






 本文探讨了开放域段落检索中的对比冲突问题,提出一种名为DSCR的模型,通过上下文句子级表示和段落内负采样策略,有效缓解冲突,提高检索的相关性。方法分析了现有框架的不足,并通过实验验证了其在改善一对多问题上的效果。
本文探讨了开放域段落检索中的对比冲突问题,提出一种名为DSCR的模型,通过上下文句子级表示和段落内负采样策略,有效缓解冲突,提高检索的相关性。方法分析了现有框架的不足,并通过实验验证了其在改善一对多问题上的效果。
Sentence-aware Contrastive Learning for Open-Domain Passage Retrieval
论文链接:https://arxiv.org/pdf/2110.07524v3.pdf

Abstract
现有研究侧重于通过改进负采样策略或额外的预训练来进一步优化。然而,这些研究在从不正确的建模粒度中捕获具有内部表示冲突的段落方面仍然未知。
本文工作提出了一个基于更小粒度、上下文句子的改进模型,以缓解相关冲突。详细地:引入了一种段落内负采样策略,以鼓励在同一段落中生成不同的句子表示。
Introduction
开放域段落检索(Open-Domain Passage Retrieval ODPR)提供了一个由数百万段落组成的极其庞大的文本语料库,旨在检索最相关段落的集合作为给定问题的证据。
DPR (Karpukhin et al., 2020) 采用了一种简单但有效的对比学习框架,无需任何预训练即可获得令人印象深刻的性能。具体来说,对于每个问题 q,由 BM25 产生的几个正面段落 p+ 和硬负面段落 p- 被预先提取。通过向 Bi-Encoder 提供 (q, p+, p−) 三元组,DPR 同时最大化 q 的表示与对应的 p+ 之间的相似性,并最小化 q 的表示与所有 p− 之间的相似性。
DPR 中对比学习框架的目标是最大化问题的表示与其对应的黄金段落之间的相似性。
如图 2 所示,在对比冲突下,当前的对比学习框架会无意中最大化来自同一段落的不同问题表示之间的相似性,即使它们在语义上可能不同,这正是 SQuAD 性能低下的原因。
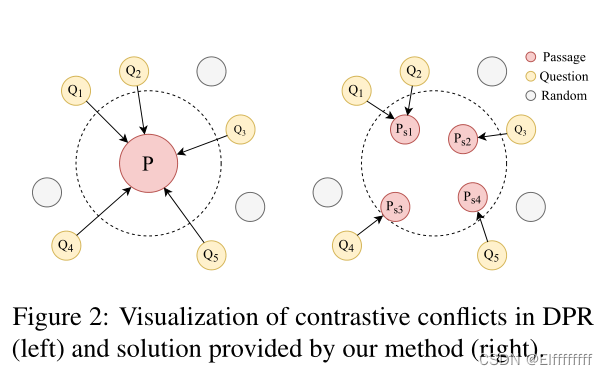
然而,一个段落可能是多个问题的正面段落 p+(即问题集 Q)。因此,较大的batch大小会增加 Q 的某些问题可能出现在同一batch中的概率.
因此本文提出了一种简单但有效的策略,将密集的段落表示分解为上下文句子级别的表示,称为密集上下文句子表示 (DCSR)。并不是简单地分别对每个句子进行编码。相反,将文章作为一个整体进行编码,并使用句子指示符来获取文章中的句子表示,以保留上下文信息。进一步介绍了段落内负采样策略,该策略在同一段落中对正句的相邻句子进行采样,以创建硬负样本。
Related Work
Open-Domain Passage Retrieval
Contrastive Learning 对比学习的研究路线可以分为两类:
(i)改进正样本和硬负样本的采样策略
(ii) 改进对比学习框架
本文提出的方法遵循第二条研究路线。研究了对比学习框架中的一种特殊现象,即对比冲突,并通过以更小的粒度建模 ODPR 来实验验证调解此类冲突的有效性。
Methods
Contrastive Learning Framework
现有的对比学习框架旨在最大化每个问题的表示与其对应的黄金段落之间的相似性。
n 个问题,n 个对应的黄金段落,总共有 k 个硬否定段落
原始 DPR 的每个问题样本 qi 的训练目标如公式(1)所示:
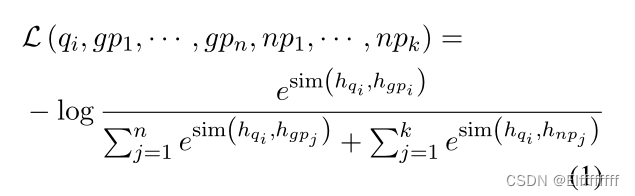
sim(·) 可以是计算问题表示 hqi 和段落表示 hpj 之间的相似性的任何相似性算子。
最小化公式1等于(i)最大化每个 hqi 和 hgpi 对之间的相似性,以及 (ii) 最小化 hqi 与所有其他 hgpj (i ≠ j) 和 hnpk 之间的相似性相同。
Dense Contextual Sentence Representation
对比冲突的原因在于一对多问题,大多数段落通常由多个句子组织,而这些句子可能并不总是坚持同一个主题,如图 1 所示。因此,建议对段落进行建模以更小粒度(即上下文句子)进行检索,以减轻一对多问题的发生.
由于上下文信息在段落检索中也很重要,简单地将段落分解为句子并独立编码是不可行的。
在每个段落的句子边界处插入一个特殊的 <sent> 标记,并将整个段落编码为保留上下文信息,这导致每个段落的输入格式如下:
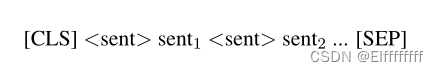
通过这些指示符 <sent> 标记获取上下文句子表示。
给定查询 q,将训练批次中相应的肯定段落表示为 p+,它由几个句子组成:
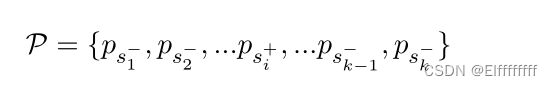
同样,将相应的 BM25 否定段落表示为:
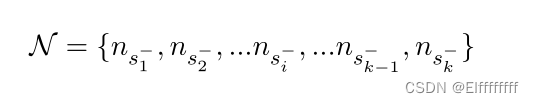
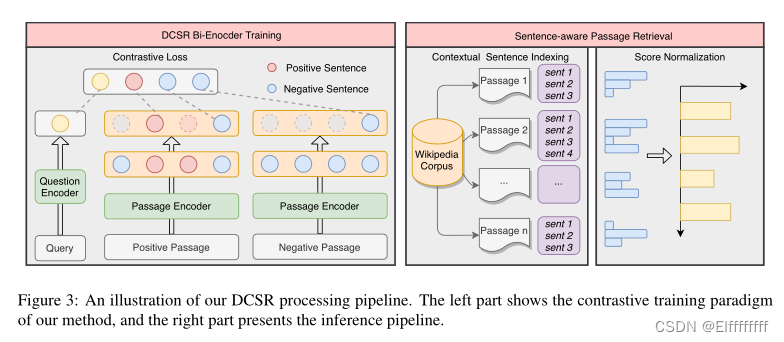
训练流程如图 3 左侧所示。
Positives and Easy Negatives
使用 BM25 来检索每个问题的硬否定段落。并从 BM25 随机否定段落中随机抽取几个负句。
引入批量负片作为额外的简单负片。
In-Passage Negatives
引入段落中的否定词,以最大化同一段落中上下文句子表示之间的差异。
Retrieval
首先使用 FAISS (Johnson et al., 2019) 来计算问题与所有上下文句子索引之间的匹配分数。
由于一个段落在索引中有多个key,本文检索前 100 × k(k 是每个段落的平均句子数)上下文句子进行推理。为了将这些句子级别的分数更改为段落级别的分数,采用概率设计来对段落进行排名,将其称为分数归一化(首先使用 Softmax 操作将所有这些相似性分数归一化为概率。假设一个段落 P 有几个句子 s1, s2, ..., sn,并将每个包含答案的句子的概率表示为 ps1, ps2, ..., psn,可以计算答案在段落 P中的概率由公式 2 得出的。)。
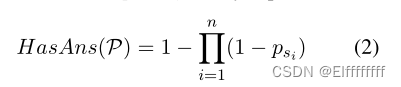
然后,通过 HasAns(P) 对所有检索到的段落重新排序,并在接下来的实验中选择前 100 个段落进行评估。
Conclusion
在本文中,对当前开放域段落检索中的对比冲突问题进行了深入分析。为了很好地解决这个问题,通过仔细生成句子感知的正负样本,提出了一种增强的句子感知冲突学习方法。

















 893
893

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









