







swap
接上文,在swap函数中,参数ap和bp寻址到某两块内存,对两块内存里的值进行了交换。swap过程的本质,就是交换两块内存中存放的位模式,而且隐式地知道交换的字节大小。如果想让swap具有通用性,交换任意类型的值,可以使用通用类型void *,如Program. 1:
Program. 1. 返回通用的void*类型
void* swap(void *vp1, void *vp2)
{
void temp = *vp1; //error 2
*vp1 = *vp2;
*vp2= temp;
}但这种写法有两个问题。一是不能将变量temp声明为void类型;二是不能对vp1进行解引用,因为机器不知道要提取多少字节,所以需要第三个参数显示地声明需要交换的值的大小。另外还需要一个临时的字符串,改进后的通用swap如Program. 2 :
Program. 2. generic swap function
void* swap(void *vp1, void *vp2, int size)
{
char buffer[size];
memcpy(buffer, vp1, size);
memcpy(vp1, vp2, size);
memcpy(vp2, buffer, size);
}临时字符串没有固定位模式和大小,而是动态申请一个内存块buffer,将其作为temp使用,使用完再释放掉。动态申请和释放一个内存块,可以在调用swap函数并传入长度时采用sizeof(int)的方式,that’s the way the client has to interact with this generic function right here(调用者与通用函数交互的方式)。swap最终只会关心内存块和bit pattern的交换。比如Program. 3:
Program. 3. 使用C语言中的swap“泛型”
int x = 17, y = 37;
swap(&x, &y, sizeof(int));
double d = pi, e = e; //just pretend it makes sense
swap(&d, &e, sizeof(double));在C++中,我们通常采用swap模板,编译后的模板和我们定义的C语言中的swap泛型,生成的是同样的机器码。但区别在于,模板首先会根据不同的类型设定进行扩展,形成int的swap,double的swap,float的swap…扩展成很多独立的版本后,compile them in the int specific domain or the double int specific domain。问题随之而生,每调用一次就扩展一个版本再编译,如果在一个规模很大的代码库中调用swap的话,将生成很多本质相同version不同的可执行代码。
虽然C++模板提供的泛型在执行时进行了扩展导致冗余,但是我们自定义的C语言的swap泛型更加不可靠,即使它更加“简单、经济适用”。因为swap函数只需传入两个地址(需要交换内容)和一个长度(要交换的内容大小),放宽了编译标准,却增加了运行风险:
Jerry: The problem is there are so many mistakes that can be make when you are dealing with a generic function like this. Swap is pretty easy in the grand scheme of things but we’ll see in a second, that it’s actually easy to get the call wrong and for the compiler to tell you nothing at all, because it’s very easy to be a void *. Okay? You can pass in the address of a float, the address of a double and pass in 32 right here. It’s not going to work very nicely when you actually run it, but it will compile.”
void*和强制类型转换可以让编译器镇定下来,使其总是能编译通过,但执行起来就没那么幸运了。编译器的工作应当是在代码编译阶段去edit and coach you as much as possible。但当我们为了扩展去使用这种“C中的泛型”以及强制类型转换的时候,其实是在告诉编译器不要在编译阶段做太多工作,从而导致代码在运行时承担了更多的风险。
为了说明我们自定义的swap在运行时承担的风险,Jerry给出了例子Program. 4:
Program. 4. Disaster in Big-endian System
int i=44;
short s=5;
swap(&i, &s, sizeof(short));Program. 4总会编译通过,在Little-endian中也能得到正确的结果,在大端系统中则会出现如下问题:
Figture. 1. Disaster in Big-endian System
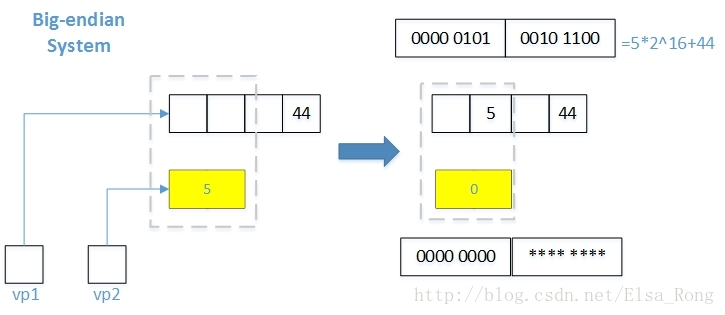
备注:Fig. 1中位模式的展开图画错了,应该是4 byte,我只画了2 byte,5*2^16+44的计算过程是正确的。
函数调用时,两个合法地址和一个长度值使得代码能够被编译通过,没能及时阻止问题的发生。如果将sizeof(short)改为sizeof(int),甚至会导致崩溃。
Q&A:Program. 2 中为什么不使用*vp1,*vp2
如果在memcpy中使用*vp1和*vp2,就是尝试对void*进行解引用,尝试使用vp地址对应的小房子中的字节,导致不能访问到该地址对应的所有的字节。有些编译器也对void*解引用设置了警告。
为了进一步说明swap中不对地址解引用的原因,Jerry给出了一个例子:
Program. 5. swap对指针解引用导致的困境
char *husband = strdup("Fred");
char *wife = strdup("Wilma");
swap(&husband, &wife, sizeof(char*)); //传入地址,在swap里解析成指向该地址的指针
swap的本质就是传入两个指针和一个长度,husband和wife已经是指针了,是不是直接传入husband和wife就可以了?答案是否。我们需要交换husband和wife表示的内存块中的内容,所以需要传入的是指向husband和wife的指针,也就是husband和wife的地址;同时,husband和wife表示的内存块中保存的是char*类型的值,所以应当为sizeof传入char*。
Figture. 2. swap(&husband, &wife, sizeof(char*))

如果在交换时传错了参数,比如swap(husband, wife, sizeof(char*)),因为husband和wife本身是指针,在swap内部,将会执行对两个指针指向的值直接交换,也就是对husband和wife指向的值直接接环,就会出现下面的问题:
Figure. 3. swap(husband, wife, sizeof(char*))
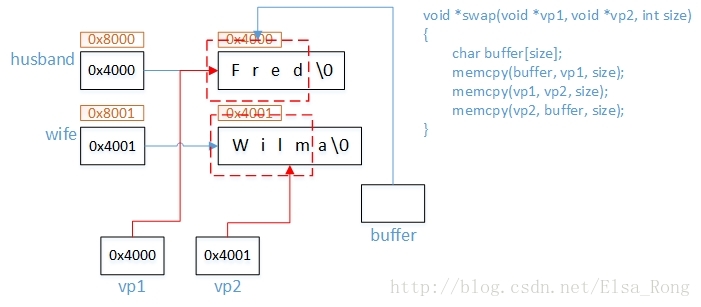
我有两个地址,我要交换4字节的布局,然后a就被单独留下来了,husband和wife的值却没有被改变。因为传入了错误的参数,我们访问了不想访问到的东西。因此,Jerry告诫我们在处理泛型时,要格外小心编码方式,它们很强大也,很危险。
L search
第二个例子,对数组从前到后进行查找,如果找到值为key的位置就返回坐标,如果没有找到则返回-1。
Program. 6. L search
int lsearch(int key, int array[], int size)
{
for (int i=0; i<size; i++) {
if (array[i] == key) { //generic
return i;
}
}
return -1;
}为了实现泛型(generic),重写lsearch函数。for循环是通用的,需要重写if(array[i]==key),这里实际上是指针的算数运算*(array+i),一个隐式的“*”。两个等号比较的是按位层次上的两个4字节位模式(a bit wise comparison of the two 4-byte),在这里进行通用化,使其不仅能处理int类型,that means that I have to pass in more information, more variables than I’m actually passing in right here。
以array[3]为例,它从数组的基地址开始,偏移3*sizeof(int)个字节,如果int array[]变成void *,就相当于我们失去了隐式的指针算数运算。因为我们无法对void*进行指针算数运算,就像我们不能对它解引用一样。
Program. 7. the generic version of L search
void *lsearch(void *key, void *base, int n, int elemSize)
{
for(int i=0; i<n; i++)
{
void *elemAddr = (char*)base + i*elemSize;
if(memcmp(key, slemAddr, elemSize) == 0)
return elemAddr;
}
return NULL;
}line 5的本质就是取得基地址偏移指定量的内存块,但是有两处需要注意。一是编译器只知道要偏移多少个元素i,不知道每个元素的大小,也就是每个元素应偏移多少个字节,所以需要告诉编译器i*elemSize;二是编译器无法理解void*如何进行指针算术运算,也就是必须告诉编译器,base是char*类型的(甚至unsigned long类型也可以,只是char*更为常用),将void*强制转换为char*。对这种为了通用型而传入void*的技巧,Jerry把它称为“void star hack”:
Jerry: This is still point arithmetic, okay, and it’s against a void *, so the compiler doesn’t care or most compilers don’t care that you know that this numerically this should work out. I’m trying to manually synthesize the address of the i element but from an address standpoint it’s like, “No, I don’t care whether you are being smart over here. You are telling me to do point arithmetic against a type less pointer so I don’t know how to interpret this and I’m not just going to assume that you are doing normal math here.” So the trick is to do this. It’s totally a hack, but it’s a hack that is used everyday in generic C programming. I want to base and I want to cast it to be a char* and after I do that add i times element size, it is called the void * hack, at least in 107 circles it is. That’s one full expression.
在搜索数组指定元素的基础上,Jerry进一步介绍调用通用版本(搜索)函数实现搜索字符串数组中指定字符串。具体内容在CS107-Lecture5.
Program. 8. the generic version of L search (fun version)
void *lsearch(void *key, void *base, int n, int elemSize, void (*cmpfn(void *, void *)))
{
return NULL;
}













 727
727











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









