







目录
前言:
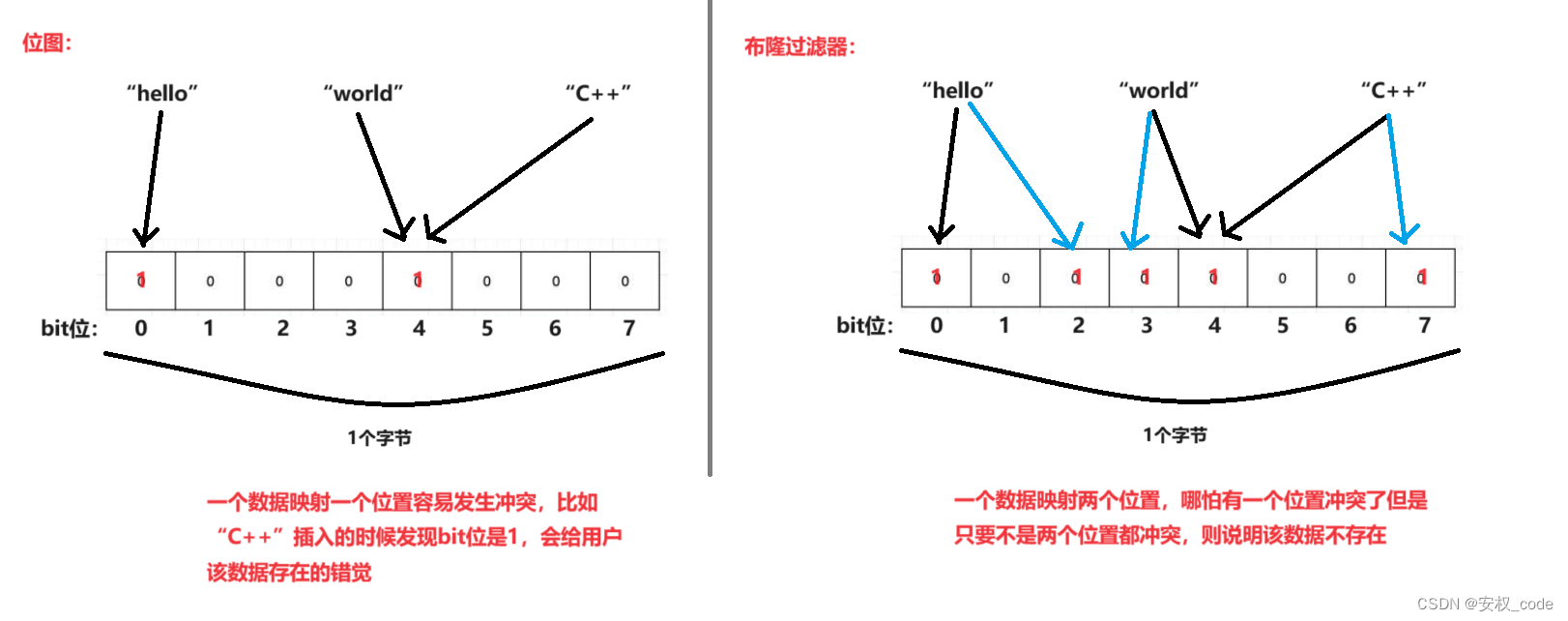
布隆过滤器是一种概率型数据结构,采用的是哈希思想,他在位图的原有基础上做了升级,因为位图处理不了数据为字符串的情况,而布隆过滤器可以。布隆过滤器的作用是能够快速的判断某个数据存在与否,他也是通过哈希函数找到映射在位图上的位置,但是位图只映射一个位置,而布隆过滤器能够映射多个位置,这也是布隆过滤器和位图的区别所在。
1、布隆过滤器的用法
哈希表能够处理多种类型的数据,但是哈希表所占空间过大,因此推出位图概念,但是位图所处理的数据过于单一,因此又推出布隆过滤器的概念,虽然布隆过滤器也是在bit位上进行操作的,但是布隆过滤器记录一个数据时用了多个哈希函数映射,因此布隆过滤器发生冲突的概率比较小。
布隆过滤器具体示意图如下:
2、布隆过滤器的查找
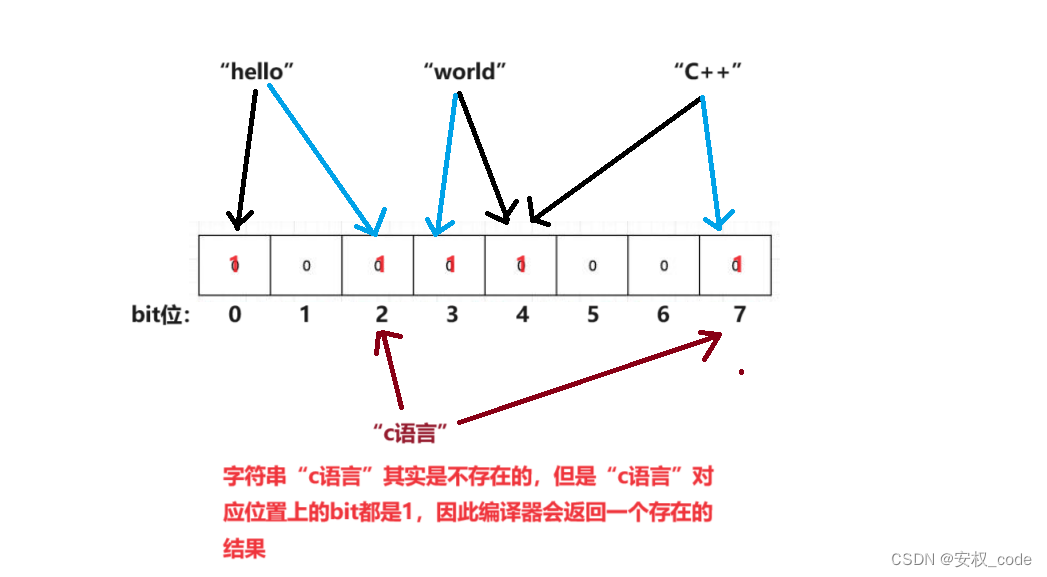
布隆过滤器是通过多个哈希函数进行映射位置的,并且每个数据映射到的位置都会被置为1,那么查找一个数据时会出现两种情况:
1、只要查找的数据对应的映射位置里有一个bit位是0,说明该数据不存在。
2、若查找的数据对应的映射位置里都是1,那么该数据可能存在也可能不会存在,但是编译器会返回一个存在的结果给到用户(误判)。
误判的示意图如下:
3、布隆过滤器的删除
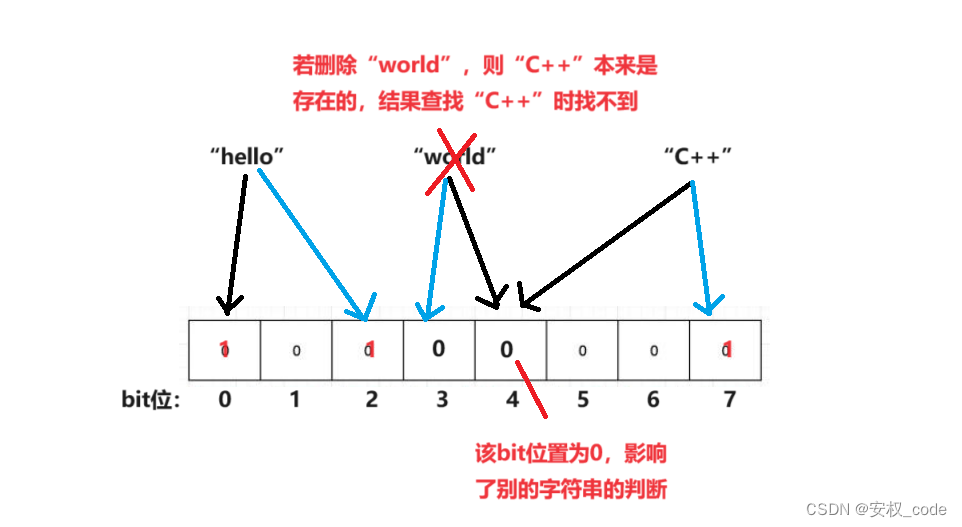
布隆过滤器是不支持删除操作的,因为从上文的叙述中可以得出,若有两个数据的bit位重复了,如果把一个数据删除,那么该数据的bit位肯定要置为0,但是该bit位的变动影响了其他数据。
具体示意图如下:
4、布隆过滤器的实现
实现代码如下:
#define _CRT_SECURE_NO_WARNINGS 1
#include<iostream>
#include<string>
#include<vector>
using namespace std;
template<size_t N>
class bitset//位图
{
public:
bitset()
{
_bits.resize(N / 8 + 1, 0);//位图的大小和初始化
}
void set(size_t x)
{
size_t i = x / 8;
size_t j = x % 8;
_bits[i] |= (1 << j);//或-只要有一个为1结果就为1
}
void reset(size_t x)
{
size_t i = x / 8;
size_t j = x % 8;
_bits[i] &= ~(1 << j);//或-只要有一个为0结果就为0
}
bool find(size_t x)
{
size_t i = x / 8;
size_t j = x % 8;
return _bits[i] & (1 << j);//_bits[i]为1说明该数据存在
}
private:
vector<char> _bits;//位图其实是一个char类型的vector
};
struct BKDRHash//哈希算法1
{
size_t operator()(const string& s)
{
size_t hash = 0;
for (auto ch : s)
{
hash += ch;
hash *= 31;
}
return hash;
}
};
struct APHash//哈希算法2
{
size_t operator()(const string& s)
{
size_t hash = 0;
for (size_t i = 0; i < s.size(); i++)
{
size_t ch = s[i];
if ((i & 1) == 0)
{
hash ^= ((hash << 7) ^ ch ^ (hash >> 3));
}
else
{
hash ^= (~((hash << 11) ^ ch ^ (hash >> 5)));
}
}
return hash;
}
};
struct DJBHash//哈希算法3
{
size_t operator()(const string& s)
{
size_t hash = 5381;
for (auto ch : s)
{
hash += (hash << 5) + ch;
}
return hash;
}
};
// N最多会插入key数据的个数
template<size_t N,
class K = string,
class Hash1 = BKDRHash,
class Hash2 = APHash,
class Hash3 = DJBHash>
class BloomFilter
{
public:
void set(const K& key)
{
size_t len = N * _X;
//得到三个映射位置
size_t hash1 = Hash1()(key) % len;
_bs.set(hash1);
size_t hash2 = Hash2()(key) % len;
_bs.set(hash2);
size_t hash3 = Hash3()(key) % len;
_bs.set(hash3);
}
bool find(const K& key)
{
size_t len = N * _X;
//检查三个位置是否都为1
size_t hash1 = Hash1()(key) % len;
if (!_bs.find(hash1))
{
return false;
}
size_t hash2 = Hash2()(key) % len;
if (!_bs.find(hash2))
{
return false;
}
size_t hash3 = Hash3()(key) % len;
if (!_bs.find(hash3))
{
return false;
}
return true;
}
private:
static const size_t _X = 4;//_X越大,则开的bit位越多,越不容易出现误判
bitset<N* _X> _bs;//期望位图开N* _X个bit位
};
int main()
{
BloomFilter<100> bs;
//映射数据
bs.set("sort");
bs.set("bloom");
bs.set("hello world!!");
bs.set("qwer");
//查找数据
cout << bs.find("sort") << endl;
cout << bs.find("bloom") << endl;
cout << bs.find("hello world!!") << endl;
cout << bs.find("qwer") << endl;
cout << bs.find("abcd") << endl;
return 0;
}运行结果:
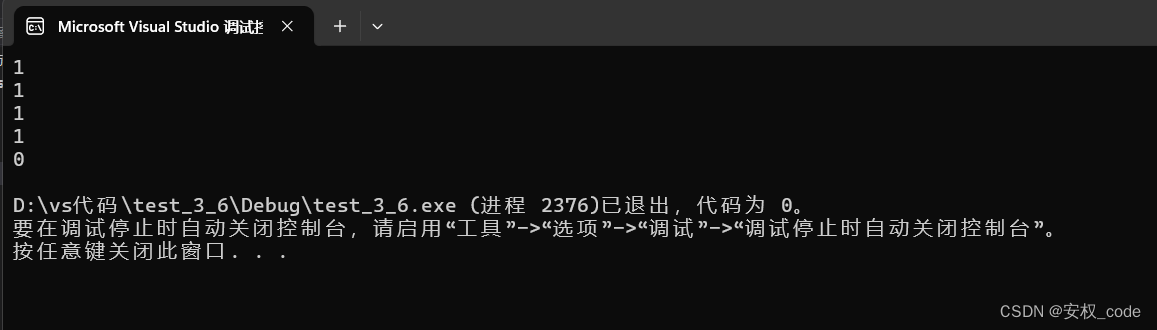
结语
以上就是关于布隆过滤器的讲解,布隆过滤器本质上还是运用了位图的基础,只不过在此基础上进行了升级,布隆过滤器的优势在于可以使用相对较小的空间去判断大量的数据存在与否,这是其他数据结构所做不到的,当然布隆过滤器要承受一部分误判的风险。
最后希望本文可以给你带来更多的收获,如果本文对你起到了帮助,希望可以动动小指头帮忙点赞👍+关注😎+收藏👌!如果有遗漏或者有误的地方欢迎大家在评论区补充,谢谢大家!!
















 303
303











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











