






哥们刚学ctf,看了看大家都说WEB和MISC上手更快,但是其他题我实在做不走了,于是去RE看了看,虽然做的不多,但还是觉得挺有趣的。
话不多说,直接看题:
1)base_64
顾名思义,考的就是base_64的相关内容,打开附件得到源码,很简单:
先去在线网站把.pyc文件反编译成.py文件:
https://toolkk.com/tools/pyc-decomplie#google_vignette得到如下代码:
import base64
from string import *
str1 = 'yD9oB3Inv3YAB19YynIuJnUaAGB0um0='
string1 = 'ZYXWVUTSRQPONMLKJIHGFEDCBAzyxwvutsrqponmlkjihgfedcba0123456789+/'
string2 = 'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/'
flag = input('welcome to moectf\ninput your flag and I wiil check it:')
enc_flag = base64.b64encode(flag.encode()).decode()
enc_flag = enc_flag.translate(str.maketrans(string2, string1))
if enc_flag == str1:
print('good job!!!!')
else:
print('something wrong???')
exit(0)
# okay decompiling /tmp/64e8b71bb111a.pyc
看了看就知道,把flag进行如上操作一步步得到最后的结果,那么我们就逆向分析,一步步给它反推回去,就能拿到flag了。
写个简单的脚本:
import base64
from string import *
str1 = 'yD9oB3Inv3YAB19YynIuJnUaAGB0um0='
string1 = 'ZYXWVUTSRQPONMLKJIHGFEDCBAzyxwvutsrqponmlkjihgfedcba0123456789+/'
string2 = 'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/'
flag_str1 = str1.translate(str.maketrans(string1,string2))
flag_original_bytes = flag_str1.encode()
flag_final_bytes = base64.b64decode(flag_original_bytes)
flag_final_str = flag_final_bytes.decode()
print(flag_final_str)运行即得到flag:

2)UPX!
看了下标题,然后去搜了搜,发现需要脱壳,那么我们就去kali里脱壳,然后再在IDA里分析就完事了。
脱壳完毕,直接再复制回windows,用IDA64打开并解析:
(刚用IDA的时候,根本看不懂,边搜边硬做的......QAQ)
搜索关键字moectf找到关键函数体,然后f5查看代码:
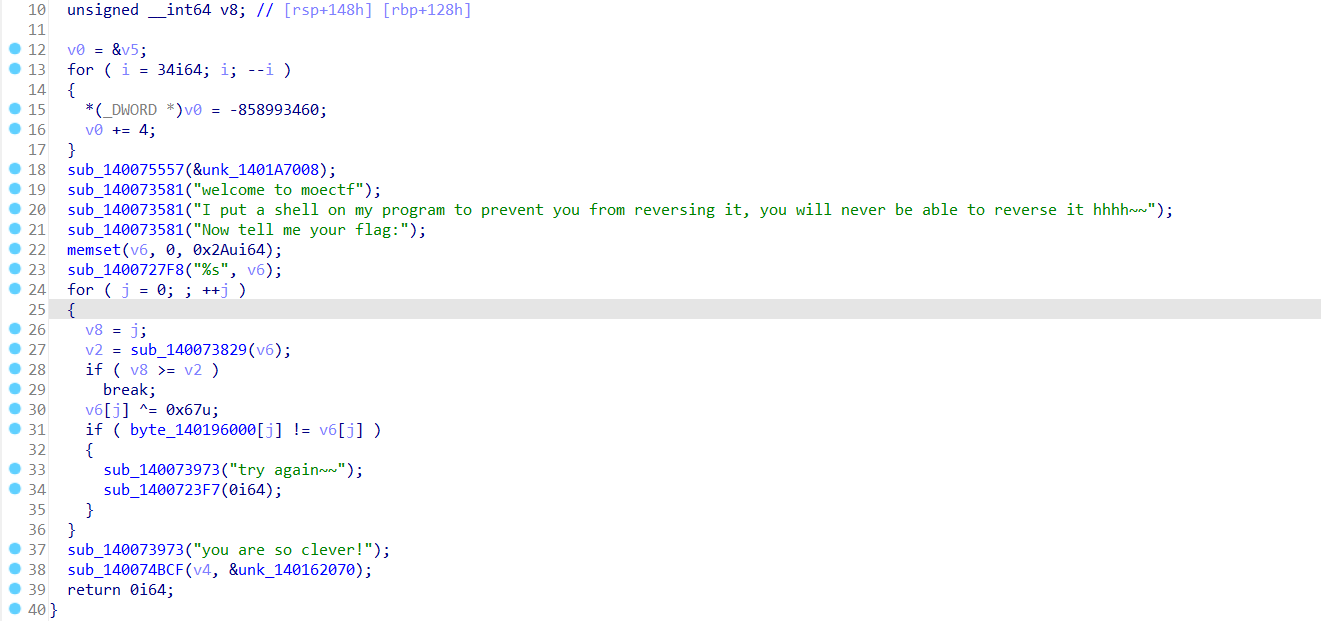
这就是关键函数,看了看是个很简单的异或,我们直接写个十六进制脚本就能解出来:
key = [0x0A, 0x08, 0x02, 0x04, 0x13, 0x01, 0x1C, 0x57, 0x0F, 0x38,
0x1E, 0x57, 0x12, 0x38, 0x2C, 0x09, 0x57, 0x10, 0x38, 0x2F,
0x57, 0x10, 0x38, 0x13, 0x08, 0x38, 0x35, 0x02, 0x11, 0x54,
0x15, 0x14, 0x02, 0x38, 0x32, 0x37, 0x3F, 0x46, 0x46, 0x46,
0x1A, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
0x00, 0x00, 0x00, 0x00]
for i in range(0,len(key)):
key[i] = key[i] ^ 0x67
print("".join(chr(x) for x in key))
运行得到flag~~
3)Xor
简单的Xor逆向,直接拿到IDA里一搜main就知道主要函数了:
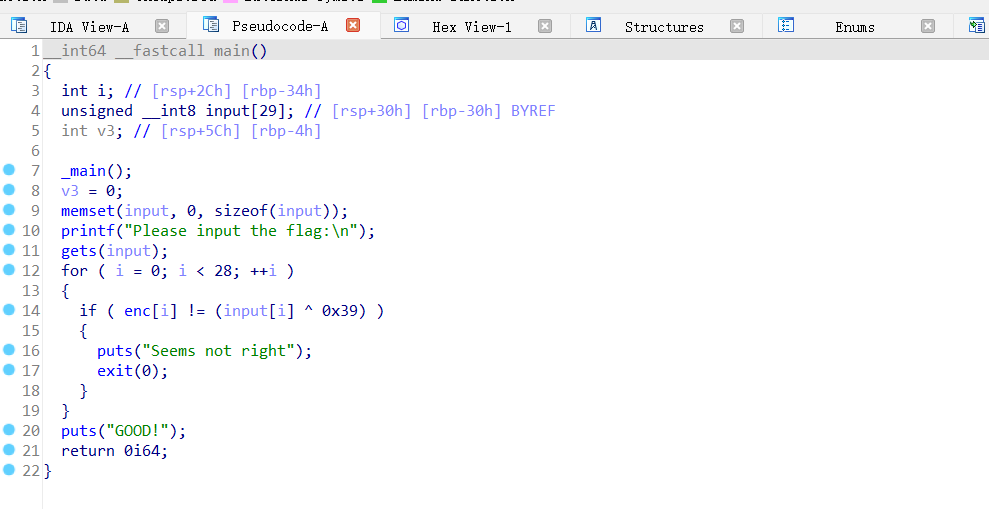
写个脚本解决:
key = [0x54, 0x56, 0x5C, 0x5A, 0x4D, 0x5F, 0x42, 0x60, 0x56, 0x4C, 0x66, 0x52, 0x57, 0x09, 0x4E, 0x66, 0x51, 0x09, 0x4E, 0x66, 0x4D, 0x09, 0x66, 0x61, 0x09, 0x6B, 0x18, 0x44]
for i in range(0,len(key)):
key[i] = key [i] ^ 0x39
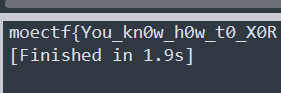
print("".join(chr(x) for x in key))运行得到flag:
4)ANDROID
据题目说是基于Java的,用的工具是JADX:
我们先在手机上安装看看:
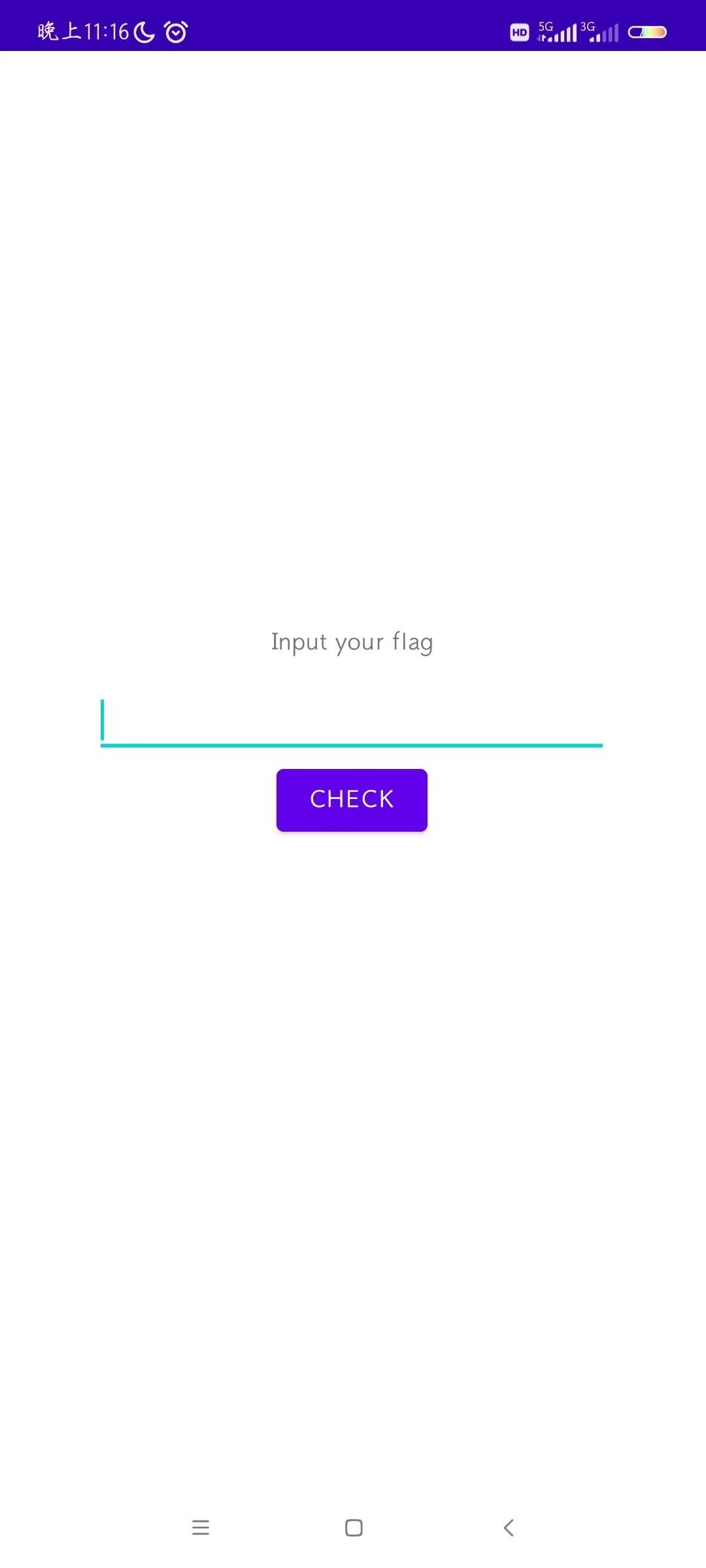
随便乱输提交,给了个反馈:“长度不对哦”
那么就好搜了哼哼~~
在下好的JADX中打开这个文件:
![]()
再打开需要逆向分析的文件,然后文本搜索关键信息“长度不对哦”找到主要函数:
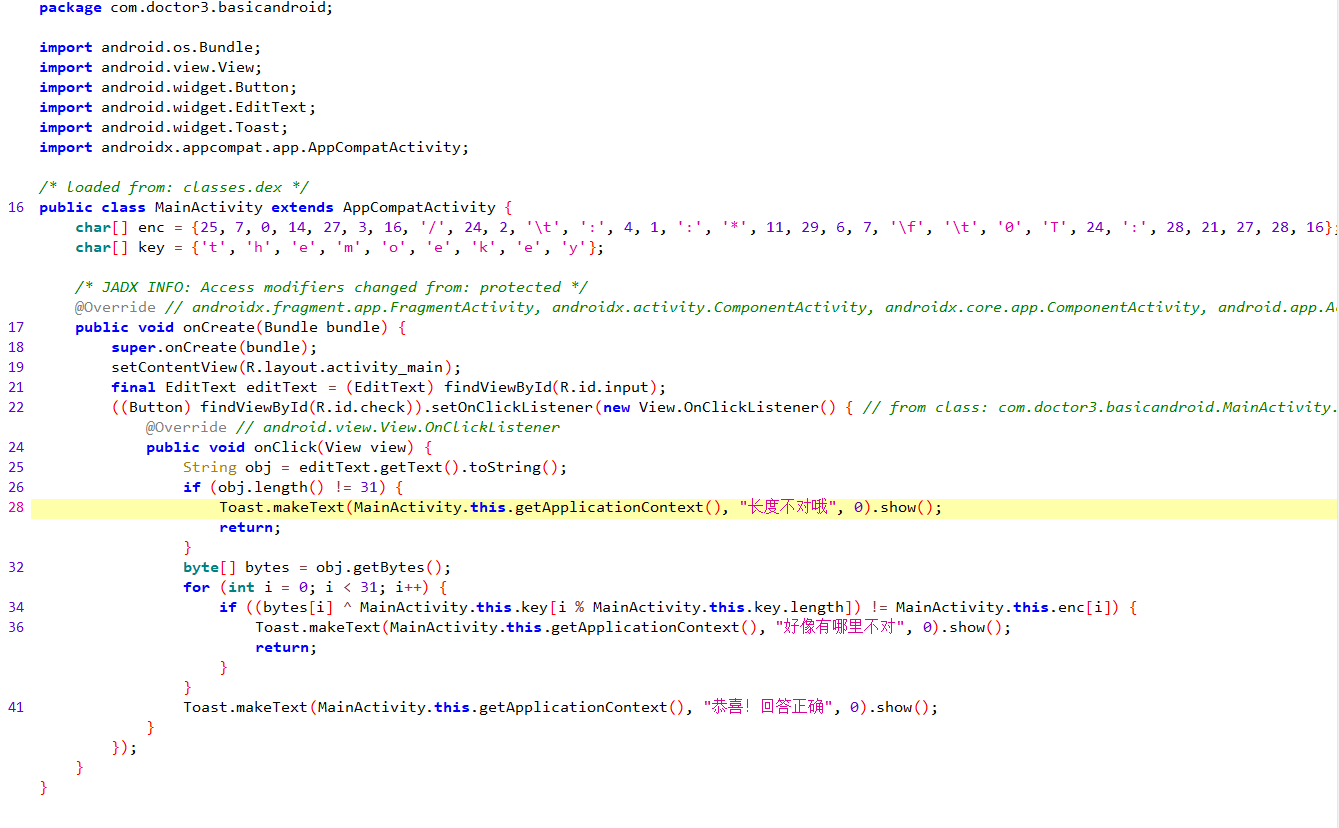
开始觉得很复杂,后面一看才发现换汤不换药,还是异或。
写个脚本也出来了:
#re: 1、把enc[i]每一项与key[i%key.length()]进行异或操作 得到字节数组
# 2、把字节数组变成字符串
#enc = [25, 7, 0, 14, 27, 3, 16, '/', 24, 2, '\t', ':', 4, 1, ':', '*', 11, 29, 6, 7, '\f', '\t', '0', 'T', 24, ':', 28, 21, 27, 28, 16]
#key = ['t', 'h', 'e', 'm', 'o', 'e', 'k', 'e', 'y']
#转十六进制
enc_hex = [0x19, 0x7, 0x0, 0xe, 0x1b, 0x3, 0x10, 0x2f, 0x18, 0x2, 0x9, 0x3a, 0x4, 0x1, 0x3a, 0x2a, 0xb, 0x1d, 0x6, 0x7, 0xc, 0x9, 0x30, 0x54, 0x18, 0x3a, 0x1c, 0x15, 0x1b, 0x1c, 0x10]
key_hex = [0x74, 0x68, 0x65, 0x6d, 0x6f, 0x65, 0x6b, 0x65, 0x79]
flag_bytes = [0] * len(enc_hex)
for i in range(0,len(enc_hex)):
flag_bytes[i] = enc_hex[i] ^ key_hex[i % len(key_hex)]
flag = "".join(chr(x) for x in flag_bytes)
print(flag)运行得到flag辣:

(未完待续......)
5)RC4
有点抽象,多余的就不写了,直接搜索关键字moectf找到关键函数:
sub_14007555C(&unk_1401A7007);
memset(v5, 0, sizeof(v5));
memset(v6, 0, sizeof(v6));
strcpy(v7, "moectf2023");
v8 = 0;
printf("welcome to moectf!!!");
printf("This is a very common algorithm ");
printf("show your flag:");
scanf("%s", arr);
if ( size(arr) == 37 )
{
sub_140075052((unsigned int)v5, (unsigned int)v6, (unsigned int)arr, 38, (__int64)v7, 10);
for ( j = 0; (unsigned __int64)j < 0x26; ++j )
{
if ( byte_140196000[j] == (unsigned __int8)arr[j] )
++v8;
}
}
if ( v8 == 37 )
sub_140073973("right!flag is your input!");
else
sub_140073973("try again~");
sub_140074BCF(v3, &unk_140162100);
return 0i64;
}
unsigned char ida_chars[] =
{
0x1B, 0x9B, 0xFB, 0x19, 0x06, 0x6A, 0xB5, 0x3B, 0x7C, 0xBA,
0x03, 0xF3, 0x91, 0xB8, 0xB6, 0x3D, 0x8A, 0xC1, 0x48, 0x2E,
0x50, 0x11, 0xE7, 0xC7, 0x4F, 0xB1, 0x27, 0xCF, 0xF3, 0xAE,
0x03, 0x09, 0xB2, 0x08, 0xFB, 0xDC, 0x22, 0x00
};下面是我提取出来的数据,本来我想自己逆出个脚本来的:
import numpy as np
# int result;
# int i;
# int j;
# int v9;
# int v10;
# int v11;
# char v12;
# char v13;
# int v14;
a1 = np.zeros(256)
a2 = np.zeros(256)
a3 = [0x1B, 0x9B, 0xFB, 0x19, 0x06, 0x6A, 0xB5, 0x3B, 0x7C, 0xBA, 0x03, 0xF3, 0x91, 0xB8, 0xB6, 0x3D, 0x8A, 0xC1, 0x48, 0x2E, 0x50, 0x11, 0xE7, 0xC7, 0x4F, 0xB1, 0x27, 0xCF, 0xF3, 0xAE, 0x03, 0x09, 0xB2, 0x08, 0xFB, 0xDC, 0x22, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00]
for x in a3:
x = chr(x) #转成字符数组
a4 = 38
a5 = "moectf2023"
a5 = list(a5)
a6 = 10
v10 = 0;
v14 = 0;
for i in range(0, 256):
a1[i] = i;
a2[i] = ord(a5[i % a6]);
for j in range(0, 256):
v10 = (a2[j] + a1[j] + j) % 256;
# 交换
v10 = int(v10)
j = int(j)
v12 = a1[v10];
a1[v10] = a1[j];
a1[j] = v12;
result = j + 1;
i = 0;
j = 0;
k = 0;
while (a4):
i = (i + 1) % 256;
j = (a1[i] + j) % 256;
# 交换
j = int(j)
i = int(i)
v13 = a1[j];
a1[j] = a1[i];
a1[i] = v13;
a1[i] = int(a1[i])
a1[j] = int(a1[j])
k = int(a1[j] + a1[i])
a3[v14] ^= a1[k] % 256;
v14 = v14 + 1;
result = --a4;
print(a3)
但是有问题,所以我去查了下CTFwiki,对应的RC4解码知识,
传送门:常见加密算法和编码识别 - CTF Wiki (ctf-wiki.org)
然后我就用了它给的脚本,真好用hhh~~~
import base64
def rc4_main(key = "init_key", message = "init_message"):
print("RC4解密主函数调用成功")
print('\n')
s_box = rc4_init_sbox(key)
crypt = rc4_excrypt(message, s_box)
return crypt
def rc4_init_sbox(key):
s_box = list(range(256))
print("原来的 s 盒:%s" % s_box)
print('\n')
j = 0
for i in range(256):
j = (j + s_box[i] + ord(key[i % len(key)])) % 256
s_box[i], s_box[j] = s_box[j], s_box[i]
print("混乱后的 s 盒:%s"% s_box)
print('\n')
return s_box
def rc4_excrypt(plain, box):
print("调用解密程序成功。")
print('\n')
plain = base64.b64decode(plain.encode('utf-8'))
plain = bytes.decode(plain)
res = []
i = j = 0
for s in plain:
i = (i + 1) % 256
j = (j + box[i]) % 256
box[i], box[j] = box[j], box[i]
t = (box[i] + box[j]) % 256
k = box[t]
res.append(chr(ord(s) ^ k))
print("res用于解密字符串,解密后是:%res" %res)
print('\n')
cipher = "".join(res)
print("解密后的字符串是:%s" %cipher)
print('\n')
print("解密后的输出(没经过任何编码):")
print('\n')
return cipher
a=[0x1B, 0x9B, 0xFB, 0x19, 0x06, 0x6A, 0xB5, 0x3B, 0x7C, 0xBA, 0x03, 0xF3, 0x91, 0xB8, 0xB6, 0x3D, 0x8A, 0xC1, 0x48, 0x2E, 0x50, 0x11, 0xE7, 0xC7, 0x4F, 0xB1, 0x27, 0xCF, 0xF3, 0xAE, 0x03, 0x09, 0xB2, 0x08, 0xFB, 0xDC, 0x22, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00] #cipher
key="moectf2023"
s=""
for i in a:
s+=chr(i)
s=str(base64.b64encode(s.encode('utf-8')), 'utf-8')
rc4_main(key, s)这个甚至能重复利用,只需要把a、key替换就能反复利用了,原理也不介绍了,CTFwiki介绍的很清楚。
运行拿到flag:















 210
210











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









