







以 ChatGPT 为代表的大型语言模型(LLM)在各项任务上的高效表现彰显了其广阔发展前景。然而,大模型回复与人类价值偏好经常存在不一致问题。
如何让大模型更好的与人类价值观对齐,理解语言背后的含义,生成更具 “人情味” 的内容成为大语言模型研究的热点。最近,复旦大学自然语言处理(FudanNLP)团队桂韬、张奇课题组在这一技术难题上取得巨大进展!该团队深入研究了大模型的基于人类反馈的强化学习 (Reinforcement Learning from Human Feedback, RLHF) 细节,为大模型人类对齐训练提供了更加稳定可靠的解决方案。
此外,该团队在开源领域迈出重要一步 —— 首次同时发布大模型人类对齐技术报告与开源核心代码 ,为推动中文 NLP 社区繁荣做出重大贡献。

大模型人类对齐面临挑战
未经人类对齐的大模型常常生成有害内容,存在安全性方面的隐患,直接影响大模型的落地。实现人类对齐的大模型通常需要满足 3H 条件:Helpful(有益),Honest(诚实),Harmless(无害)。当前,达成这一目标的重要技术范式是基于人类反馈的强化学习(RLHF)。然而受限于实验设计困难、试错成本巨大等多重因素,RLHF 的稳定训练仍然是一个难题。
OpenAI 此前公布的 InstructGPT 技术报告中将 PPO(Proximal Policy Optimization,近端策略优化)算法作为 RLHF 阶段的强化学习算法。然而其并未开源训练技术细节,且 PPO 算法在过去通常被应用于自动化、游戏等领域,其在自然语言处理(NLP)领域的具体作用仍需大量实验验证,但当前国内并没有一项完整的工作探究 PPO 的稳定训练及其在大模型人类对齐中的影响。面对这一技术挑战,研究人员迫切需要进一步探索 PPO 算法对大模型人类对齐的作用机理。
确定大模型人类对齐的关键因素,提高对齐的训练稳定性
FudanNLP 团队通过大量、详实工作,设计实验充分探索了大模型 RLHF 的完整工作流程,仔细剖析了 RLHF 中的强化学习 PPO 算法的内部工作原理以及它在整个 RLHF 中的作用,并研究各种优化方法如何影响训练过程。通过这些努力,确定了使得 PPO 算法在大模型人类对齐方面行之有效的关键因素。
综合上述发现,该团队进一步总结出在大模型上训练更稳定的 PPO 算法版本:PPO-max。并使用 Helpful 和 Harmless 数据集全面评估,结果显示经过 PPO-max 算法训练的模型展现出了出色的人类对齐性能!
经人类对齐后大模型安全伦理表现优异
经过人类对齐训练后的 RLHF 模型相对 SFT(Supervised Fine-Tuning,监督微调)模型的性能表现如下图所示。该研究采取人工评测和 GPT-4 评测两种方式,人工评测基于参与评测人员对于不同模型输出的偏好,而在 GPT-4 评测过程中,该研究要求 GPT-4 生成详细的评测理由,这将使得最终的结果更加公平。
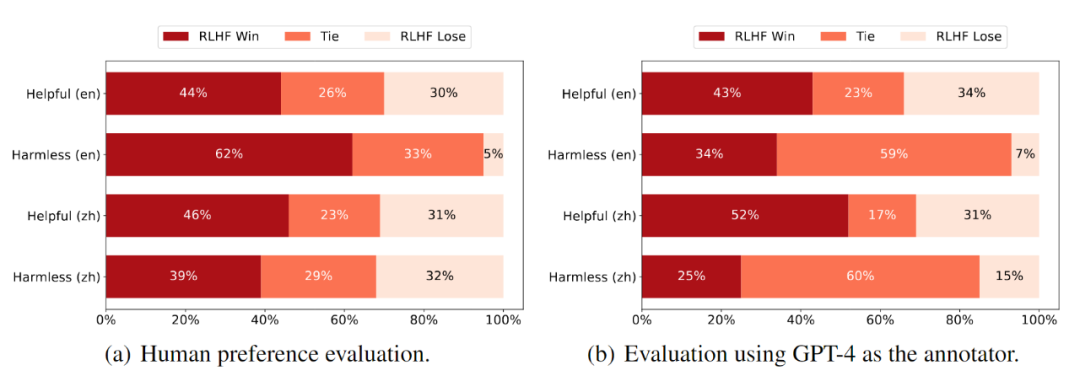
人工评测:评测人员在中文和英文两种类型的问题上,均更倾向于 RLHF 模型的输出。具体来说,RLHF 模型在英文 Harmless 数据集上优势显著,人工评测得分为 62%,而 SFT 模型的得分为 5%。这表明,经过 RLHF 训练的语言模型极大地提高了其面对各种有害性问题时的处理能力,包括个人隐私、政治敏感话题以及种族群体提问中带有歧视、偏见的提示。此外,在 Helpful 数据集上也可以观察到一定程度的提升:RLHF 模型的评分为 44%,而 SFT 模型的评分为 30%。这表明,SFT 模型也可以从 RLHF 优化训练中受益。人工评测的结果同时验证了 RLHF 训练能够提高 SFT 模型在中文 Helpful 和 Harmless 数据集上的性能。
GPT-4 评测:GPT-4 是目前为止性能最强的语言模型,先前的研究结果显示,引入 GPT-4 进行端到端自动化评测可以提供相对公平的结果。如上图所示,该研究观察到其评测结果和人工评测之间有着密切相似之处,尽管 GPT-4 产生了比人工评测更多的平局打分,但 RLHF 模型继续在 Harmless 数据集上表现出显着优势,这种表现趋势在中文 Harmless 数据集上也很明显。值得注意的是,与人工评测相比,在 GPT-4 评测下, RLHF 模型在中文 Helpful 数据集上相对 SFT 模型也有显著的改进。
项目主要作者 FudanNLP 组博士生郑锐补充到:"在开展 RLHF 项目的过程中,我们发现 PPO 算法是模型稳定训练的关键,而 RM (reward model) 的质量决定了模型性能的上限,在本次开源的 RM 基础上,我们也将继续努力探索如何构造更高质量的 RM。"
人类价值观对齐
使用 PPO-max 算法训练的模型与人类价值观实现了有效的对齐,模型落地更安全。
【例 1】:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











