







本文是对斯坦佛大学,李飞飞团队写的《Deep Visual-Semantic Alignments for Generating Image Descriptions》的实验验证,所有源代码均下载于
https://github.com/karpathy/neuraltalk
可能会出现一些差错,敬请指正。鞠躬~
理论知识基础:
http://www-cs-faculty.stanford.edu/people/karpathy/deepimagesent/
一、数据集介绍
在本文的实验中,我们使用Flickr8K,Flickr30K和COCO数据集,这些数据集分别包含8000,31000和123000张图片,并且每一张都使用Amazon Mechanical Turk的5个句子来作注释。对于Flickr数据集,他是雅虎发布的一个巨大的数据集,这个数据集由1亿张图片和70万个视频的URL以及与之相关的元数据(标题、描述、标签)所组成,这是一个相当可观的资源,实验使用Flickr8K和Flickr30K中的1000张图片做验证,1000张图片做测验,剩下的来做训练。而对于COCO来讲,实验使用5000张图片既做验证又做测试。
二、训练阶段
本文的实验按照Karpathy在github上对neuraltalk所发布的源代码进行研究,根据实验介绍,实验所需要的平台为python和NumPy,NumPy系统是专为python开发的一种开源的数值计算扩展,他可以用来存储和处理大型矩阵,比python自身的嵌套列表结构要高效得多,它提供了许多高级的数值编程工具,例如矩阵数据类型、矢量处理以及精密的运算数据库。
实验的主要内容可以分为以下三块:1、训练阶段,2、预测阶段,3、用自己的图片生成描述。我们将在下面的内容中具体介绍我们所做的工作。
1、训练阶段
在训练阶段,图片作为递归神经网络的输入,而递归神经网络被要求用来预测整个句子的单词,他通过神经网络的隐藏层,来根据之前的文本信息预测当前的单词。
在准备阶段,实验需要下载python2.7,因为相比原有版本,python自带了pip管理器,包管理器pip能够更方便快捷的安装各种包,然后通过pip安装我们所需要的NumPy或者SciPy,argparse模块,argparse模块是python标准库中推荐使用的编写命令行程序的工具,他可以解析命令行参数、生成帮助等。由于实验所用的电脑是win7旗舰版,并不是Linux操作系统下的,所以在安装上跟Karpathy有所差别,这是在训练模型前所需要做的准备工作。
我们从github上下载源代码后,还需要得到实验训练所需要的图片数据库,如前所介绍,我们的模型使用Flickr8K、Flickr30K和COCO数据集,我们从相应的网站上下载他们的原始图片,以及经过卷积神经网络后得到的特征文件,并按照说明存入data文件夹。
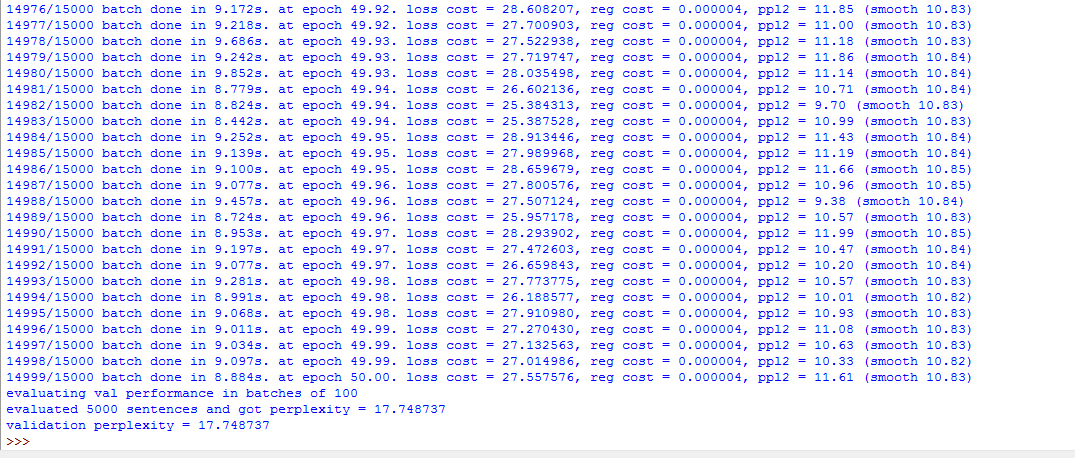
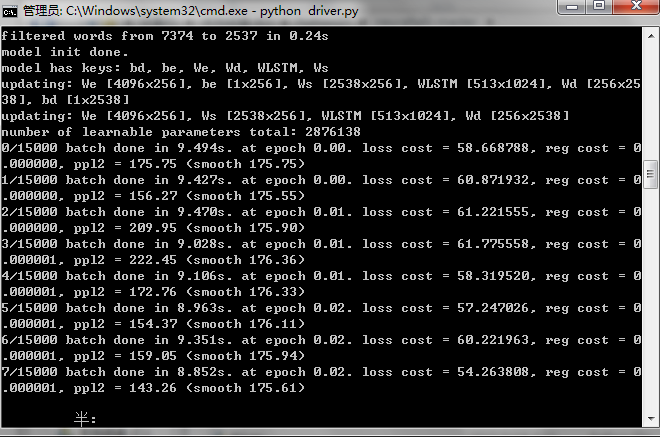
第二步我们运行训练模型的driver.py文件。在对python设置好路径后,我们在cmd中直接输入python driver.py命令,或者直接在python shell中F5运行,它会自动调用data文件夹下的Flickr8K文件,将里面的JSON文件作为输入,训练数据集中的15000张图片,并且该程序被设置成每300张图记录一次,在cv文件夹下生成checkpoint的p文件,由于电脑配置为CPU,并不是GPU,因此在训练时间上,耗时较长,每张图都需要训练9秒左右的时间,因此15000图共训练了将近40多个小时,生成了17个checkpoint文件。程序运行情况以及生成状态情况如下图所示:
同时,因为会在cv文件夹下生成许多checkpoint,所以为了方便观察训练情况,模型还能实时生成训练的状态文件保存在status文件夹下,如下图所示,JSON文件会随着生成情况随时改变:
我们在cmd中输入python –m SimpleHTTPServer 8123命令,并打开本地浏览器http://localhost:8123/后打开monitorcv.html,会出现此时checkpoint点的生成情况,监控情况如下图所示:
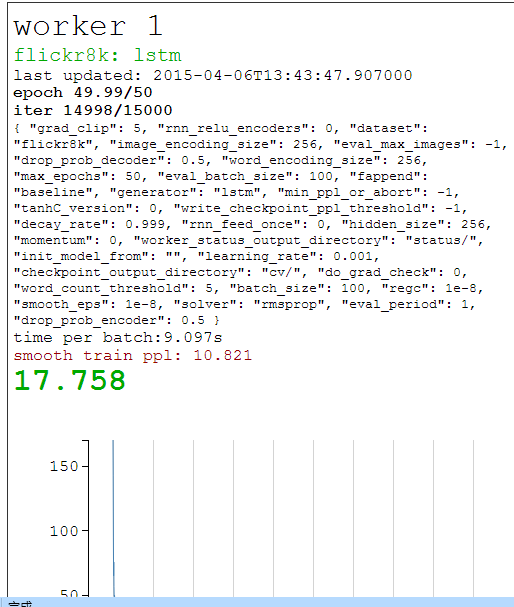
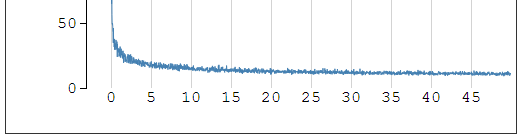
在monitorcv.html中,可以监控得到很多信息,比如冲量大小,阈值大小,保存checkpoint的文件夹名以及生成所需的时间值等,当生成过程出现错误时,可以通过监控的网页立即看出错误点。
2、测试阶段
在训练阶段,本文通过对Flickr8K下的图片库作为输入,得到了所需要的checkpoint文件,在测试阶段,我们需要评估cv文件夹下的checkpoint的正确率,按照实验所要求的,运行eval_sentence_predictions.py程序,并且在cmd中输入python eval_sentence_predictions.py “cv\model_checkpoint_Flickr8K_YingTianXing-PC_baseline_17.32.p”后,在默认的文件夹下会生成result_struct.JSON文件,按照上述方法打开本地浏览器的visualize_result_struct.html,这个网页能够可视化数据库中的图片以及生成相应的描述。生成的结果如下图:
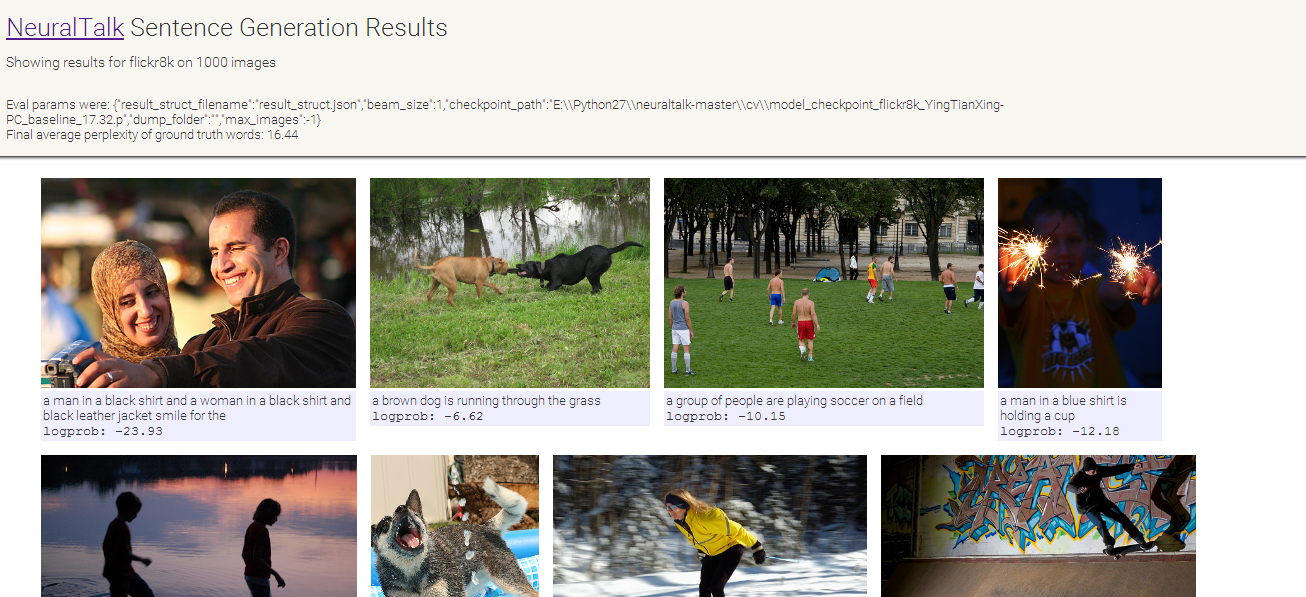
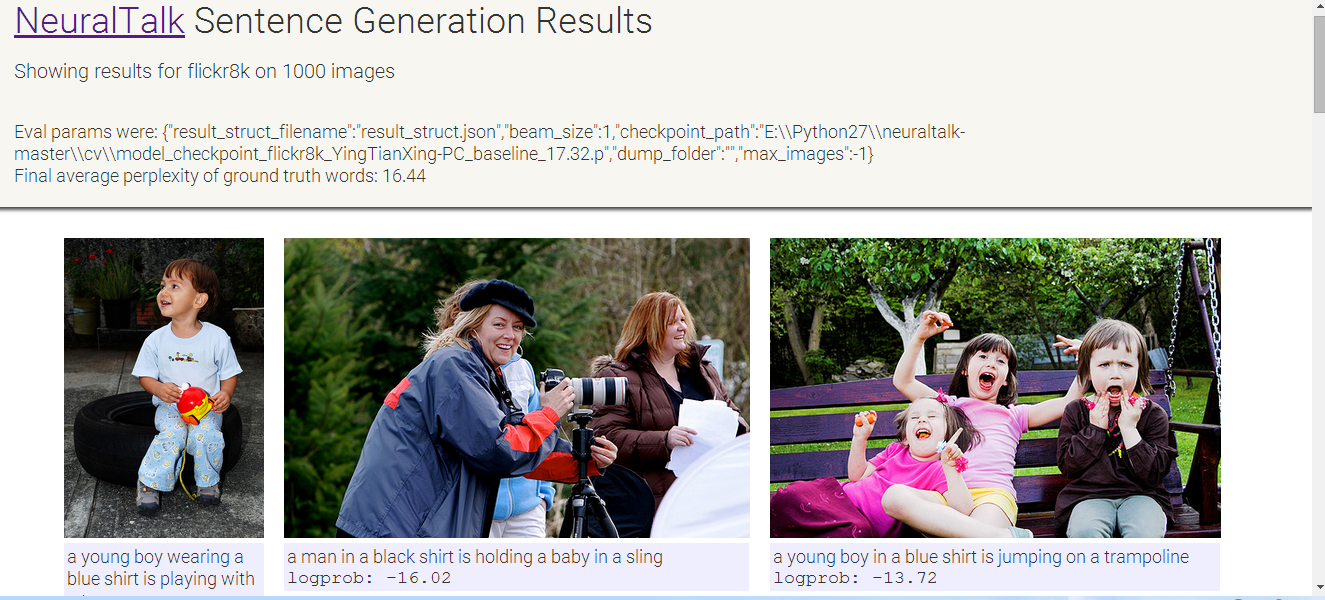
3、自己的图片生成描述
在之前的两步中,实验的图片来源是Flickr8K数据库等现有的图片,而在这一节中,我们将使用自己的图片来生成描述,来看下机器对于我们自己的图片有着怎样的理解。
按照Karpathy的理论,本文使用伯克利大学的贾清扬博士开发的cafffe结构框架,以及他的matlab接口,而caffe model我们则选择牛津大学的karen Simonyan和Andrew Zisserman共同开发的VGG net的16层模型。这个模型的主要贡献在于他对网络深度的增加进行了一个严格的验证,结果显示当网络的深度增加到16-19层时,将会有一个显著地提高,这是相比之前那些网络模型所达不到的深度。并且为了减少参数数量,VGG团队对所有卷积层使用了非常小的3*3的滤波器。经过不断改进,他们的VGG network在2014年的ImageNet ILSVRC比赛中取得了第一名的成绩,并且他们的16层模型将前五类错误率减少到了7.5%,这是非常惊人的成就,而本文的实验中,则选择了VGG团队的caffe模型,来生成实验所需要的特征值,我们按照教程装好caffe以及第三方库后,在matlab上编译实验所需要的端口,需要注意的是,为了准确生成自己图片的特征,需要提前新建example_images文件夹,并且将所需要提取特征的图片放在该文件夹下,实验通过运行matlab脚本来提取所需要的CNN特征,同时由于脚本文件需要用到tasks.txt,我们还需要把所有自己图片的名称统一放在tasks.txt文本中,运行脚本所需时间由于CPU和GPU的差异有所不同,但是他都会生成CNN特征提取文件vgg_feats.mat文档。我们在cmd命令框中输入python predict_on_images.py cv\model_checkpoint_flickr8k_YingTianXing-PC_baseline_17.32.p -r example_images命令后,回车能够发现在文档中会生成result.html文件,这个html文件是用来在本地浏览器中显示我们自己图片的描述信息的。按照之前所述方法,打开本地浏览器后,能够发现如下界面:


以上,我们通过实验验证了深度可视化语义表述和图像描述。本文全部原创,对于试验中出现的肖像权,我不负任何责任(摊手),不服你们来打我咯~
转载请注明出处,虽然我有预感这个压根就不会有人读hhhh。














 1251
1251











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









