







1介绍
Hadoop是一个强大的架构,用于自动并行化的计算任务。不幸的是某些编程对于它是个挑战。Hadoop程序让人难以理解和调试。有一种方法可以在开发人员的机器上本地运行一个简化版的Hadoop集群使之更容易一些。本教程描述如何设置这样一个集群运Windows平台上。它还描述了如何使用Eclipse集成这个集群,一个主要的Java开发环境。
2.安装前的准备
在我们开始之前,要确保以下组件安装在了你的机器上。
l Java 1.7.0_17
l Eclipse-SDK-4.2.2
注:本教程测试环境是Hadoop1.0.4版本,如果你使用的是其他版本可以酌情去安装
为了确保不出现问题,建议都使用最新版本,我这两个版本都是最新下载的。
2.1 安装Cygwin
安装完预安装软件后,下一步就是安装Cygwin环境。Cygwin是一个组从Unix上移植到Windows的包。因为Hadoop都是写在Unix平台上的,所以用Cygwin提供Hadoop的运行环境。
安装cygwin环境有以下步骤:
1) 首先从http://www.cygwin.com网站下载所需的安装文件
2) 点击下载文件,你会看到如下的截图-本教程版本为1.7.17-1版本
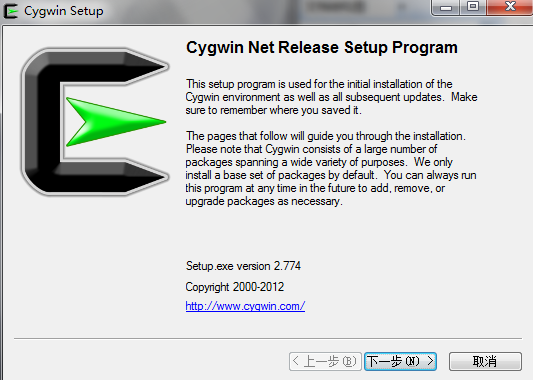
CygwinInstaller
3) 当你看到上面的截图的时候,点击下一步按钮你会看到屏幕上有选择包的界面。要确保你选择了net category里的”openssh”。这个包是确保Hadoop集群正常运作和Eclipse的插件。
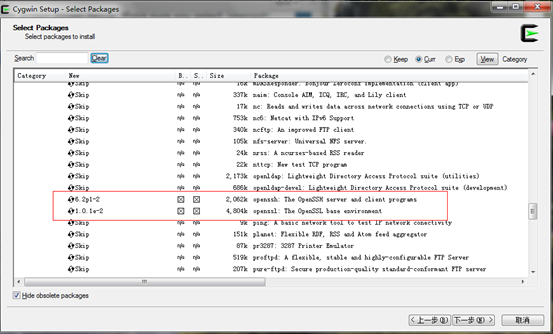
4)你选择完这些包后,点击下一步,完成安装。
3.设置环境变量
下一步是设置路径环境变量,以至于Eclipse IDE可以访问Cygwin命令。
设置环境变量需要以下步骤:
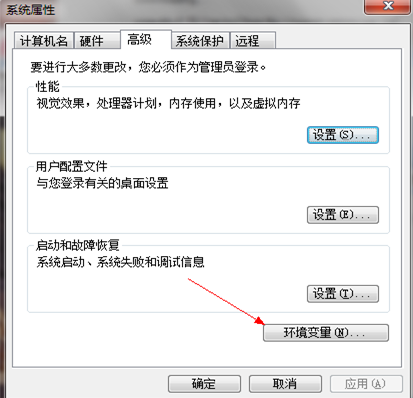
1) 我的计算机右键->属性
2)当你看到这个属性对话框,点击环境变量按钮如下所示
3)当环境变量对话框出现时,单击路径变量位于系统变量栏,然后单击Edit按钮。
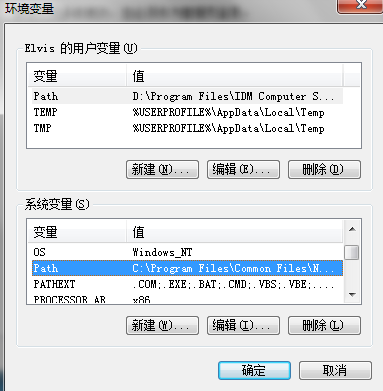
4)当编辑对话框在Path末尾添加以下文本
$ ;d:\cygwin\bin;d:\cygwin\usr\sbin
注:这个路径要根据你cygwin安装到那个目录
5)OK!!!
4 设置SSH守护进程
两个Hadoop的脚本和Eclipse的插件需要无密码的SSH来操作。本节描述了在Cygwin环境如何设置。
4.1 配置ssh
Xp下:
1)打开Cygwin命令
2)执行如下命令
$ ssh-host-config
3) when asked “Shouldprivilege separation be used”, answer yes.
4) When asked “new local account 'sshd'”, answer yes.
5) When asked “(Say "no" if it is already installed as a service)”,answeryes.
6) When asked Enter”the valueof CYGWIN for the daemon”, enter ntsec.
7)When asked “Do you want to use a differentname?”,answeryes.
8)输入密码
9)下面是一个示例会话的命令。
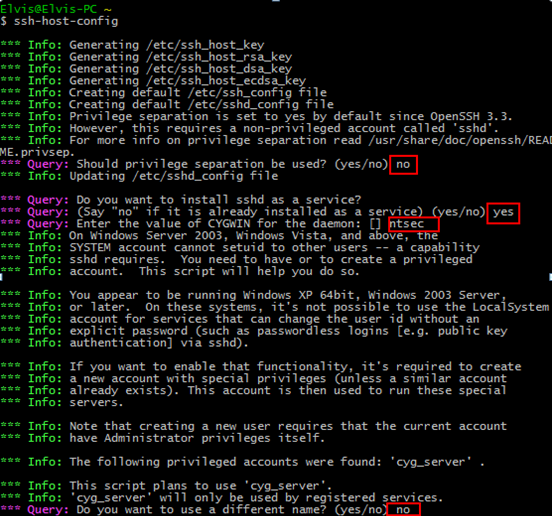

4.2 开启ssh服务
第一种方法:直接输入命令
$ net start sshd 或者 cygrunsrv –S sshd
第二种方法:图形化操作
1)在你的桌面或者开始菜单里找到”我的计算机”,然后鼠标右键选择管理。
2)在左边的面板展开服务和应用程序,然后选择服务选项。
3)找到CYGWIN sshd 选项,然后鼠标右键
4)在菜单栏点击开启。

Win7下比较麻烦:
如果win7也按照跟xp一样的安装,就算你运行cygwin以管理员权限运行,到最后估计一样会报错,反正我这是这样子的,服务可以起来,但在最终密钥什么的都配置完成后执行会报:
Elvis@Elvis-PC ~
$ssh localhost
connection closed by ::1
后来针对这个问题我找了N多资料,主要是E文,难为我了,其中有官网的FQA里的文章还有很多国外的博客吧!具体连接我也搞乱了,就不贴出来了,根据几篇资料方法总结如下:
1) 如果你安装了SSH(估计很多都安装了然后发现有错误),可以按以下命令卸载:
$net stop sshd $ cygrunsrv-R sshd $net user sshd /DELETE # See note below $ rm-R /etc/ssh* $mkpasswd -cl > /etc/passwd $mkgroup --local > /etc/group
2) 决定一个用来运行sshd进程的用户,相信使用win7的同学肯定都至少会有一个非Administror用户,我的环境现在就是平时都使用Elvis用户具有管理员权限。而下一步需要执行的命令是必须要Administrator才有权利执行的,而管理员用户一般都是被禁的,具体怎么开启请看我博客里的一篇帖子:
http://blog.csdn.net/elvis_dataguru/article/details/8739987
3) 使用管理员用户执行以下命令来查看用户现在所具有权限(或者说叫许可?)
$ editrights -l -u Elvis
4) 估计大家上述命令执行后肯定没有我们现在所需要的权限,执行以下命令来增加吧!
$ editrights.exe -a SeAssignPrimaryTokenPrivilege -u Elvis
$ editrights.exe -a SeCreateTokenPrivilege -u Elvis
$ editrights.exe -a SeTcbPrivilege -u Elvis
$ editrights.exe -a SeServiceLogonRight -u Elvis5)做完这些后,可以注销进入Elvis用户下继续操作,而后面的操作动作与前面xp下安装过程一样了,就不在详述了。
4.3 建立权限密钥
Eclipse插件和Hadoop的脚本都需要通过权限密钥ssh权限来执行而不用密码了。以下步骤就是描述怎么建立权限密钥。
1) 打开cygwin终端
2) 执行以下命令生成密钥
$ ssh-keygen
3) 当提示输入文件名等直接ENTER接受默认值
4) 命令完成后生成密钥,输入以下命令到.ssh目录
$ cd ~/.ssh
5) 执行以下命令查看密钥是否真的生成
$ ls -l
你应该能看到两个文件id_rsa.pub和id_rsa,看生成日期是最近生成的。这些文件中包含权限密钥。
6) 执行以下命令注册到新的authorization_keys文件中。
$ cat id_rsa.pub >> authorized_keys
7) 现在输入以下命令验证密钥是否正确
$ ssh lcoalhost
因为它是一个新的ssh安装,你将会被警告,主机无法确认你是否真的想连接。输入YES并且按ENTER。你会看到Cygwin在一次执行,那意味着你成功连接了。
8)现在再次执行下面命令:
$ ssh lcoalhost


Setting upauthorization keys
5.下载,复制和解压Hadoop
1)下载hadoop 1.0.4并且放到你指定的文件夹里比如我的放在了D:\java。
2)打开Cygwin
3)执行以下命令
$ cd4)执行下面命令直接在windows上以窗口形式打开home目录
$ explorer .
5) 把hadoop安装文件copy到你的Home目录下。
6. 解压Hadoop安装包
解压安装包有以下步骤:
1) 打开一个新的Cygwin
2) 执行以下命令
$ tar –zvxf hadoop-1.0.4.tar.gz3) 解压完后,执行以下命令
$ ls -l这个命令列出home目录下的内容。你应该能看一个新生成的文件hadoop-1.0.4
4)下一步执行以下命令:
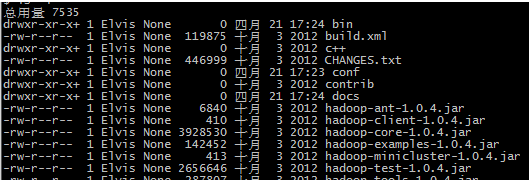
$ cd hadoop-1.0.4 $ ls -l
如果你与下面相似的信息,就说明你解压成功了,可以进行下一步
7. 配置Hadoop
1)开启一个Cygwin窗口并且执行以下命令:
$ cd hadoop-1.0.4
$ cd conf
$ explorer .2) 最后一个命令打开了Explorer窗体进入到conf文件夹
3)配置hadoop-env.sh文件
export JAVA_HOME=/cygdrive/c/Progra~1/Java/jdk1.7.0_024)然后使用编辑软甲打开,我就用UE了,也可以使用eclipse来打开,主要是编辑core-site.xml、mapred-site.xml和hdfs-site.xml
5)在3个文件中<configuration>和</configuration>里插入以下内容
| core-site.xml <configuration> <property> <name>fs.default.name</name> <value>hdfs://localhost:9000</value> </property> </configuration> mapred-site.xml <configuration> <property> <name>mapred.job.tracker</name> <value>localhost:9001</value> </property> </configuration> hdfs-site.xml <property> <name>dfs.http.address</name> <value>localhost:50070</value> </property> <property> <name>dfs.name.dir</name> <value>/usr/local/hadoop/namenode</value> </property> <property> <name>dfs.data.dir</name> <value>/usr/local/hadoop/data</value> </property> <property> <name>dfs.replication</name> <value>1</value> 注:在目录/usr/local目录下创建一个hadoop文件夹,这个是根据你前面配置中制定的namenode和datanode而定。 还有就是localhost最好直接写成ip地址,我写的是电脑本机的ip:10.60.115.150 |
8.格式化namenode
1)打开Cygwin,执行以下命令
$ cd hadoop-1.0.4
$ mkdir logs
$ bin/hadoop namenode -format2) 最后一个命令产生的输出
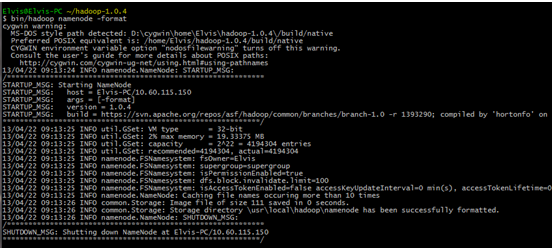
现在文件系统已经创建,可以继续下一步工作。
9.安装Hadoop插件
1)通过以下命令,打开eclipse-plugin文件夹
$ cd hadoop-1.0.4
$ cd contrib.
$ cd eclipse-plugin
$ explorer .2) 然后把里面的hadoop-x.x.x-eclipse-plugin.jar拷贝到eclipse安装包里的plugin目录里
注:但本次教程的hadoop-1.0.4里面没有,所以我从网上找到了这个jar直接拷贝到eclipse内plugin目录里
3) 启动eclipse
4) 打开Window->OpenPerspective->other->Map/Reduce
然后在打开Window->Show View->Other 搜索mapreduce视图
5)如图IDE
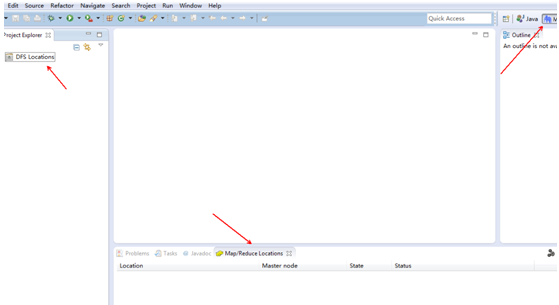
6) 配置Hadoop的安装目录
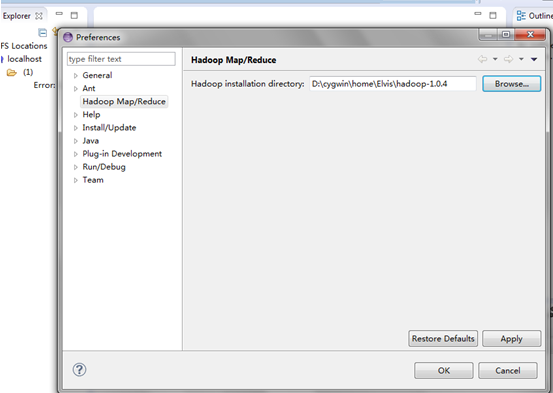
现在Hadoop安装和配置完了,还有eclipse的插件,下一步拿一个小Project测试下。
10.测试集群
10.1开启本地hadoop集群
1)开启5个Cygwin,然后分别执行以下命令:
Window1:
$ cd hadoop-1.0.4
$ bin/hadoop namenode
Window2:
$ bin/hadoop secondarynamenode
Window3:
$bin/hadoop jobtracker
Window4:
$bin/hadoop datanode
Window5:
$bin/hadoop tasktracker
或者:直接输入以下命令
$bin/start-all.sh这个时候进群起来了,进行下一步。
注:这个时候前3个窗口可能是一直卡在某个地方,这个是正常现象无需担心,也可以在后面加上”&”使进程在后台运行,不在详述,感兴趣的同学可以自行查阅Linux关于”&”的用法
10.2 在Eclipse建立本地Hadoop
1)在切换到Map /Reduce的角度来看,选择Map / Reduce位置选项卡下面的Eclipse环境。然后单击空白空间右键选项卡并选择“新Hadoop位置....“从上下文菜单。您应该会看到一个对话框所示类似。
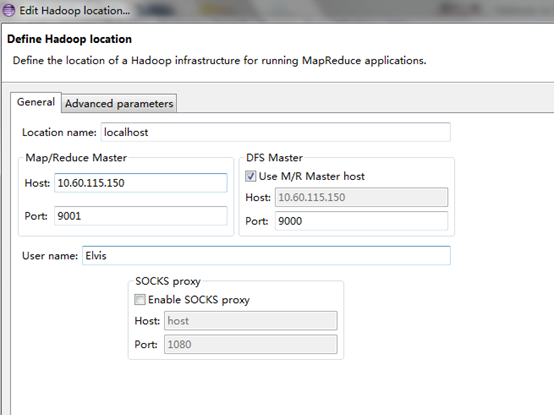
3) 填入项目,以下所示:
Location Name – localhost --当然这个自己可以随便起名
Map/Reduce Master --一定要与mapred-site.xml里面一致
Host –10.60.115.150
Port – 9001
DFS Master
Check "Use M/R Master Host" --要与core-site.xml里一致
Port -- 9000
User name – Elvis
然后点击完成。
4) 然后你会看到IDE
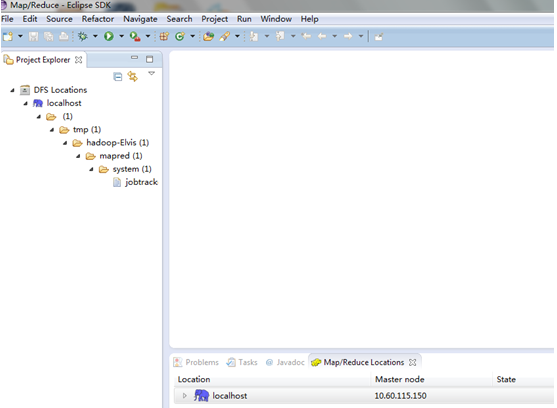
5) 可以通过eclipse直接copyfromlocal数据。
6) 到这里,在Win下的Hadoop伪分布式集群构建完毕了+Eclipse的配置
10.3 hello测试
用Hadoop自带的WordCount实例可以统计一批文本文件中各单词出现的次数。
1) 首先先做以下动作
$ mkdir input
$ cd input
$ echo “hello world” > test1.txt
$ echo “hello hadoop”> test2.txt
$ cat test1.txt #可以使用这个命令查看文件内容
$ bin/hadoop dfs –put ../input in
$ bin/hadoop dfs –ls in
$ bin/hadoop jar hadoop-examples-1.0.4.jar wordcount in out
$ bin/hadoop dfs –cat out/*最后,尽管这种在win下的开发生产环境不会应用,但自己在实验机中做些开发测试还是蛮不错的选择的,希望对同学们有所帮助。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









