4YCisSEXteXVdZDEsWC2tXVgQFDQ8VXURJQlZAFDNVCV9dSRZRZjJWBFtdT1xWSAYYRRMfDlAKDlhCR1FpMjVkXlh7VAQrAhgUFkhaVFxVDHsWM2hXNWReXEJWDBMyGiIRex8AAlQPSxALaSoFV1teSFMFGQofIhF7Xg; __jda=76161171.1277261395.1742890406.1742890406.1742890407.1; __jdb=76161171.1.1277261395|1.1742890407; __jdc=76161171; __jdv=76161171|baidu-pinzhuan|t_288551095_baidupinzhuan|cpc|0f3d30c8dba7459bb52f2eb5eba8ac7d_0_a440729e8889485b9aafd966e9802609|1742890406686; __jdu=1277261395; 3AB9D23F7A4B3CSS=jdd03OHD6PONOJXH7CAXSWAZX7H3VGGEYSE2FKT2PZWNVMQHKVI6QCXPYBGAQWQNYVKKQ5TEWP3WWPOQAGTRKRGETNUM2LAAAAAMVZROSCUIAAAAADD772D3ZTYZ654X; 3AB9D23F7A4B3C9B=OHD6PONOJXH7CAXSWAZX7H3VGGEYSE2FKT2PZWNVMQHKVI6QCXPYBGAQWQNYVKKQ5TEWP3WWPOQAGTRKRGETNUM2LA; o2State={%22webp%22:true%2C%22avif%22:true}; areaId=20; ipLoc-djd=20-1720-0-0; PCSYCityID=CN_450000_450200_0; shshshfpa=8a95c919-3ffc-f86b-ba08-0a2f89e939b8-1742890408; shshshfpx=8a95c919-3ffc-f86b-ba08-0a2f89e939b8-1742890408; sdtoken=AAbEsBpEIOVjqTAKCQtvQu17T2REDD5CHYZK0ZyS8nxe9Ap71zAO-ZfKTPSSqe94MRE4oZB6WQtR3Wx_JFT_etyjB8NkRf9xkIaIPRHMG7qFTDOhrCDUKmXpzFjOeLKqo9Hesw; shshshfpb=BApXS3qlVz_BAY2cJzbsW3wjBY1gyL4hiBgDIAydo9xJ1Mg5e_4G2'
}
res = requests.get(url=url,headers=headers)
html_str = res.text
print(html_str)with open('京东商品页面.txt','r') as f:
html_str = f.read()
print(html_str)list_title = re.findall(r'<em>\s+(.*?)</em>',html_str)
list_title常用工具与框架
-
Python库:Scrapy(高效框架)、Requests(HTTP请求)、BeautifulSoup(HTML解析)。
-
浏览器自动化:Selenium、Puppeteer(处理动态页面)。
-
云服务:Apify、Octoparse(无代码爬虫平台)。
-
分布式爬虫:使用Redis管理队列、Scrapy-Redis扩展。

| go | go |
| go | go |
| go | go |
干货!手把手教你用免费神器,批量下载 CSDN 等各种网页文章资源 + 各种网页内容
import requests
from bs4 import BeautifulSoup
import pandas as pd
from sqlalchemy import create_engine
def crawl_car_sales(database, table_name):
"""
爬取车主之家新能源车月销量排行榜第一页数据并存储到数据库
参数:
database: 数据存储的mysql数据库名称
table_name: 数据存储的mysql表名
"""
# 数据爬取
url = 'https://xl.16888.com/ev.html'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/134.0.0.0 Safari/537.36'
}
try:
res = requests.get(url=url, headers=headers)
res.raise_for_status() # 检查请求是否成功
html_str = res.text
# 数据解析
soup = BeautifulSoup(html_str, 'lxml')
# 提取表格行
rows = soup.select('#xl_tab tr')[1:] # 跳过表头行
data = []
for row in rows:
cols = row.find_all('td')
if len(cols) >= 6: # 确保有足够的列
rank = cols[0].get_text(strip=True)
car_model = cols[1].get_text(strip=True)
manufacturer = cols[2].get_text(strip=True)
sales_volume = cols[3].get_text(strip=True)
month_change = cols[4].get_text(strip=True)
year_change = cols[5].get_text(strip=True)
data.append({
'排名': rank,
'车型': car_model,
'厂商': manufacturer,
'销量': sales_volume,
'环比变化': month_change,
'同比变化': year_change
})
# 创建DataFrame
df = pd.DataFrame(data)
print(df)
# 数据存储
engine = create_engine(f'mysql+pymysql://root:123456@localhost:3306/{database}')
df.to_sql(table_name, engine, index=False, if_exists='append')
print("数据爬取并存储成功!")
except Exception as e:
print(f"爬取过程中出现错误: {e}")
# 使用示例
# crawl_car_sales('car_sales_db', 'ev_sales_data')
-
确保已安装所需库:
requests,beautifulsoup4,pandas,sqlalchemy,pymysql -
修改数据库连接信息(用户名、密码、主机等)以匹配您的MySQL设置
-
调用函数时传入数据库名和表名,例如:
crawl_car_sales('car_sales_db', 'ev_sales_data')
功能说明:
-
爬取车主之家新能源车月销量排行榜第一页数据
-
提取包括排名、车型、厂商、销量、环比变化和同比变化等信息
-
将数据存储到指定的MySQL数据库中
-
包含基本的错误处理机制
注意事项:
-
请遵守网站的robots.txt规则和爬虫道德规范
-
如果网站有反爬机制,可能需要添加更多请求头或使用代理
-
数据库表会自动创建,但如果已存在,数据会追加到表中(除非修改if_exists参数)

import requests
from bs4 import BeautifulSoup
import pandas as pd
from sqlalchemy import create_engine
import time
# 爬取某一页豆瓣短评数据并存储的函数
def get_one_page(url,database,table_name):
'''
url:某电影的豆瓣短评页面url;\n
database:数据存储的mysql数据库名称;\n
table_name:数据存储的mysql表名
'''
# 数据爬取
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/134.0.0.0 Safari/537.36 Edg/134.0.0.0',
}
res = requests.get(url=url,headers=headers)
html_str = res.text
# 数据解析
soup = BeautifulSoup(html_str,'lxml')
list_name = [a.string for a in soup.select('.comment-info a')]
list_time = [span.string.strip() for span in soup.select('.comment-time')]
list_location = [span.string for span in soup.select('.comment-location')]
list_votes = [span.string for span in soup.select('.votes')]
list_content = [span.string for span in soup.select('.short')]
df = pd.DataFrame(
{
'用户名':list_name,
'评论时间':list_time,
'IP地':list_location,
'点赞数量':list_votes,
'评论内容':list_content
}
)
print(df)
# 数据存储
engine = create_engine(f'mysql+pymysql://root:123456@localhost:3306/{database}')
df.to_sql(table_name,engine,index=False,if_exists='append')
# 翻页爬取函数
def get_more_page(url, max_page, database, table_name):
"""
翻页爬取豆瓣短评
参数:
url: 需要爬取的豆瓣短评电影首页url
max_page: 需要爬取多少页
database: 数据存储的mysql数据库名称
table_name: 数据存储的mysql表名
"""
# 爬取首页
get_one_page(url, database, table_name)
# 爬取第2到第max_page页
for i in range(2, max_page + 1):
url_new = url[:url.find('?') + 1] + f'start={20 * (i - 1)}&limit=20&status=P&sort=new_score'
# 爬取第i页
get_one_page(url_new, database, table_name)
# 程序暂停2秒
time.sleep(2)
with open('京东商品页面.txt','r') as f:
html_str = f.read()
print(html_str)
<!DOCTYPE html> <head> <meta http-equiv="Content-Type" content="text/html; charset=utf-8" /> <meta http-equiv="X-UA-Compatible" content="IE=edge"> <meta name="renderer" content="webkit"> <meta http-equiv="Cache-Control" content="max-age=300" /> <link rel="dns-prefetch" href="//search.jd.com" /> <link rel="dns-prefetch" href="//item.jd.com" /> <link rel="dns-prefetch" href="//list.jd.com" /> <link rel="dns-prefetch" href="//p.3.cn" /> <link rel="dns-prefetch" href="//misc.360buyimg.com" /> <link rel="dns-prefetch" href="//nfa.jd.com" /> <link rel="dns-prefetch" href="//d.jd.com" /> <link rel="dns-prefetch" href="//img12.360buyimg.com" /> <link rel="dns-prefetch" href="//img13.360buyimg.com" /> <link rel="dns-prefetch" href="//static.360buyimg.com" /> <link rel="dns-prefetch" href="//csc.jd.com" /> <link rel="dns-prefetch" href="//mercury.jd.com" /> <link rel="dns-prefetch" href="//x.jd.com" /> <link rel="dns-prefetch" href="//wl.jd.com" /> <title>空调 - 商品搜索 - 京东</title> <meta name="Keywords" content="空调,京东空调" /> <meta name="description" content="在京东找到了空调722194件空调的类似商品,其中包含了空调价格、空调评论、空调导购、空调图片等相关信息" /> <style> .lv_prompt {
...
} </script> </html>
from bs4 import BeautifulSoup
soup = BeautifulSoup(html_str,'lxml')
soup
<!DOCTYPE html> <html><head> <meta content="text/html; charset=utf-8" http-equiv="Content-Type"/> <meta content="IE=edge" http-equiv="X-UA-Compatible"/> <meta content="webkit" name="renderer"/> <meta content="max-age=300" http-equiv="Cache-Control"/> <link href="//search.jd.com" rel="dns-prefetch"/> <link href="//item.jd.com" rel="dns-prefetch"/> <link href="//list.jd.com" rel="dns-prefetch"/> <link href="//p.3.cn" rel="dns-prefetch"/> <link href="//misc.360buyimg.com" rel="dns-prefetch"/> <link href="//nfa.jd.com" rel="dns-prefetch"/> <link href="//d.jd.com" rel="dns-prefetch"/> <link href="//img12.360buyimg.com" rel="dns-prefetch"/> <link href="//img13.360buyimg.com" rel="dns-prefetch"/> <link href="//static.360buyimg.com" rel="dns-prefetch"/> <link href="//csc.jd.com" rel="dns-prefetch"/> <link href="//mercury.jd.com" rel="dns-prefetch"/> <link href="//x.jd.com" rel="dns-prefetch"/> <link href="//wl.jd.com" rel="dns-prefetch"/> <title>空调 - 商品搜索 - 京东</title> <meta content="空调,京东空调" name="Keywords"/> <meta content="在京东找到了空调722194件空调的类似商品,其中包含了空调价格、空调评论、空调导购、空调图片等相关信息" name="description"/> <style> .lv_prompt {
...
}catch(e){ console.log("jingmai error",e); } </script> </html>
#价格
[i.string for i in soup.select('strong i')]
['3683.40', '1791.80', '899.00', '1791.80', '2685.22', '1791.80', '2288.81', '4082.60', '1811.40', '3983.00', '2199.00', '2887.40', '2849.05', '2489.00', '2489.00', '2289.80', '2199.00', '1742.00', '1592.60', '1801.44', '2189.80', '2688.20', '3783.80', '2987.00', '3385.40', '2090.20', '1649.00', '899.00', '2787.80', '3485.00']
#标题
[em for em in soup.select('.p-name a em')]
<em> 京灿奥克斯(AUX)<font class="skcolor_ljg">空调</font> 3匹柜机 大风量 新1级能效 国家补贴 变频冷暖 立柜式<font class="skcolor_ljg">空调</font>KFR-72LW/BpR3JDQA(B1) 京东自营</em>, <em> 科龙(KELON)<font class="skcolor_ljg">空调</font>静省电 大1.5匹挂机新一级能效AI省电轻音变频冷暖 以旧换新国家政府补贴20% KFR-35GW/QS1-X1</em>, <em> 先科新一级能效 省电变频冷暖<font class="skcolor_ljg">空调</font> 大1.5匹 卧室出租屋壁挂式<font class="skcolor_ljg">空调</font>挂机 大1匹 一级能效 单冷 无安装服务</em>, <em> 长虹(CHANGHONG)大1.5匹新一级超省电熊猫懒变频冷暖<font class="skcolor_ljg">空调</font> 国家补贴20%<font class="skcolor_ljg">空调</font>挂机卧室 KFR-35GW/ZDCSW1+R1以旧换新</em>, <em> 小米(MI)米家 1.5匹 巨省电pro 超一级能效 变频冷暖 <font class="skcolor_ljg">空调</font>挂机 KFR-35GW/V1A1【国家补贴20%】</em>, <em> 华凌<font class="skcolor_ljg">空调</font> 大1.5匹 新一级能效 超省电 变频冷暖 <font class="skcolor_ljg">空调</font>挂机 华为互联 KFR-35GW/N8HA1Ⅲ 家电国家补贴</em>, <em> TCL京东联名 2匹新一级能效 真省电SE挂机 省电<font class="skcolor_ljg">空调</font>冷暖变频KFR-46GW/JD21+B1国家补贴以旧换新 京东自营</em>, <em> 格力(GREE)1.5匹 京赏 一级能效 AI节能 净菌自洁 壁挂式<font class="skcolor_ljg">空调</font>挂机 KFR-35GW/(35598)FNhAd-B1(JDWIFI)</em>, <em> 奥克斯(AUX)大1匹 省电侠 国家补贴 新一级<font class="skcolor_ljg">空调</font>挂机 变频冷暖 ECO节能KFR-26GW/BpR3AQS1(B1)一键舒风</em>, <em> 华凌<font class="skcolor_ljg">空调</font>3匹柜机 超省电Pro 新一级能效 变频冷暖省电立式柜机<font class="skcolor_ljg">空调</font> KFR-72LW/N8HA1Ⅲ 家电国家补贴</em>, <em> 美的<font class="skcolor_ljg">空调</font> 酷省电 新一级能效 变频冷暖 家电国家补贴 独立除湿 节能省电家用卧室挂机 以旧换新 大1.5匹 一级能效 【爆款】省电25%</em>, <em> 美的(Midea)<font class="skcolor_ljg">空调</font> 京绽 1.5匹挂机 变频冷暖 新一级变频壁挂式<font class="skcolor_ljg">空调</font> 超大风量 KFR-35GW/BDN8Y-MJ101(1)</em>, <em> 美的<font class="skcolor_ljg">空调</font> 大1.5匹 熊猫新风 超一级能效 家电国家补贴20% 变频 节能节电 <font class="skcolor_ljg">空调</font>挂机 KFR-35GW/N8PD1-1</em>, <em> 奥克斯大1.5匹 京岳 新一级能效 大风量 家用变频冷暖两用 挂壁式<font class="skcolor_ljg">空调</font>挂机KFR-35GW/BpR3AEG28(B1)</em>, <em> 格力(GREE)大1匹 天仪 一级能效 变频冷暖 净菌自洁 出风口可拆洗 壁挂式<font class="skcolor_ljg">空调</font>挂机 KFR-26GW/(26504)FNhAa-B1</em>, <em> 美的<font class="skcolor_ljg">空调</font>大1.5匹冷静星 新一级能效变频冷暖节能卧室壁挂式挂机一键酷省电 KFR-35GW/PH2 家电国家补贴</em>, <em> 小米<font class="skcolor_ljg">空调</font>巨省电新一级能效 变频冷暖 1.5匹壁挂式卧室智能<font class="skcolor_ljg">空调</font>挂机KFR-35GW/N1A1 家电国家补贴20% 1.5匹 一级能效</em>, <em> 华凌<font class="skcolor_ljg">空调</font>美的出品挂机大1.5匹新一级能效变频冷暖省电大风口以旧换新家电国家补贴 KFR-35GW/N8HA1 Ⅱ</em>, <em> 京灿奥克斯(AUX)<font class="skcolor_ljg">空调</font> 大1.5匹挂机 国家补贴 新1级能效 变频冷暖 卧室挂式KFR-35GW/BpR3JDFW(B1) 京东自营</em>, <em> 海尔 静悦1.5匹 新一级能效变频冷暖 卧室壁挂式<font class="skcolor_ljg">空调</font>挂机 KFR-35GW/01KGC81U1 国家补贴以旧换新</em>, <em> 美的(Midea)酷省电 <font class="skcolor_ljg">空调</font>挂机 大1.5匹新一级能效全直流变频节能省电低噪音防直吹 以旧换新 国家补贴 立享8折 大1.5匹 一级能效 酷省电 省电25%</em>, <em> 格力(GREE)1.5匹 天仪 一级能效 变频冷暖 净菌自洁 出风口可拆洗 壁挂式<font class="skcolor_ljg">空调</font>挂机 KFR-35GW/(35504)FNhAa-B1</em>, <em> 长虹(CHANGHONG)大3匹新一级能效 家电国家补贴 超省电熊猫懒立式<font class="skcolor_ljg">空调</font>柜机KFR-72LW/ZDTTW2+R1 以旧换新</em>, <em> 美的<font class="skcolor_ljg">空调</font> 大1.5匹风尊二代 家电国家补贴20%<font class="skcolor_ljg">空调</font>挂机 以旧换新 超一级能效 KFR-35GW/N8MXC1Ⅱ</em>, <em> 格力(GREE)1.5匹 云锦三代 新1级能效变频壁挂式卧室<font class="skcolor_ljg">空调</font>挂机KFR-35GW/NhAe1BAj家电国家补贴</em>, <em> 美的(Midea)大1.5匹 <font class="skcolor_ljg">空调</font> 酷省电PRO 国家补贴20% 新一级能效变频节能省电 冷暖壁挂式智能家用 挂机以旧换新 大1匹 一级能效 酷省电 省电24%</em>, <em> TCL<font class="skcolor_ljg">空调</font>1.5/2匹 真省电SE <font class="skcolor_ljg">空调</font>挂机 超一级能效 变频冷暖 壁挂式卧室挂机 以旧换新 国家补贴20%<font class="skcolor_ljg">空调</font> 1.5匹 一级能效 真省电SE</em>, <em> 先科【政府补贴20%】一级能效 省电变频冷暖<font class="skcolor_ljg">空调</font> 大1.5匹 卧室出租屋壁挂式<font class="skcolor_ljg">空调</font>挂机 大1匹 一级能效 单冷【不带安装】</em>, <em> 小米(MI)米家 2匹 新一级能效 变频冷暖 巨省电 壁挂式挂机 KFR-50GW/N2A1 以旧换新【国家补贴20%】</em>, <em> 美的2匹 酷省电 新一级能效 变频冷暖 省电 智能卧室 <font class="skcolor_ljg">空调</font>挂机 家电国家补贴 KFR-46GW/N8KS1-1</em>]
| 1 | 2 |
| 3 | 4 |
| 5 | 6 |
import requests
from bs4 import BeautifulSoup
import pandas as pd
from sqlalchemy import create_engine
import time
def get_one_page(url,database,table_name):
# 数据爬取
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/134.0.0.0 Safari/537.36 Edg/134.0.0.0',
}
res = requests.get(url=url,headers=headers)
html_str = res.text
# print(html_str)
# 数据解析
soup = BeautifulSoup(html_str,'lxml')
list_rank = [td.string for td in soup.select('.xl-td-t1')]
list_name = []
list_brand = []
original_list = [td.string for td in soup.select('.xl-td-t2')]
list1= original_list[::2] #取索引 0,2,4...
list2= original_list[1::2] #取索引1,3,5...
print(list1)
print(list2)
list_sale = [td.string for td in soup.select('.xl-td-t3')]
str_date = soup.select('.xl-date-input')[0]['value']
list_date = [str_date] * len(list_rank) # 正确调用 len()
print(list_date)
df = pd.DataFrame(
{
'排名':list_rank,
'车型':list1,
'品牌':list2,
'销量':list_sale
}
)
print(df)
# 数据储存
engine = create_engine(f'mysql+pymysql://root:123456@localhost:3306/{database}')
df.to_sql(table_name,engine,index=False,if_exists='append')
if __name__== '__main__':
url = 'https://xl.16888.com/ev.html'
get_one_page(url)
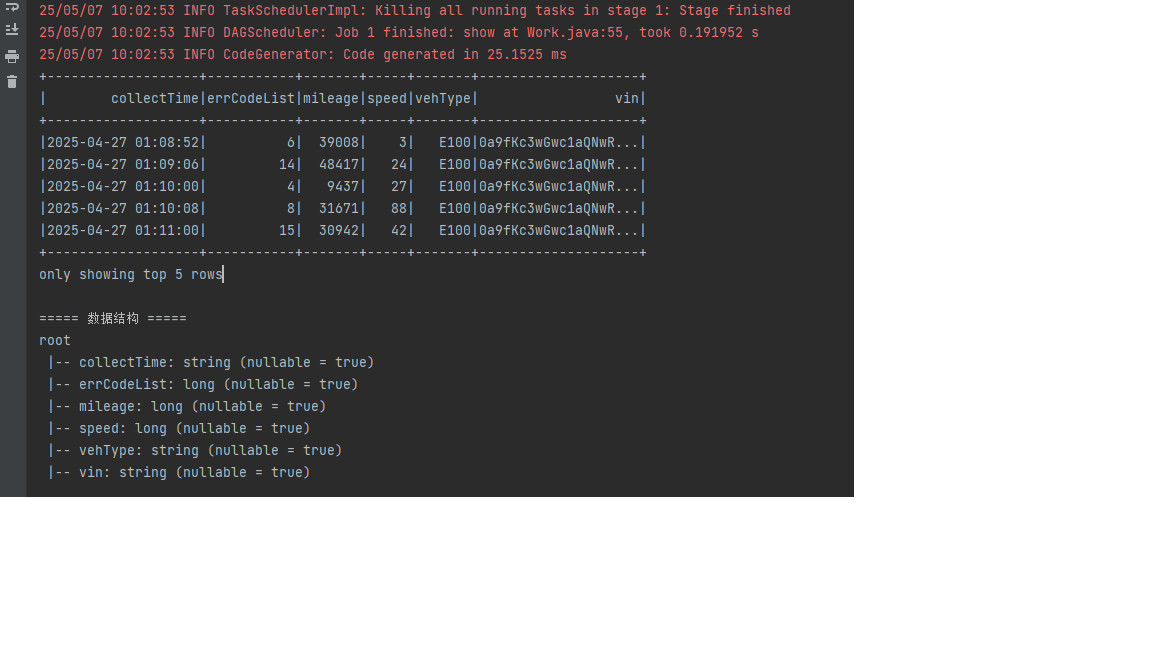
5/05/07 10:32:46 INFO Executor: Running task 0.0 in stage 9.0 (TID 225)
25/05/07 10:32:46 INFO Executor: Running task 1.0 in stage 9.0 (TID 226)
25/05/07 10:32:46 INFO Executor: Running task 2.0 in stage 9.0 (TID 227)
25/05/07 10:32:46 INFO Executor: Running task 4.0 in stage 9.0 (TID 229)
25/05/07 10:32:46 INFO Executor: Running task 8.0 in stage 9.0 (TID 233)
25/05/07 10:32:46 INFO Executor: Running task 3.0 in stage 9.0 (TID 228)
25/05/07 10:32:46 INFO Executor: Running task 9.0 in stage 9.0 (TID 234)
25/05/07 10:32:46 INFO Executor: Running task 7.0 in stage 9.0 (TID 232)
25/05/07 10:32:46 INFO Executor: Running task 10.0 in stage 9.0 (TID 235)
25/05/07 10:32:46 INFO Executor: Running task 6.0 in stage 9.0 (TID 231)
25/05/07 10:32:46 INFO Executor: Running task 5.0 in stage 9.0 (TID 230)
25/05/07 10:32:46 INFO Executor: Running task 11.0 in stage 9.0 (TID 236)
目录


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









