







作者:
张晶(英特尔AI开发者布道策略经理)
张华乔 (VMware | Senior Engineer)
1.1 常见的EdgeAI应用程序框架
EdgeAI即常说的边缘智能,边缘智能包含两大核心功能:
- 边缘负责将现实世界的各种物理量数字化,然后整合数据,然后跟云端双向通信,例如,将温度、压力、位置等数字化后,整合信息上传并获得下行的命令
- 智能负责从原始的数据中抽取出有用的信息,例如,物体在视频中的位置和类别
边缘智能应用程序中常见的模块是EdgeX Foundry和OpenVINOTM工具包:
· EdgeX Foundry负责从边缘处的传感器(即“物”物)收集数据,并作为双向传输引擎向企业、云和本地应用发送数据,以及从这些应用接收数据。
· OpenVINO™️工具包负责在边缘端实现AI模型的推理计算,获得推理结果
EdgeX Foundry与OpenVINOTM工具包共同实现边缘智能的典型框架,如图1-1所示。
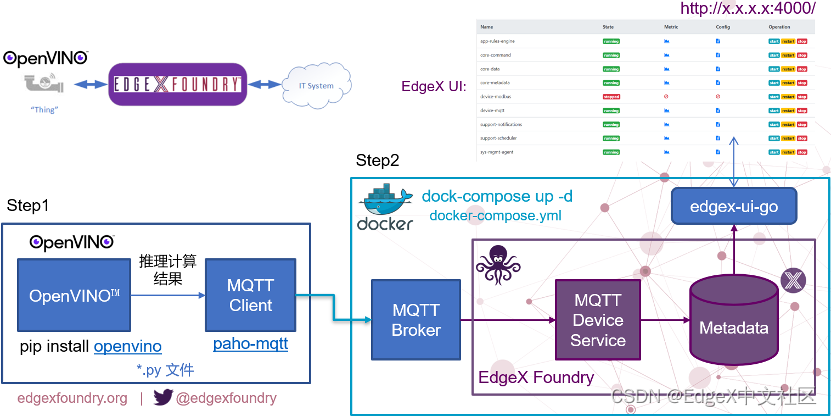
图1-1 边缘智能应用程序典型框架
1.1.1 EdgeX Foundry简介
EdgeX Foundry是LF Edge旗下的一款开源、不受供应商限制的边缘物联网中间件平台,负责从边缘处的传感器(即“物”物)收集数据,并作为双向传输引擎向企业、云和本地应用发送数据,以及从这些应用接收数据,如图1-2所示。

图1-2 EdgeX Foundry
在边缘智能应用中使用EdgeX Foundry的好处:
· EdgeX为设备数据引入、规范化及边缘智能 (AI/ML)提供可替换的参考服务
· EdgeX共享支持新型物联网数据服务和高级边缘计算应用
· EdgeX能加快完整边缘解决方案和/或边缘硬件解决方案的上市速度
1.1.2 OpenVINOTM 2022.1简介
OpenVINO™ 工具包开源且商用免费,用于深度学习模型优化和部署,如图1-3所示。
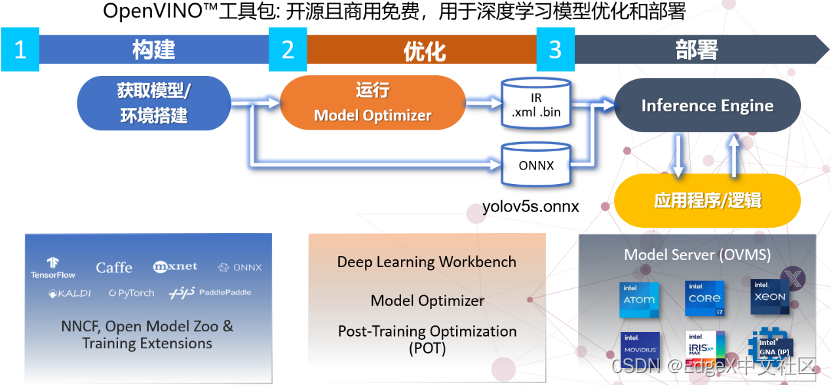
图1-3 OpenVINO™ 工具包
OpenVINO™ 工具包2022.1版于2022年3月22日正式发布,根据官宣《OpenVINO™ 迎来迄今为止最重大更新,2022.1新特性抢先看》,OpenVINO™ 2022.1将是迄今为止最大变化的版本。
从开发者的角度来看,对于提升开发效率或运行效率有用的特性有:
· 提供预处理API函数。OpenVINO™ 2022.1之前版本不提供OpenVINO runtime原生的用于数据预处理的API函数,开发者必须通过第三方库,比如,OpenCV,来实现数据预处理。OpenVINO™ 2022.1自带的预处理API可以将所有预处理步骤都集成到在执行图中,这样iGPU、CPU、VPU 或今后Intel的独立显卡都能进行数据预处理,大大提高了执行效率;相比之前,用OpenCV实现的预处理,则只能在CPU上执行,如图1-4所示。
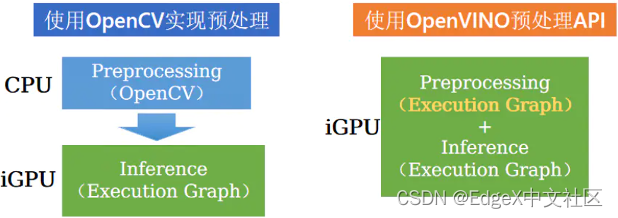
图1-4 OpenVINO预处理API
· ONNX前端API。前端API意味着模型可以直接被OpenVINO读入,而无需使用模型优化器进行模型转换,这对于使用 ONNX 模型的开发人员非常有用。OpenVINO™ 2022.1自动转换ONNX模型的速度(1.5秒以内)相比之前版本,有极大提升,开发人员已经感受不到ONNX模型自动转换的时间消耗了。
· AUTO 设备插件。AUTO设备插件自动将AI推理计算加载到最合适的硬件设备上(CPU, GPU, VPU等),无需额外的开发工作即可提高模型在异构系统中(例如:12代CPU + Iris Xe 集成显卡 + DG2 独显) 的推理性能和可移植性。
· 支持直接读入飞桨模型,如图1-5所示。
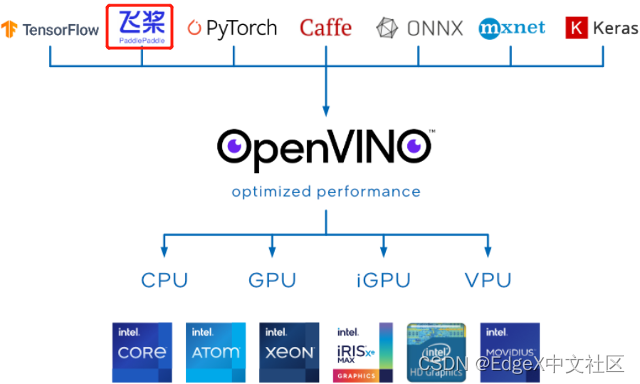
图1-5 OpenVINOTM支持的深度学习框架
为实现将OpenVINO™推理结果通过MQTT推送给EdgeX Foundry,本文将依次介绍:
- 使用 OpenVINO™ 开发YOLOv5模型推理程序
- 运行带ds-mqtt的EdgeX Foundry
- 在EdgeX UI中新建MQTT Device
- 将OpenVINO™推理结果推送给MQTT Broker
1.2 使用 OpenVINO™ 开发YOLOv5模型推理程序
1.2.1 YOLOv5简介
Ultralytics公司贡献的YOLOv5 PyTorch (https://github.com/ultralytics/yolov5)实现版,由于其工程化和文档做的特别好,深受广大AI开发者的喜爱,GitHub上的星标超过了23.8K,而且被PyTorch官方收录于PyTorch的官方模型仓。在产业实践中,也有无数的开发者将YOLOv5直接用于自己的项目。
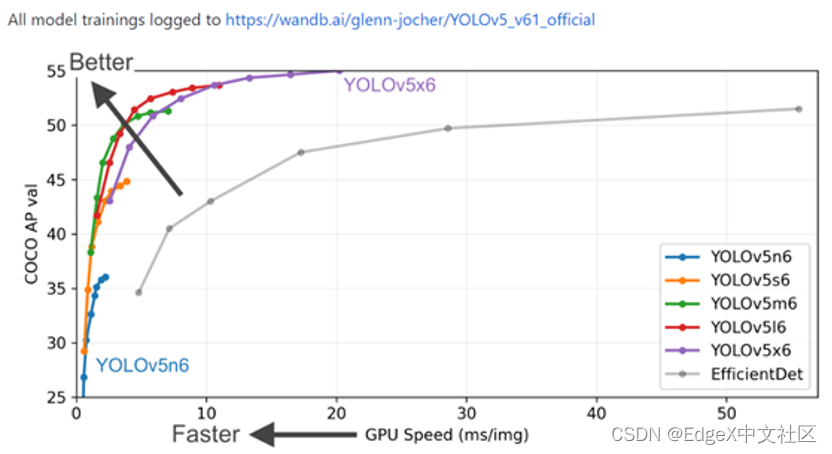
由于YOLOv5精度高速度快(最新的YOLOv5模型精度如下所示),使得产业界里面使用YOLOv5模型做产品和项目的人非常多。
另外,YOLOv5的工程化和文档化做的极好,没有任何基础的人,都可以在不到半天的时间内完成YOLOv5的开发环境搭建、模型训练、ONNX模型导出。
YOLOv5的文档链接:https://docs.ultralytics.com/
1.2.2 安装YOLOv5的OpenVINO™推理程序开发环境
要完成YOLOv5的OpenVINO™推理程序开发,需要安装:YOLOv5 + openvino-dev。
由于YOLOv5的工程化做的实在太好,在Windows10中安装上述环境,只需要两步。
· 第一步: git clone https://github.com/ultralytics/yolov5.git
· 第二步:在yolov5文件夹中,修改requirements.txt文件的25、30、34和35行如下所示。
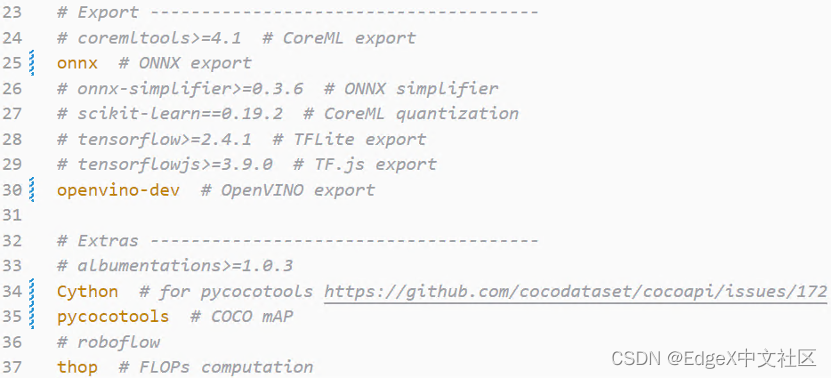
然后使用命令:
pip install -r requirements.txt
完成开发环境安装,如图1-6所示。

图1-6 安装YOLOv5和OpenVINOTM开发环境
1.2.3 导出YOLOv5 ONNX模型
在yolov5文件夹下,使用命令
python export.py --weights yolov5s.pt --include onnx
完成yolov5s.onnx模型导出,如图1-7所示。
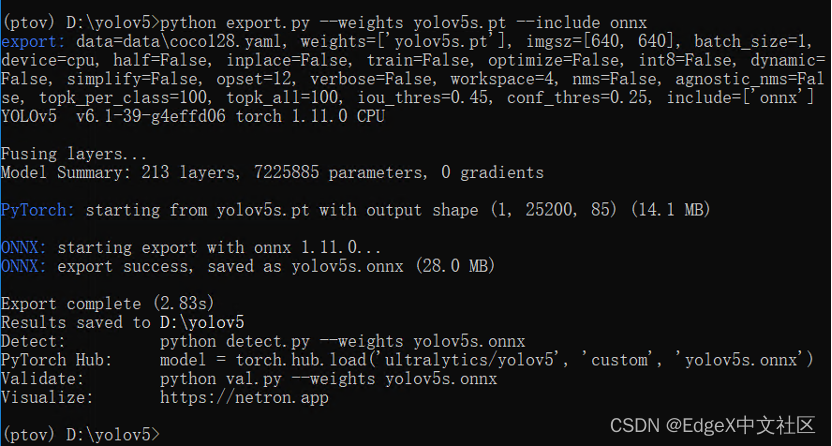
图1-7 导出YOLOv5s.onnx
1.2.4 用Netron工具查看YOLOv5s.onnx的输入和输出
使用Netron,查看YOLOv5s.onnx模型的输入和输出,如图1-8所示。
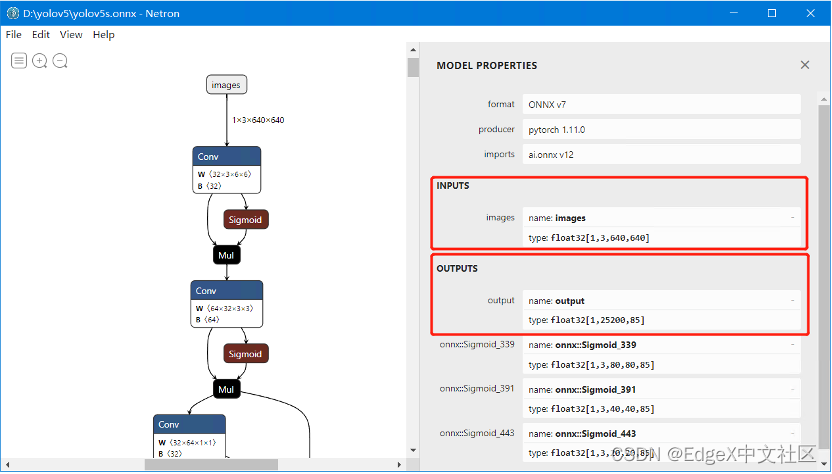
图1-8 查看YOLOv5s模型输入输出
从图中可以看出:YOLOv5 6.1版本之后,直接导出的ONNX格式模型会多出一个output层,这个output已经完全整合了之前三层的原始输出,再也不需要搞anchor的比率跟重新写解析后处理了,output出来每一行85个数值,前面5个数值分别是:
cx, cy, w, h, score, 后面80个参数是MSCOCO的分类得分
1.2.5 开发YOLOv5的OpenVINO™推理程序
使用OpenVINO™ 2022.1开发推理程序的典型步骤如下所示,从图1-9中可见,三行 OpenVINO API函数可以完成YOLOv5s.onnx模型的推理。
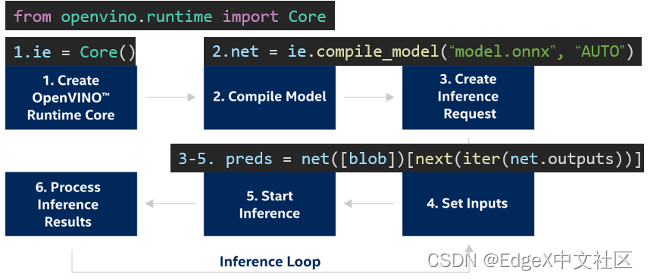
图1-9 OpenVINOTM推理程序开发步骤
完整范例程序如下:
# Do the inference by OpenVINO2022.1
from pyexpat import model
import cv2
import numpy as np
import time
import yaml
from openvino.runtime import Core # the version of openvino >= 2022.1
# 载入COCO Label
with open('./coco.yaml','r', encoding='utf-8') as f:
result = yaml.load(f.read(),Loader=yaml.FullLoader)
class_list = result['names']
# YOLOv5s输入尺寸
INPUT_WIDTH = 640
INPUT_HEIGHT = 640
# 目标检测函数,返回检测结果
def detect(image, net):
blob = cv2.dnn.blobFromImage(image, 1 / 255.0, (INPUT_WIDTH, INPUT_HEIGHT), swapRB=True, crop=False)
preds = net([blob])[next(iter(net.outputs))] # API version>=2022.1
return preds
# YOLOv5的后处理函数,解析模型的输出
def wrap_detection(input_image, output_data):
class_ids = []
confidences = []
boxes = []
#print(output_data.shape)
rows = output_data.shape[0]
image_width, image_height, _ = input_image.shape
x_factor = image_width / INPUT_WIDTH
y_factor = image_height / INPUT_HEIGHT
for r in range(rows):
row = output_data[r]
confidence = row[4]
if confidence >= 0.4:
classes_scores = row[5:]
_, _, _, max_indx = cv2.minMaxLoc(classes_scores)
class_id = max_indx[1]
if (classes_scores[class_id] > .25):
confidences.append(confidence)
class_ids.append(class_id)
x, y, w, h = row[0].item(), row[1].item(), row[2].item(), row[3].item()
left = int((x - 0.5 * w) * x_factor)
top = int((y - 0.5 * h) * y_factor)
width = int(w * x_factor)
height = int(h * y_factor)
box = np.array([left, top, width, height])
boxes.append(box)
indexes = cv2.dnn.NMSBoxes(boxes, confidences, 0.25, 0.45)
result_class_ids = []
result_confidences = []
result_boxes = []
for i in indexes:
result_confidences.append(confidences[i])
result_class_ids.append(class_ids[i])
result_boxes.append(boxes[i])
return result_class_ids, result_confidences, result_boxes
# 按照YOLOv5 letterbox Resize要求,先将图像长:宽 = 1:1,多余部分填充黑边
def format_yolov5(frame):
row, col, _ = frame.shape
_max = max(col, row)
result = np.zeros((_max, _max, 3), np.uint8)
result[0:row, 0:col] = frame
return result
# 载入yolov5s onnx模型
model_path = "./yolov5s.onnx"
ie = Core() #Initialize Core version>=2022.1
net = ie.compile_model(model=model_path, device_name="AUTO")
# 开启Webcam,并设置为1280x720
cap = cv2.VideoCapture(0)
# 调色板
colors = [(255, 255, 0), (0, 255, 0), (0, 255, 255), (255, 0, 0)]
# 开启检测循环
while True:
start = time.time()
_, frame = cap.read()
if frame is None:
print("End of stream")
break
# 将图像按最大边1:1放缩
inputImage = format_yolov5(frame)
# 执行推理计算
outs = detect(inputImage, net)
# 拆解推理结果
class_ids, confidences, boxes = wrap_detection(inputImage, outs[0])
# 显示检测框bbox
for (classid, confidence, box) in zip(class_ids, confidences, boxes):
color = colors[int(classid) % len(colors)]
cv2.rectangle(frame, box, color, 2)
cv2.rectangle(frame, (box[0], box[1] - 20), (box[0] + box[2], box[1]), color, -1)
cv2.putText(frame, class_list[classid], (box[0], box[1] - 10), cv2.FONT_HERSHEY_SIMPLEX, .5, (0, 0, 0))
# 显示推理速度FPS
end = time.time()
inf_end = end - start
fps = 1 / inf_end
fps_label = "FPS: %.2f" % fps
cv2.putText(frame, fps_label, (10, 25), cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 0, 255), 2)
print(fps_label+ "; Detections: " + str(len(class_ids)))
cv2.imshow("output", frame)
if cv2.waitKey(1) > -1:
print("finished by user")
break
上述范例程序下载链接:https://gitee.com/ppov-nuc/yolov5_infer/blob/main/infer_by_openvino2022.py
运行效果如下所示:
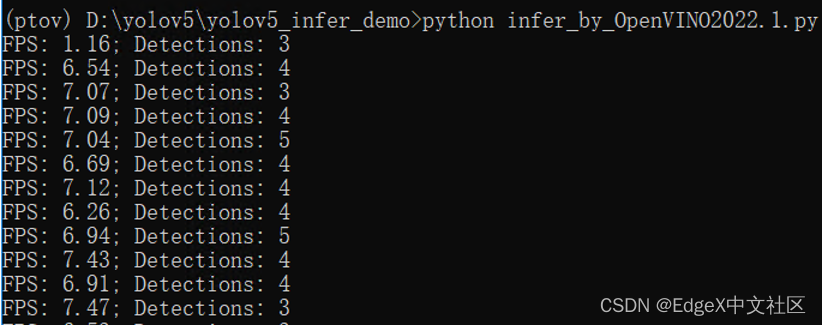
到此,完成了使用 OpenVINO™ 开发YOLOv5模型推理程。
1.3 运行带ds-mqtt的EdgeX Foundry
首先,请安装好docker和docker-compose。本文的运行环境是:Ubuntu20.04.4 LTS + Intel® i5-1135G7。
然后,请克隆edgex-compose代码仓到本地,使用命令:
git clone https://github.com/edgexfoundry/edgex-compose.git
运行结果,如图1-10所示。
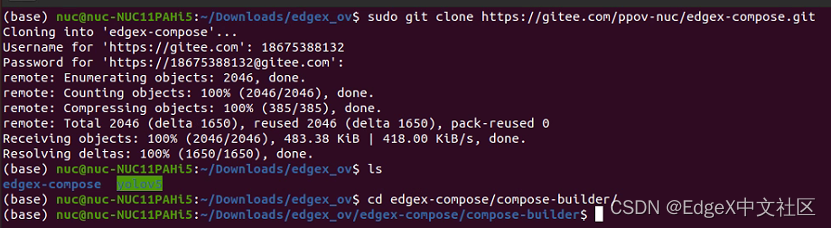
[图1-10 克隆edgex-compose代码仓
接着,在compose-builder目录下运行命令:
make gen no-secty ds-mqtt mqtt-broker
生成edgex 的docker compose文件,如图1-11所示。
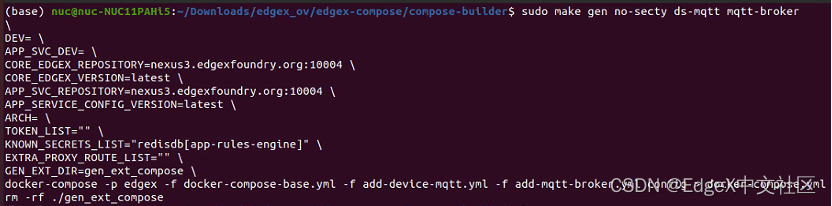
图1-11 生成docker compose文件
最后,在compose-builder目录下运行命令:
docker-compose up -d
启动带有MQTT Broker的EdgeX Foundry,如图1-12所示。
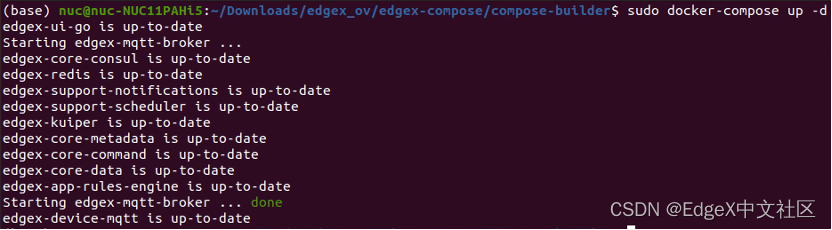
图1-12 启动带有MQTT Broker的EdgeX Foundry
到此,成功启动带有MQTT Broker的EdgeX Foundry。
1.4 在EdgeX UI中新建MQTT Device
为了简化MQTT device profile的编写过程,请先克隆张华乔老师的mock-device-driver代码仓到本地,使用命令:
git clone https://github.com/badboy-huaqiao/mock-device-driver.git
1.4.1 添加device profile
第一步,启动EdgeX UI。EdgeX UI是一个图形化的EdgeX 管理工具,在浏览器中,输入localhost:4000; 然后在Device Profile中,点击“Add”按钮,如图1-13所示。
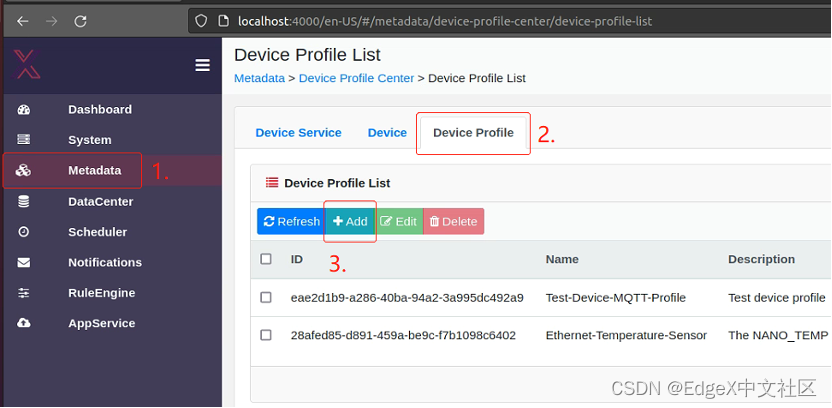
图1-13 启动EdgeX UI
第二步,在mock-device-driver/jakarta-v2.1.0文件夹下,有一个test-mqtt-profile.yml文件,请将该文件拖入“Add Profile”框,然后点“Submit”按钮,完成mqtt device profile的添加,如图1-14所示。
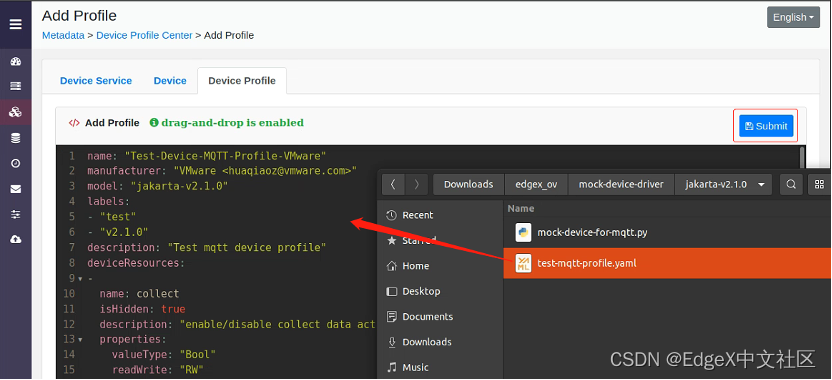
图1-14 添加test-mqtt-profile.yml文件
1.4.2 新增一个名为“edgex_ov”的设备
第一步,在“Device”页面,点击“Add”按钮,如图1-15所示。
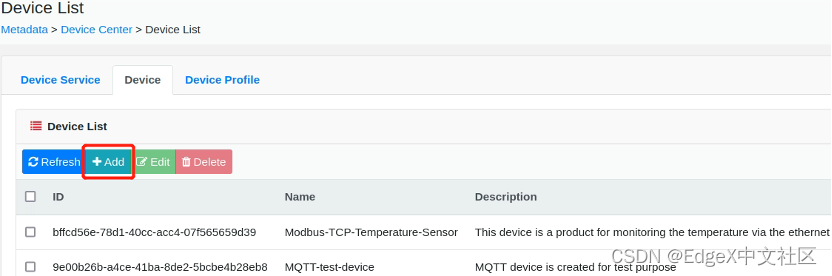
图1-15 点击“Add”按钮
第二步,勾选“device-mqtt”,并按“Next”按钮,如图1-16所示。
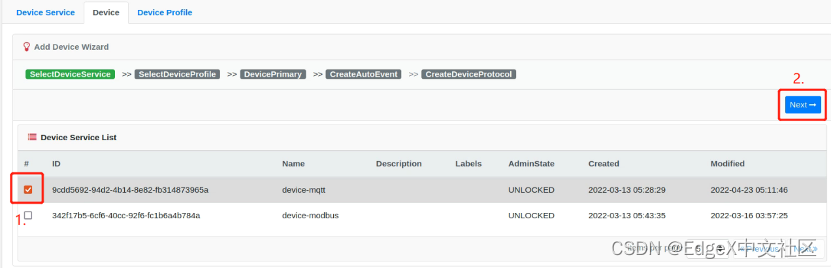
图1-16 勾选“device-mqtt”
第三步,勾选“Test-Device-MQTT-Profile-VMware”,并按“Next”按钮,如图1-17所示。
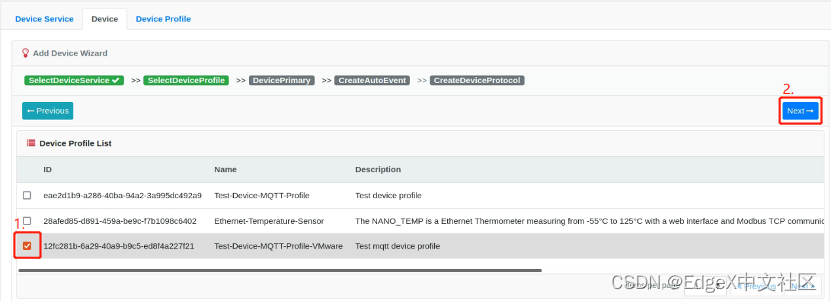
图1-17 勾选“Test-Device-MQTT-Profile-VMware
第四步,填写“Name”和“Description”,并按“Next”按钮,如所示。

图1-18 填写“Name”和“Description”
第五步,在“Add More AutoEvent”页面,按“Skip”按钮,跳过该设置。
第六步,在“CreateDeviceProtocol”页面,填写Protocol信息,然后按“Submit”按钮,完成名为“edgex_ov”的MQTT设备添加,如图1-19和图1-20所示。
· Protocol Name: device-mqtt
· Schema:tcp
· Host:0.0.0.0
· Port:1883
· User:huaqiaoz
· Password:1234
· ClientId: 123
· CommandTopic: CommandTopic
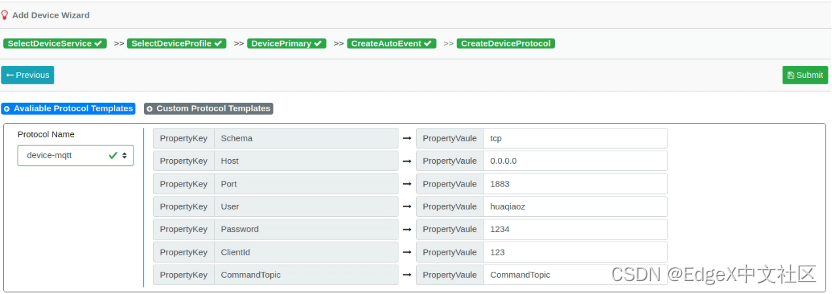
图1-19 填写Protocol信息
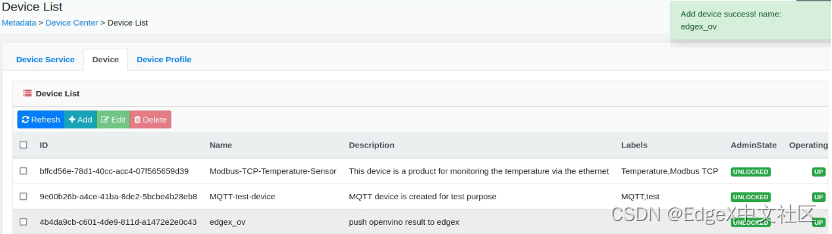
图1-20 成功添加名为”edgex_ov”的MQTT设备
1.4.3 运行mock-device-for-mqtt.py测试添加的设备
添加了MQTT设备后,使用mock-device-for-mqtt.py的Python脚本来测试通讯是否正常,如图1-21所示。
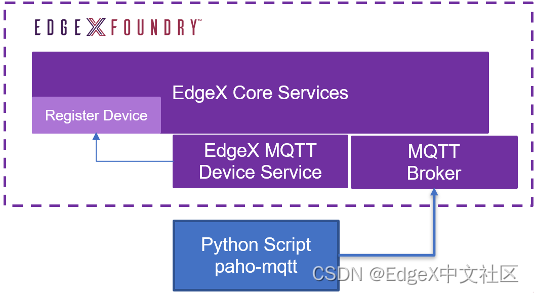
图1-21 Python脚本与EdgeX的通信构架
第一步:请先安装paho-mqtt,参考:https://pypi.org/project/paho-mqtt/。
第二步:在mock-device-driver/Jakarta-v2.1.0文件夹下,运行命令,如图1-22所示。
python mock-device-for-mqtt.py

图1-22 运行mock-device-for-mqtt.py
第三步:在EdgeX UI中,“Device”页面,选择testcollect,然后在“Set”部分,选择“true”,最后点击“try”按钮,可以使能设备,如图1-23所示。
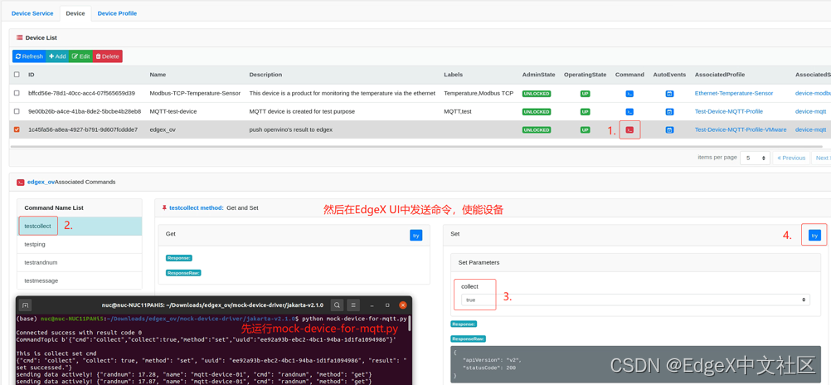
图1-23 使能设备
第四步:运行testmessage命令,可以获得如图1-24所示结果。结果显示EdgeX获得了Python脚本发出的“Are you ok?”信息,新添加的“edgex_ov”MQTT设备工作正常。
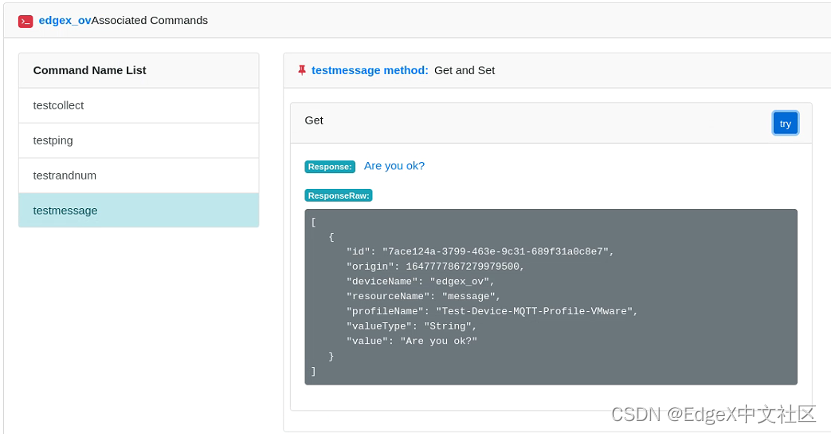
图1-24 运行testmessage命令
1.5 将OpenVINO™推理结果推送给MQTT Broker
将mock-device-for-mqtt.py中的on_message()函数,更新为OpenVINO的推理结果,如图1-25所示。
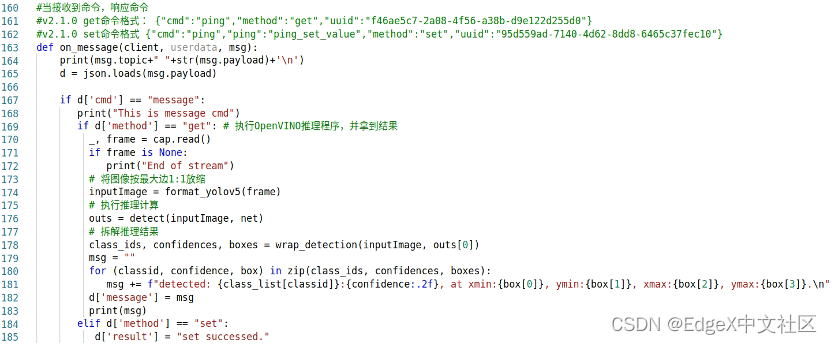
图1-25 修改on_message()函数
完整范例代码参见:
https://gitee.com/ppov-nuc/yolov5_infer/blob/main/openvino2022-device-for-mqtt.py
同样,参考1.4.3节,运行openvino2022-device-for-mqtt.py,可以在EdgeX UI上,获得OpenVINO推理结果,如图1-26所示。
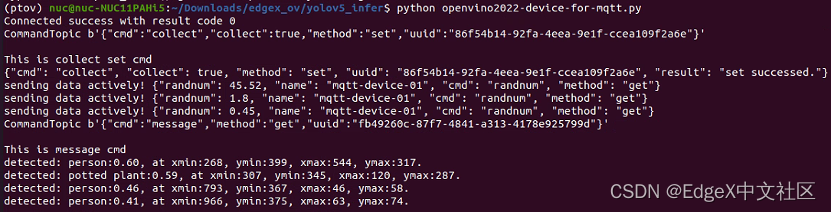
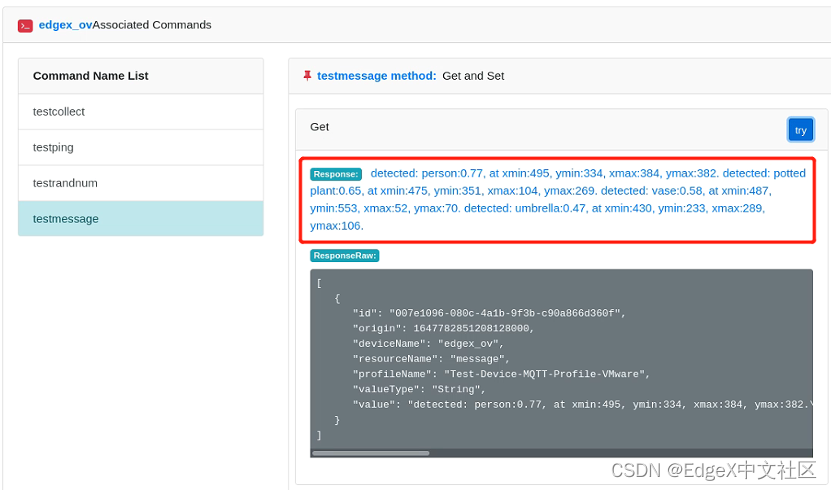
图1-26 openvino2022-device-for-mqtt.py运行结果
到此,将OpenVINOTM推理结果通过MQTT推送给EdgeX Foundry介绍完毕。
1.6 总结
基于EdgeX Foundry和OpenVINOTM工具包可以很方便的实现边缘智能,整个流程如图1-27所示。
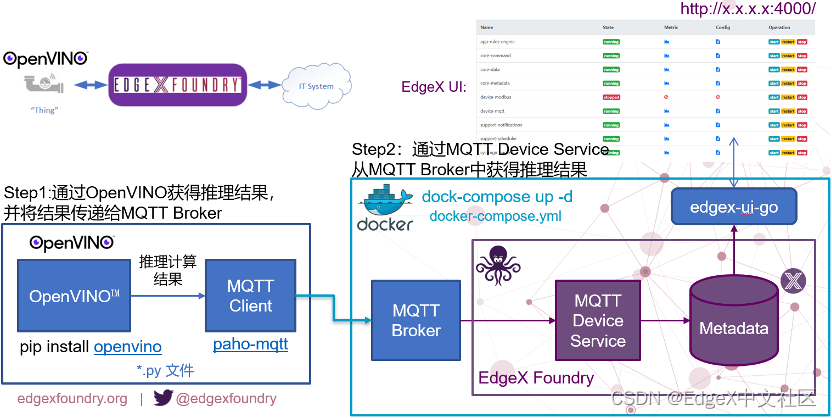
图1-27 将OpenVINOTM推理结果通过MQTT推送给EdgeX Foundry的完整流程
参考资料:
• YOLOv5模型: https://github.com/ultralytics/yolov5
• YOLOv5推理程序:https://github.com/doleron/yolov5-opencv-cpp-python
• OpenVINO推理范例:https://gitee.com/ppov-nuc/yolov5_infer
• Mock Device范例:https://github.com/badboy-huaqiao/mock-device-driver
• OpenVINO APIs: https://docs.openvino.ai/latest/notebooks/002-openvino-api-with-output.html
• https://docs.openvino.ai/latest/openvino_docs_Integrate_OV_with_your_application.html#doxid-openvino-docs-integrate-o-v-with-your-application














 3681
3681











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









