







 本文介绍了数据库设计的重要性,强调良好的设计能节省存储空间、保证数据完整性并简化开发。数据库设计包括需求分析、逻辑设计、物理设计等阶段,E-R图在逻辑设计中扮演关键角色。文章还讨论了E-R图转换为数据表的原则,如多对多关系的处理,并提到了规范化设计以减少数据冗余。最后,阐述了1NF、2NF和3NF的概念及其在消除数据冗余中的作用。
本文介绍了数据库设计的重要性,强调良好的设计能节省存储空间、保证数据完整性并简化开发。数据库设计包括需求分析、逻辑设计、物理设计等阶段,E-R图在逻辑设计中扮演关键角色。文章还讨论了E-R图转换为数据表的原则,如多对多关系的处理,并提到了规范化设计以减少数据冗余。最后,阐述了1NF、2NF和3NF的概念及其在消除数据冗余中的作用。
**
良好的数据库设计能够
**:
节省数据的存储空间。
能够保证数据的完整性。
方便进行数据库应用系统的开发。
糟糕的数据库设计:
数据冗余、存储空间浪费。
内存空间浪费。
数据更新和插入异常麻烦。
数据库的生命周期:
1、需求分析阶段 确定需求(与客户沟通)
2、逻辑设计阶段 通过数据模型(E-R模型、UML图例)得到数据概念模型 -> 转换为SQL表 -> 规范化
3、物理设计阶段 选择索引
4、实现阶段 把物理设计的结果转换为数据库管理系统(DBMS)中的DDL创建数据结构。通过SQL语句来进行增删改查。
5、再设计再修改。
6、废止
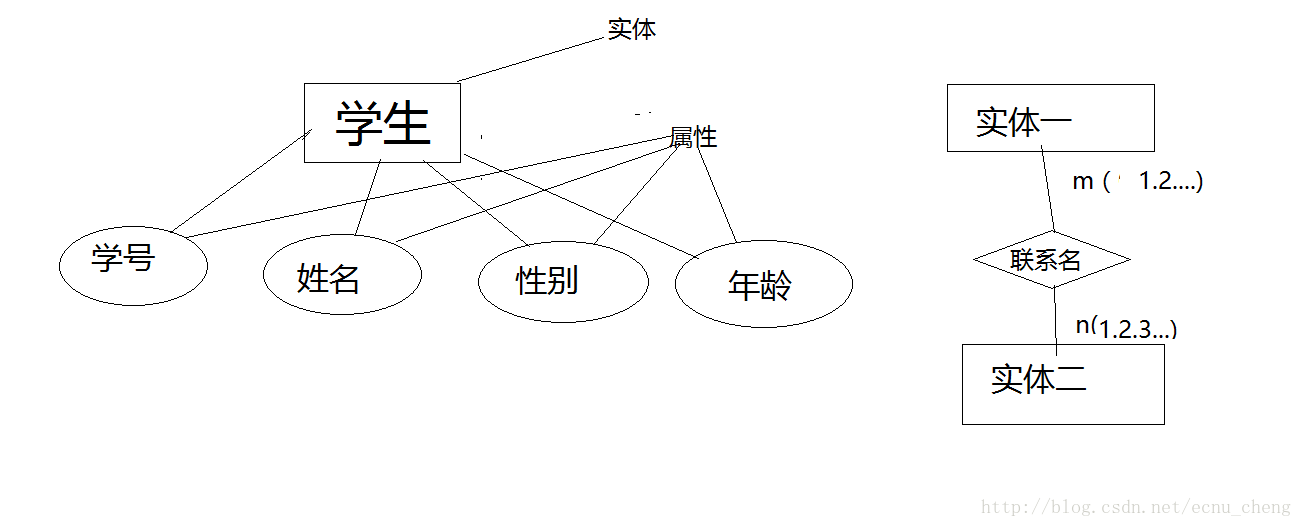
E-R图
E 实体 (一个学生、一本书、一门课、一个会议、一个关系…)
R 属性 (人的属性:年龄、性别 学生的属性:学号、性别、年龄…)
元组就是表中的一行。
分量就是某个属性值。
码就是表中唯一可以确定一个元组的某个属性,可以作为码的都是候选码,选出的一个码就是主码。
外码是一个属性(或者属性组),它不是码,但是它是别的表的码。
域是属性的取值范围。
概率示例图:
专业的画图工具有 Microsoft Vision 、、、
现在有一个教学管理系统。系统实体有:
教师,属性有 教师号、姓名、性别、年龄、出生日期
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















&spm=1001.2101.3001.5002&articleId=72721220&d=1&t=3&u=a18ccc87ca544b59a97d498893974ba7)
 4204
4204

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









