







写了一个简单的头条动态页面爬取代码。

比如想获取这些图片或者title,但是直接open(‘https://www.toutiao.com/search/?keyword=%E7%8C%AB'),什么内容都没有,在chrome的开发者模式中可以看到,当页面有交互行为JS触发调度,JS发出一个http请求,此时找到这个请求即可,我是在network里找到的,有点难找,但是免得下其他插件了。此时也可以得到请求headers也可以用上。

在Response可以看到返回的是一个json格式,解析该格式即可。

这个json格式里面还有一些视频、百科介绍,不知道是展现在哪里的,没有细看,代码里只解析了我想要的内容。
代码给出:
class ToutiaoSearch(object):
def __init__(self, search_word='猫'):
self.search_word = search_word
self.headers = {
'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.100 Safari/537.36',
'X-Requested-With': 'XMLHttpRequest',
'Host': 'www.toutiao.com',
'Accept': 'application/json, text/javascript'
}
def _crawl_data(self, offset):
url = 'https://www.toutiao.com/search_content/?offset={0}&format=json&keyword={1}&autoload=true&count=20&cur_tab=1&from=search_tab'.format(offset, self.search_word)
print(url)
try:
rp = requests.get(url, timeout=10, headers=self.headers)
content = rp.text
except Exception as e:
content = None
print('craw exception: '+str(e))
return content
def _parse_data(self, content):
ret = []
if content is None:
return None
try:
data_list = json.loads(content)['data'][-10:]
# print(data_list)
for item in data_list:
if item.get('cell_type'):
continue
# print(item)
item = item
result = {'article_title':item['title']}
image_urls = []
for url in item['image_list']:
image_urls.append('http:'+url['url'])
result['image_urls'] = image_urls
ret.append(result)
except Exception as e:
print('analyse Exception: ',str(e))
return ret
def start(self):
offset = 0
ret = []
while offset<=200:
page_list = self._parse_data(self._crawl_data(offset))
if page_list is None or len(page_list)<=0:
break
try:
for page in page_list:
ret.append([page['article_title'],page['image_urls']])
except:
continue
finally:
offset+=20
for i in ret:
print(i[0])
print(i[1])
print(ToutiaoSearch('猫').start())结果为:

百度搜索下拉框也是JS发出请求,会发出很多请求,大家自己找找。
百度下拉框,想获得里面的内容的话,就得找到JS的http请求。
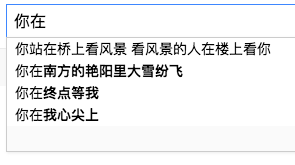
打开开发者模式看到:

可以看到同样返回一个json格式的字符串。

class GetBaiduPulldown(object):
def __init__(self, search_word):
self.search_word = search_word
self.header = {
'Referer': 'https://www.baidu.com/',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36',
'Accept-Encoding' : 'Accept-Encoding: gzip, deflate, br',
'Accept-Language' : 'zh-CN,zh;q=0.9',
'Accept': 'application/json, text/javascript',
'Host': 'sp0.baidu.com'
}
def crawl_data(self):
url = "https://sp0.baidu.com/5a1Fazu8AA54nxGko9WTAnF6hhy/su?wd={}&json=1&p=3&sid=1459_21118_18559_27400_26350_27244_20719&req=2&csor=2&pwd=ni%27hao&cb=jQuery1102011480469766011803_1542697588472&_=1542697588482".format(self.search_word)
try:
content = requests.get(url, headers=self.header).text
except Exception as e:
content = None
print('request Exception: ',e)
return content
def start(self):
content = self.crawl_data()
ret = dict()
if not content:
return ret
try:
values = json.loads(re.findall('jQuery\d+_\d+\((.*)\);', content)[0])['s']
# key = self.search_word
ret[self.search_word] = values
except Exception as e:
print('parse Exception: ', e)
return ret
if __name__ == '__main__':
print(GetBaiduPulldown('在哪').start())
结果为:

这种做法比较简单,可以试试。















 2283
2283











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









