







一、 DPDK的由来
随着互联网的快速发展,基础计架构网络逐渐向给予通用计算平台或模块化平台架构变迁,以便支撑多样化的网络功能。系统方面的解决方案也由几年前的集群化部署转向虚拟化部署再转向分布式计算,我们可以发现早期的C10K问题已经可以通过多种架构方式解决,而整体架构变迁说明在解决了处理性能瓶颈之后更多会关注:应用处理,也就是我们说的业务层面的东西。
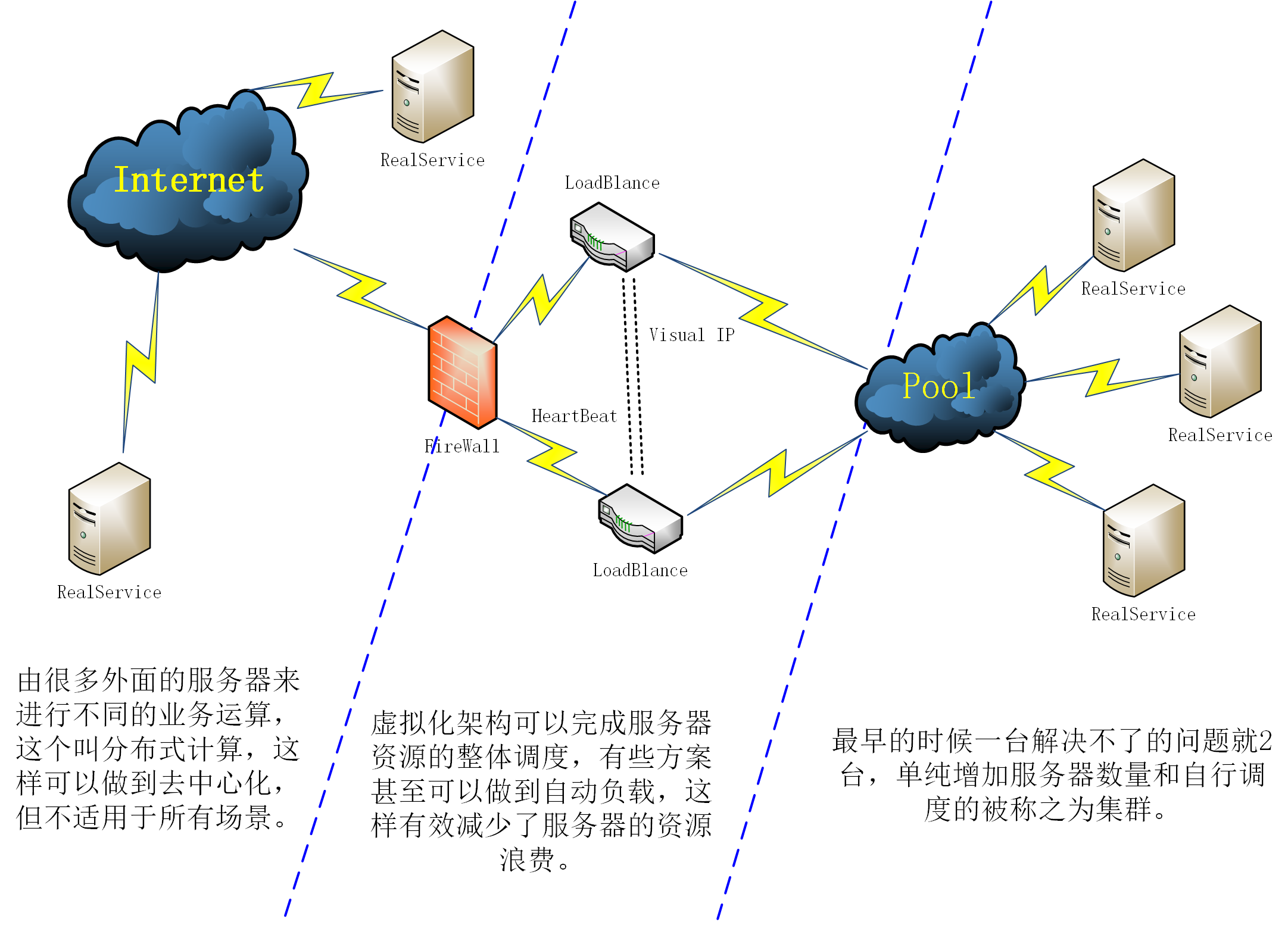
分布式加虚拟化用于解决计算量不同的业务无疑是之后平台架构的首选方案,并且考虑到分布式部署会有大量的嵌入式设备,这些设备本身很难被集群化管理,那必然需要高效的网络处理性能,这个就有用了。数据平面开发套件(DPDK Data Plane Development Kit)是由6WIND,Intel等多家公司开发,主要基于Linux系统运行,用于快速数据包处理的函数库与驱动集合,可以极大提高数据处理性能和吞吐量,提高数据平面应用程序的工作效率。
它可以支持IBM POWER系列和ARM系列的处理器,用于数据包脱离系统层能够快速转发和处理。
为什么它可以更快?


先抛开内核处理性能问题不考虑,Linux因为要支持上层多种应用的需求,所以在当初系统设计的时候就在协议栈中增加了大量的用于应用层对接的接口,但是单纯想要处理数据收/发的话,显然不需要走到协议栈这么深的地方,DPDK架构就给出了这么一个方案:
传统网络数据处理流程:
硬件中断--->取包分发至内核线程--->软件中断--->内核线程在协议栈中处理包--->处理完毕通知用户层
用户层收包-->网络层--->逻辑层--->业务层
使用DPDK之后的处理流程:
硬件中断--->放弃中断流程
用户层通过设备映射取包--->进入用户层协议栈--->逻辑层--->业务层
DPDK的优势:
减少了中断次数。
减少了内存拷贝次数。
绕过了linux的协议栈,进入用户协议栈,用户获得了协议栈的控制权,能够定制化协议栈降低复杂度
DPDK的劣势
低负荷服务器不实用,会造成内核空转。
内部运行原理如下图所示:
拦截中断,不触发后续中断和流程流程,绕过协议栈,通过UIO能够重设内核中终端回调行为从而绕过协议栈后续的处理流程

以往的用户层处理网络数据需要进行内存拷贝到用户区进行,使用DPDK之后只需要在内核空间进行内存的控制权转移即可。

关于内存整理

Linux在内存管理中采用受保护的虚拟地址模式,在代码中地址分为3类:逻辑地址、线性地址、物理地址。程序使用具体内存简单说就是逻辑地址通过 分段机制映射转化为线性地址,然后线性地址通过 分页机制映射转化为物理地址的过程,而在实际使用中,仅将线性地址映射为物理地址的过程中,需要从内存中读取至少四次页目录表(Page Directory)和页表 (Page Table),为了加快内核读取速度,CPU在硬件上对页表做了缓存,就是TLB。
线性地址先从TLB获取高速缓存内存,如果不存在就从内存表获取,如果有直接的映射,直接从内存读取,没有则产生缺页中断(这也就是为什么会因为没有连续内存就会产生相关进程建立不起来的原因),从新分配物理内存,或者从硬盘上将swap读取。具体图示如下:

4K的页表是linux针对一般情况得出的合适大小,然而对于特殊应用可以通过扩大页表面积提高内存使用效率。
dpdk使用hupage的思想就是让程序尽量独占内存防止内存换出,扩大页表提高hash命中率,通过hugage技术扩大了该使用的页表大小,设定为更适合高频内存使用程序的状态,获得了以下几点优势。
无需交换。也就是不存在页面由于内存空间不足而存在换入换出的问题
减少TLB负载。
降低page table查询负载
NUMA
为了解决单核带来的CPU性能不足,出现了SMP,但传统的SMP系统中,所有处理器共享系统总线,当处理器数目越来越多时,系统总线竞争加大,系统总线称为新的瓶颈。NUMA(非统一内存访问)技术解决了SMP系统可扩展性问题,已成为当今高性能服务器的主流体系结构之一。
NUMA系统节点一般是由一组CPU和本地内存组成。NUMA调度器负责将进程在同一节点的CPU间调度,除非负载太高,才迁移到其它节点,但这会导致数据访问延时增大。下图是2颗CPU支持NUMA架构的示意图,每颗CPU物理上有4个核心。dpdk内存分配上通过proc提供的内存信息,使cpu尽量使用靠近其所在节点的内存,避免访问远程内存影响效率。

内核管理模块
Affinity是进程的一个属性,这个属性指明了进程调度器能够把这个进程调度到哪些CPU上。在Linux中,我们可以利用CPU affinity 把一个或多个进程绑定到一个或多个CPU上。CPU Affinity分为2种,soft affinity和hard affinity。soft affinity仅是一个建议,如果不可避免,调度器还是会把进程调度到其它的CPU上。hard affinity是调度器必须遵守的规则。为什么需要CPU绑定?
增加CPU缓存的命中率
CPU之间是不共享缓存的,如果进程频繁的在各个CPU间进行切换,需要不断的使旧CPU的cache失效。如果进程只在某个CPU上执行,则不会出现失效的情况。在多个线程操作的是相同的数据的情况下,如果把这些线程调度到一个处理器上,大大的增加了CPU缓存的命中率。但是可能会导致并发性能的降低。如果这些线程是串行的,则没有这个影响。
适合time-sensitive应用在real-time或time-sensitive应用中,我们可以把系统进程绑定到某些CPU上,把应用进程绑定到剩余的CPU上。典型的设置是,把应用绑定到某个CPU上,把其它所有的进程绑定到其它的CPU上。
核管理结构
dpdk启动时会建立会分析系统的逻辑核属性建立映射表并统一管理,每个核主要属性如下.
每个核属性包括逻辑核id, 硬核id, numa节点id。dpdk会根据系统默认状态生成一一绑定的映射表,用户可以根据需求更改映射表,后续dpdk框架会根据该映射表进行核绑定。
class core{
lcore_id; //逻辑核id
core_id; //硬核id
socket_id; //NUMA节点id
}
class core coremap[ ] //所有逻辑核的映射表
多核调度框架
服务器启动时选取一个逻辑核做主核然后启动其他核做从核
所有线程都根据映射表做核绑定
控制核主要完成pci,内存,日志等系统的初始化
从核启动后等待主核初始化完毕后挂载业务处理入口
从核运行业务代码

多核配置通过Core_Mask来进行,配置方式类似:network mask ,将你需要使用的core 配置到相应的节点,并且转换成16进制表示。
热更新
DPDK在多线程管理上隔离性相当好,主核和从核通过管道进行命令交互,主核可以轻松的将业务下发给从核,因此可以很容易的利用这个特点做业务接口热更新支持。
底层转发
如下图所示,大部分程序交互时是在传输层及以上,但DPDK从二层切入,在构建集群需要大规模转发数据时可以使用三层转发,这样将使数据包转发降低1层协议栈的开销。

参考文献:
大佬:https://www.jianshu.com/p/0ff8cb4deae
官方:http://pktgen-dpdk.readthedocs.io/en/latest















 461
461

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









