






记录一下在python音频读取以及进行FFT变换时遇到的问题。在进行音频读取并进行FFT变换时发现一个奇怪的问题,我有一个音频1000HZ.wav,用wave和librosa.load读取得到的频率结果不一样。
import librosa
import numpy as np
import wave
import pyaudio
import matplotlib.pyplot as plt
import librosa.display
def librosa_fft(filename):
#读取声音文件
x, sr = librosa.load(filename, sr=None)
print(sr)
num = 1
remainder = x.shape[0] % num
s = slice(remainder, x.shape[0])
x = x[s]
print(x.shape[0])
Fs = sr #采样频率
T = 1/Fs #采样周期,只相邻两数据点的时间间隔
freq_list = []
brand_length = int(x.shape[0] / num)
print('brand_length:%s' % brand_length)
#将数据分割成N份
for i in range(0, num):
brand_s = slice(i * brand_length, (i + 1) * brand_length)
brand_data = x[brand_s]
#对数据做快速傅里叶变换
ffts = np.fft.fft(brand_data)
#取绝对值
pows = np.abs(ffts)
#归一化处理
pows = pows * 2 / brand_length
#取得频率范围
freqs = np.fft.fftfreq(brand_length, T)
# 频率为0的重复累积了两次,需要减半处理
pows[freqs == 0] = pows[freqs == 0] / 2 # 频率为0的重复累积了两次,需要减半处理
#pows = pows[freqs >= 0] # 取出对应的正频率的幅值
# 取出对应的正频率的幅值
freqs = freqs[freqs >= 0]
# 常规显示采样频率一半的频谱
d = int(len(pows) / 2)
#print(d)
# 仅显示频率在6000以下的频谱
while freqs[d-1] > 6000:
d -= 10
#print(d)
#取实数
pows_real = [n.real for n in pows[:d - 1]]
max_pow = max(pows_real)
id = pows_real.index(max_pow) # 最大值索引
freq_list.append(freqs[id])
plt.plot(freqs[:d - 1], pows_real[:d - 1], 'r')
plt.show()
#plt.plot(freqs[freqs >= 0], pows[freqs >= 0])
#plt.show()
print(freq_list)
average = np.mean(freq_list)
result_list = [n >= average for n in freq_list]
return result_list
def load_file(file_path, oraginal=True):
# 只读方式打开WAV文件
wf = wave.open(file_path, 'rb')
nframes = wf.getnframes()
framerate = wf.getframerate()
print('Samplerate is:%s' % framerate)
# 读取完整的帧数据到str_data中,这是一个string类型的数据
str_data = wf.readframes(nframes)
wf.close()
# 将波形数据转换成数组
wave_data = np.frombuffer(str_data, dtype=np.int16).astype(np.float32)
# Scale the audio
scale = 1./float(1 << ((8 * wf.getsampwidth()) - 1)) # from librosa
wave_data *= scale
#wave_data = np.fromstring(str_data, dtype=np.short)
#wave_data = np.frombuffer(str_data, dtype=np.short)
# 将wave_data数组改为2列,行数自动匹配
wave_data.shape = -1,1
# 将数组转置
wave_data = wave_data.T
return plot_frequencydomain(wave_data,framerate)
def plot_frequencydomain(wave_data,framerate):
# 采样点数,修改采样点数和起始位置进行不同位置和长度的音频波形分析
N =len(wave_data[0])
start = 0 # 开始采样位置
df = framerate / (N - 1) # 分辨率
freq = [df * n for n in range(0, N)] # N个元素
wave_data2 = wave_data[0][start:start + N]
c =np.fft.fft(wave_data2) * 2 / N
# 常规显示采样频率一半的频谱
d = int(len(c) / 2)
freqs = [fre for fre in freq]
# 仅显示频率在6000以下的频谱
while freqs[d] > 6000:
d -= 10
plt.plot(freqs[:d - 1], abs(c[:d - 1]), 'r')
plt.show()
if __name__ == '__main__':
load_file("1000HZ.wav")
list1 = librosa_fft("1000HZ.wav")使用wave读取,即调用代码中的 load_file("1000HZ.wav")得到结果:
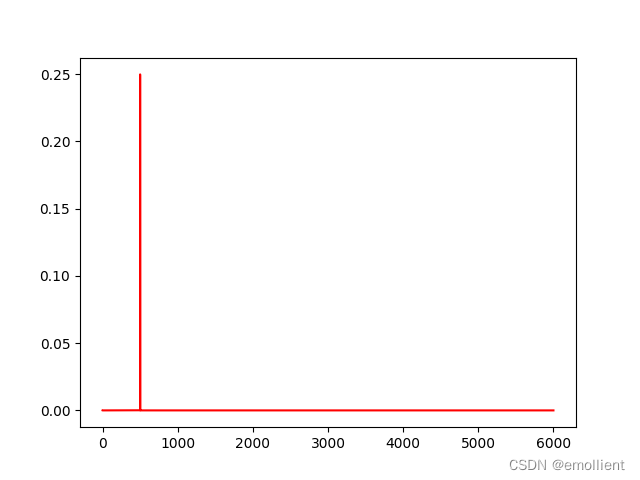
使用librosa读取,即调用代码中的 list1 = librosa_fft("1000HZ.wav")得到结果:
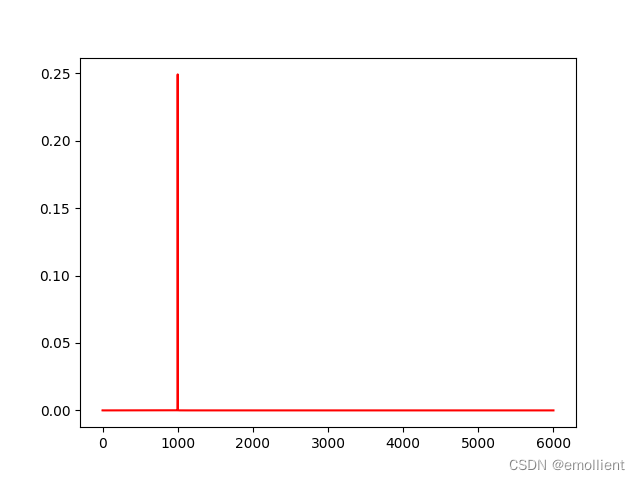
发现频率相差两倍,不知道为什么?
然后又找到另一个音频1_16PCM.wav 分别用两种方法读取,得到的频率结果又相同
还没搞清楚为什么会有这样的区别
















 826
826











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











